









提高QPS方法浅谈
最近看了一篇博文,题目是 《天池中间件大赛dubboMesh优化总结(qps从1000到6850)》,点击链接,对其中笔者优化RPC链路,提高QPS的过程非常感兴趣,所以就想写一篇这样的文章。主要就以下几点谈谈如何提高QPS:
- QPS含义
- 高QPS的核心思想
- 常见手段
QPS含义
Queries per second (QPS) is a common measure of the amount of search traffic an information retrieval system, such as a search engine or a database, receives during one second. —— [ 维基百科 ]
简单的来说,就是每秒能够响应的请求,并以此作为系统处理能力的标准。一般QPS的获取,正如其定义一样,需要通过压测工具进行实际的压力测试计算,这是从结果的角度来看。但是换个思路,特别是我们需要提高QPS值的时候,我们就要思考怎么样提高,影响QPS的因素到底是什么,能否从数学上有一个比较准确的定义和描述,这个时候,我们的思路就会被打开。
QPS,顾名思义,从描述我们可以下一个基本的定义:
QPS = 1000ms/执行RT,当然,这是单核单线程QPS。
扩充到多线程:
QPS = 1000ms/执行RT*线程数
其中
执行RT=thread avg waitTime + thread avg executeTime
至于线程数,选什么值好呢?一般来说,使用线程直接目的就是最大化CPU资源,所以 在一个执行RT内,我们理想可以并行的线程数是
n = 执行RT/thread avg executeTime=1+waitTime/executeTime
但是往往存在上下文线程开销、同线程之间资源切换损耗,并且我们CPU的利用率并不是100%。所以假设我们把线程开销等等计算到 executeTime中,定义cpu%表示cpu利用率。
最后,我们的QPS的定性描述
QPS= 1000ms/执行RT*(执行RT/thread avg executeTime) *cpu%
= (1000ms/thread avg executeTime) * cpu%
所以,我们要提高一个服务系统的QPS,需要降低这个链路当中 executeTime以及提高cpu利用率。
高QPS的核心思想
继续上文的结论,要提高一个服务的QPS,我们需要实现两个指标:
降低这个链路的 executeTime,以及提高cpu利用率。
降低链路的executeTime 自然而然,我们把一个链路的同步调用,分成好几段,原来需要经过三步才能拿到的返回结果,我们只需要经过一步就能拿到结果,那么自然我们的性能就会提高很多。
至于提高cpu利用率。说到底其实就是一点,不要在计算的时候,老进行什么IO、网络读写,要计算就好好的计算,专人负责专事。
把这两点归纳到一起,其实际就是一种SEDA思想
SEDA
SEDA,即将原先由一个线程完成的任务,分割为相对独立的多个阶段。每个阶段由专用的一组线程负责执行,阶段之间用队列交互。
将SEDA思想融入的比较完美的地方,首先想要的便是 一直被大家所推崇的高性能IO通信 netty, 使用的异步非阻塞的Reactor线程模型
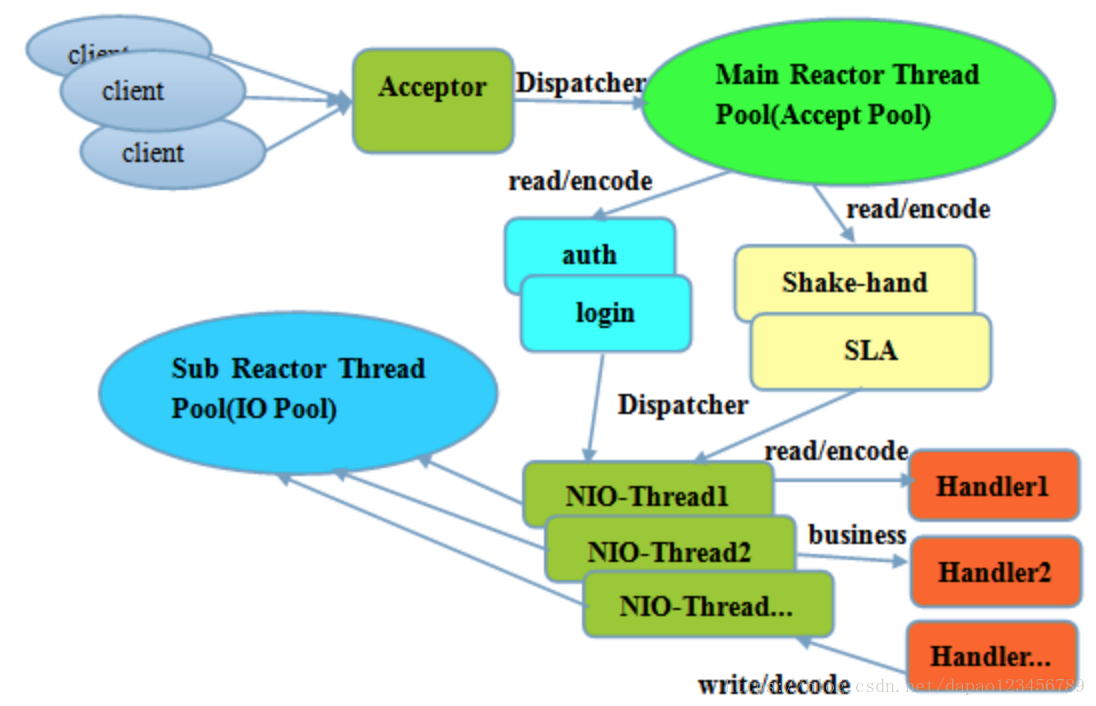
如图使用多组不同的线程池,
1.第一个NIO线程池,Acceptor pool接受dispatcher来的客户端连接,完成auth、login、以及握手。
2.第二个NIO线程池,接替前一个结果,完成后续的IO读写
这样,系统的每一个比较耗时的环节,都有一组人在并行处理,环节之间通过NIO非阻塞通信,极大降低了等待时间,提高了利用率。所以在相同的时间内,使用SEDA思想设计,将能响应更多的请求。
disruptor无锁设计
很快,使用SEDA,我们就会发现一个问题,不同的stage之间通过队列来交互,并且在多线程环境下,入队与出队必然存在锁控制,并且队列为了起到缓存的作用,那么总会存在一定的数据,队列持有一定的数据,从全局的角度来看,这是一个cpu并没有被使用的场景,因为数据被缓冲在队列里。另外当消费者速度较快的情形下,可能出现 多个不同的消费者相互竞争同类型的资源。所以disruptor 提出了一种无锁设计,干掉队列,在同样情形下,把能把各个stage之间联系的队列去掉,用一种统一的数据结构来代替,统一的数据结构,可以使用统一的线程组,这样系统的压力也比较均匀。
disruptor的研究与解读还需要慢慢品味,此处就不予以展开。
常见手段
1.异步化
即非阻塞,化繁为简,拿到你需要处理的资源后尽快回复。适用于事务处理场景,且无需对上游返回数据场景。fature callback这种模式,从数据角度来说,是一种伪异步。
2.无锁设计
本质上是要降低锁冲突,而无锁设计最佳的体现就在于MVVC思想,避免或者使用互斥资源,所以基于数据版本的乐观锁 有效的减少了互斥资源的范围,优点不言而喻。
3.batch处理
批量查询、批量commit,基本上操作慢速设备或者不能并行化的对象或者资源时,使用batch 永远是最好的手段。
4.副本设计
使用cache、静态化等手段,其核心思想在于 提前将结果准备好,实现的难点数据的更新。

















 1240
1240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









