






代码结构:
1. utils
dice_scores.py
这里介绍一下Metric评价指标——Dice 与损失函数——Dice Loss:
Dice是医学图像比赛中使用频率最高的度量指标,它是一种集合相似度度量指标,通常用于计算两个样本的相似度,值阈为[0, 1]。在医学图像中经常用于图像分割,分割的最好结果是1,最差时候结果为0.
Dice系数计算公式如下:
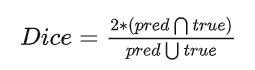
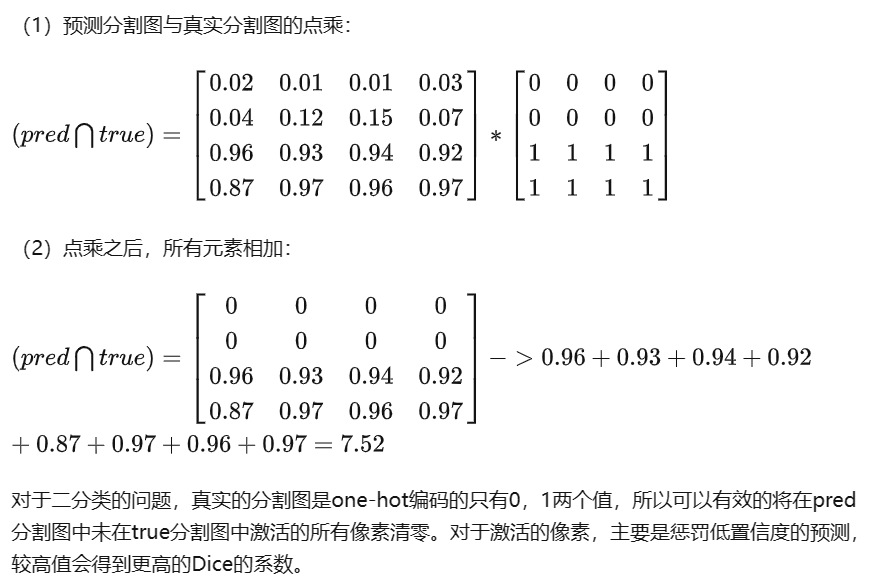
对于二分类的问题,真实的分割图是one-hot编码的只有0,1两个值,所以可以有效的将在pred分割图中未在true分割图中激活的所有像素清零。对于激活的像素,主要是惩罚低置信度的预测,较高值会得到更高的Dice的系数。
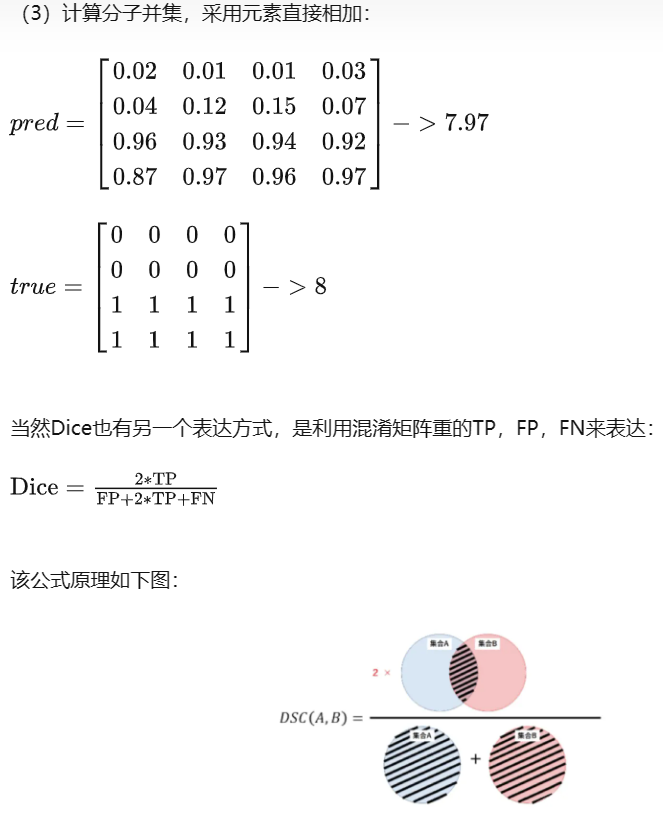

Dice Loss 存在的问题:
训练误差曲线非常混乱,很难看出关于收敛的信息。尽管可以检查在验证集上的误差来避开此问题。
def dice_coeff(input: Tensor, target: Tensor, reduce_batch_first: bool = False, epsilon: float = 1e-6):
# Average of Dice coefficient for all batches, or for a single mask
assert input.size() == target.size()
assert input.dim() == 3 or not reduce_batch_first
sum_dim = (-1, -2) if input.dim() == 2 or not reduce_batch_first else (-1, -2, -3)
inter = 2 * (input * target).sum(dim=sum_dim)
sets_sum = input.sum(dim=sum_dim) + target.sum(dim=sum_dim)
sets_sum = torch.where(sets_sum == 0, inter, sets_sum)
dice = (inter + epsilon) / (sets_sum + epsilon)
return dice.mean()
def multiclass_dice_coeff(input: Tensor, target: Tensor, reduce_batch_first: bool = False, epsilon: float = 1e-6):
# Average of Dice coefficient for all classes
return dice_coeff(input.flatten(0, 1), target.flatten(0, 1), reduce_batch_first, epsilon)
def dice_loss(input: Tensor, target: Tensor, multiclass: bool = False):
# Dice loss (objective to minimize) between 0 and 1
fn = multiclass_dice_coeff if multiclass else dice_coeff
return 1 - fn(input, target, reduce_batch_first=True)
data_loading.py
CarvanaDataset继承和重写BasicDataset类。CarvanaDataset 类用于创建一个特定类型的数据集,用于图像分割任务。
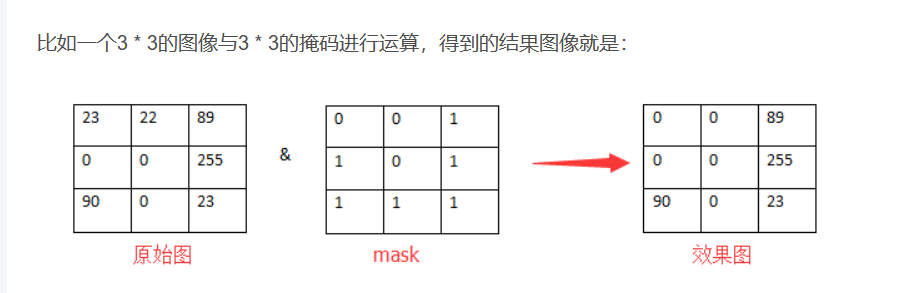
讲一下mask掩码,比如要对一幅图进行抠图操作,这就要用到Mask了,那么以抠图为例,解释Mask在里面的作用。该程序的功能就是抠出指定区域。
mask就是位图,来选择哪个像素允许拷贝,哪个像素不允许拷贝。如果mask像素的值是非0的,我就拷贝它,否则不拷贝。因为我们上面得到的mask中,感兴趣的区域是白色的,表明感兴趣区域的像素都是非0,而非感兴趣区域都是黑色,表明那些区域的像素都是0。一旦原图与mask图进行与运算后,得到的结果图只留下原始图感兴趣区域的图像了

utils.py
def plot_img_and_mask(img, mask):
classes = mask.max() + 1
fig, ax = plt.subplots(1, classes + 1)
ax[0].set_title('Input image')
ax[0].imshow(img)
for i in range(classes):
ax[i + 1].set_title(f'Mask (class {i + 1})')
ax[i + 1].imshow(mask == i)
plt.xticks([]), plt.yticks([])
plt.show()
用于可视化输入图像和对应的掩码图像。该函数可以帮助你查看图像分割任务中的输入图像和预测的掩码图像
2. unet
unet_model.py

class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=False):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = (DoubleConv(n_channels, 64))
self.down1 = (Down(64, 128))
self.down2 = (Down(128, 256))
self.down3 = (Down(256, 512))
factor = 2 if bilinear else 1
self.down4 = (Down(512, 1024 // factor))
self.up1 = (Up(1024, 512 // factor, bilinear))
self.up2 = (Up(512, 256 // factor, bilinear))
self.up3 = (Up(256, 128 // factor, bilinear))
self.up4 = (Up(128, 64, bilinear))
self.outc = (OutConv(64, n_classes))
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
def use_checkpointing(self):
self.inc = torch.utils.checkpoint(self.inc)
self.down1 = torch.utils.checkpoint(self.down1)
self.down2 = torch.utils.checkpoint(self.down2)
self.down3 = torch.utils.checkpoint(self.down3)
self.down4 = torch.utils.checkpoint(self.down4)
self.up1 = torch.utils.checkpoint(self.up1)
self.up2 = torch.utils.checkpoint(self.up2)
self.up3 = torch.utils.checkpoint(self.up3)
self.up4 = torch.utils.checkpoint(self.up4)
self.outc = torch.utils.checkpoint(self.outc)
def __init__(self, n_channels, n_classes, bilinear=False):这是 UNet 类的构造函数。它接受三个参数:n_channels 表示输入图像的通道数,n_classes 表示分割的类别数。bilinear 是一个布尔值,表示是否使用双线性插值(默认为 False)。
网络模型:
self.down1 = (Down(64, 128)):
这行代码创建了一个名为 self.down1 的对象,该对象是 Down 类的一个实例。Down 类的作用是实现 U-Net 网络中的下采样操作,也被称为编码器部分。在图像分割任务中,下采样操作用于逐渐减小图像的空间尺寸,同时增加通道数,以捕捉不同尺度的特征。其中 64 是输入通道数,表示来自上一层的特征图的通道数,128 是输出通道数,表示经过下采样操作后的特征图通道数。具体的包装在unet_parts.py中
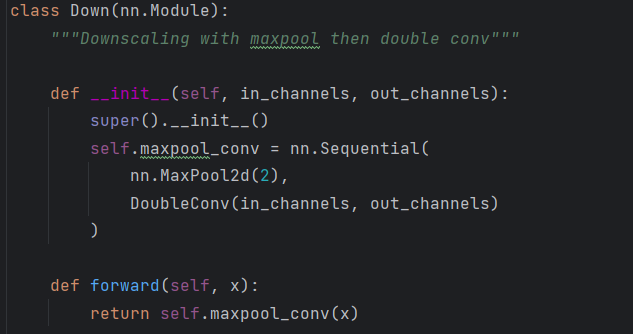
down实例的后面还有DoubleConv,所以下一层就不需要再进行DoubleConv,然后forward向前计算
另外pytorch 中 nn.Module 类中实现了 call 方法, 并在 call 方法中调用了 forward 函数。而定义模型会继承 nn.Module, 所以重载 forward 函数后, 模型会自动调用 forward 函数:


而__call__函数是在类的对象使用‘()’时被调用。此处相当于c++中重载了括号,如果c++不太熟悉也没关系,一般调用在类中定义的函数的方法是:example_class_instance.func(),如果只是使用example_class_instance(),那么这个操作就是在调用__call__这个内置方法

而nn.modules中的实例的__call__会调用实例中的forward函数
unet_parts.py
上面讲的对网络的一些封装
""" Parts of the U-Net model """
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
# if you have padding issues, see
# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
注意:
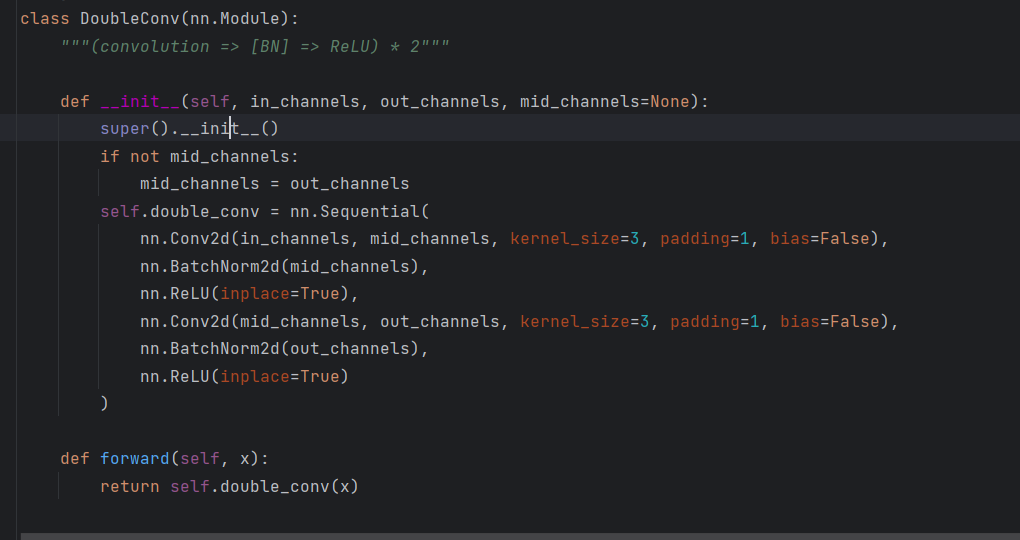
此代码中的每次卷积后加了一个BatchNorm,原论文没体现
3. hubconf.py
def unet_carvana(pretrained=False, scale=0.5):
"""
UNet model trained on the Carvana dataset ( https://www.kaggle.com/c/carvana-image-masking-challenge/data ).
Set the scale to 0.5 (50%) when predicting.
"""
net = _UNet(n_channels=3, n_classes=2, bilinear=False)
if pretrained:
if scale == 0.5:
checkpoint = 'https://github.com/milesial/Pytorch-UNet/releases/download/v3.0/unet_carvana_scale0.5_epoch2.pth'
elif scale == 1.0:
checkpoint = 'https://github.com/milesial/Pytorch-UNet/releases/download/v3.0/unet_carvana_scale1.0_epoch2.pth'
else:
raise RuntimeError('Only 0.5 and 1.0 scales are available')
state_dict = torch.hub.load_state_dict_from_url(checkpoint, progress=True)
if 'mask_values' in state_dict:
state_dict.pop('mask_values')
net.load_state_dict(state_dict)
return net
这段代码定义了一个用于加载预训练的 U-Net 模型的函数 unet_carvana,其中使用了 Carvana 数据集进行训练。这个函数接受两个参数:pretrained 表示是否使用预训练的权重,scale 表示图像的缩放比例。
4. train.py
在def train_model():下
1. Create dataset
try:
dataset = CarvanaDataset(dir_img, dir_mask, img_scale)
except (AssertionError, RuntimeError, IndexError):
dataset = BasicDataset(dir_img, dir_mask, img_scale)
2. Split into train / validation partitions
n_val = int(len(dataset) * val_percent)
n_train = len(dataset) - n_val
train_set, val_set = random_split(dataset, [n_train, n_val], generator=torch.Generator().manual_seed(0))
3. Create data loaders
loader_args = dict(batch_size=batch_size, num_workers=os.cpu_count(), pin_memory=True)
train_loader = DataLoader(train_set, shuffle=True, **loader_args)
val_loader = DataLoader(val_set, shuffle=False, drop_last=True, **loader_args)
# (Initialize logging)
experiment = wandb.init(project='U-Net', resume='allow', anonymous='must')
experiment.config.update(
dict(epochs=epochs, batch_size=batch_size, learning_rate=learning_rate,
val_percent=val_percent, save_checkpoint=save_checkpoint, img_scale=img_scale, amp=amp)
)
logging.info(f'''Starting training:
Epochs: {epochs}
Batch size: {batch_size}
Learning rate: {learning_rate}
Training size: {n_train}
Validation size: {n_val}
Checkpoints: {save_checkpoint}
Device: {device.type}
Images scaling: {img_scale}
Mixed Precision: {amp}
''')
shuffle=True 表示在每个 epoch 开始时是否对数据进行洗牌,以增加随机性
4. Set up the optimizer, the loss, the learning rate scheduler and the loss scaling for AMP
optimizer = optim.RMSprop(model.parameters(),
lr=learning_rate, weight_decay=weight_decay, momentum=momentum, foreach=True)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'max', patience=5) # goal: maximize Dice score
grad_scaler = torch.cuda.amp.GradScaler(enabled=amp)
criterion = nn.CrossEntropyLoss() if model.n_classes > 1 else nn.BCEWithLogitsLoss()
global_step = 0
RMSprop优化;交叉熵损失
-
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, ‘max’, patience=5):这里创建了一个学习率调度器,它使用了 ReduceLROnPlateau 策略。它会监测某个指标(在这里是’max’,目标是最大化 Dice 分数)的变化,当这个指标在一定轮数内不再提升时,会自动降低学习率。patience参数表示等待的轮数。
-
grad_scaler = torch.cuda.amp.GradScaler(enabled=amp):这里创建了一个 AMP的梯度缩放器 grad_scaler,用于在训练过程中应用自动混合精度技术。enabled 参数指定是否启用 AMP。
-
criterion = nn.CrossEntropyLoss() if model.n_classes > 1 else nn.BCEWithLogitsLoss():这里创建了损失函数 criterion。如果模型的类别数大于1,即多类别分割任务,使用交叉熵损失函数;如果模型只有一个类别,即二进制分割任务,使用带逻辑回归的 BCE 损失函数。
-
global_step = 0:这里设置全局步数(global step),通常用于记录训练中的步数。
5. Begin training
for epoch in range(1, epochs + 1):
model.train()
epoch_loss = 0
with tqdm(total=n_train, desc=f'Epoch {epoch}/{epochs}', unit='img') as pbar:
for batch in train_loader:
images, true_masks = batch['image'], batch['mask']
assert images.shape[1] == model.n_channels, \
f'Network has been defined with {model.n_channels} input channels, ' \
f'but loaded images have {images.shape[1]} channels. Please check that ' \
'the images are loaded correctly.'
images = images.to(device=device, dtype=torch.float32, memory_format=torch.channels_last)
true_masks = true_masks.to(device=device, dtype=torch.long)
with torch.autocast(device.type if device.type != 'mps' else 'cpu', enabled=amp):
masks_pred = model(images)
if model.n_classes == 1:
loss = criterion(masks_pred.squeeze(1), true_masks.float())
loss += dice_loss(F.sigmoid(masks_pred.squeeze(1)), true_masks.float(), multiclass=False)
else:
loss = criterion(masks_pred, true_masks)
loss += dice_loss(
F.softmax(masks_pred, dim=1).float(),
F.one_hot(true_masks, model.n_classes).permute(0, 3, 1, 2).float(),
multiclass=True
)
optimizer.zero_grad(set_to_none=True)
grad_scaler.scale(loss).backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), gradient_clipping)
grad_scaler.step(optimizer)
grad_scaler.update()
pbar.update(images.shape[0])
global_step += 1
epoch_loss += loss.item()
experiment.log({
'train loss': loss.item(),
'step': global_step,
'epoch': epoch
})
pbar.set_postfix(**{'loss (batch)': loss.item()})
# Evaluation round
division_step = (n_train // (5 * batch_size))
if division_step > 0:
if global_step % division_step == 0:
histograms = {}
for tag, value in model.named_parameters():
tag = tag.replace('/', '.')
if not (torch.isinf(value) | torch.isnan(value)).any():
histograms['Weights/' + tag] = wandb.Histogram(value.data.cpu())
if not (torch.isinf(value.grad) | torch.isnan(value.grad)).any():
histograms['Gradients/' + tag] = wandb.Histogram(value.grad.data.cpu())
val_score = evaluate(model, val_loader, device, amp)
scheduler.step(val_score)
logging.info('Validation Dice score: {}'.format(val_score))
try:
experiment.log({
'learning rate': optimizer.param_groups[0]['lr'],
'validation Dice': val_score,
'images': wandb.Image(images[0].cpu()),
'masks': {
'true': wandb.Image(true_masks[0].float().cpu()),
'pred': wandb.Image(masks_pred.argmax(dim=1)[0].float().cpu()),
},
'step': global_step,
'epoch': epoch,
**histograms
})
except:
pass
if save_checkpoint:
Path(dir_checkpoint).mkdir(parents=True, exist_ok=True)
state_dict = model.state_dict()
state_dict['mask_values'] = dataset.mask_values
torch.save(state_dict, str(dir_checkpoint / 'checkpoint_epoch{}.pth'.format(epoch)))
logging.info(f'Checkpoint {epoch} saved!')
- model.train():将模型设置为训练模式,以确保梯度计算和参数更新。
- epoch_loss = 0:初始化每个 epoch 的损失为 0。
- for batch in train_loader::遍历训练数据加载器中的每个批次。
- for batch in train_loader:images, true_masks = batch[‘image’], batch[‘mask’] 提取输入图像和真实掩膜(或标签):images 是输入图像,true_masks 是真实掩码。
- assert images.shape[1] == model.n_channels:确保加载的图像通道数与模型定义的输入通道数一致。
- 将数据移动到设备并进行类型转换:将图像数据和掩膜数据移动到指定的设备(通常是 GPU),并将数据类型转换为 torch.float32和 torch.long。
- with torch.autocast(device.type if device.type != ‘mps’ else ‘cpu’, enabled=amp)::在自动混合精度(AMP)的上下文中运行。AMP 可以自动混合精度地计算和更新梯度,以提高训练效率。
- 计算损失函数:根据模型的输出和
真实掩码(相当于label标签)计算损失。对于多类别分割任务和二进制分割任务,损失函数的计算方式有所不同。对于二分类使用sigmoid激活函数,多分类使用
softmax激活函数
Sigmoid =多标签分类问题=多个正确答案=非独占输出(例如胸部X光检查、住院)
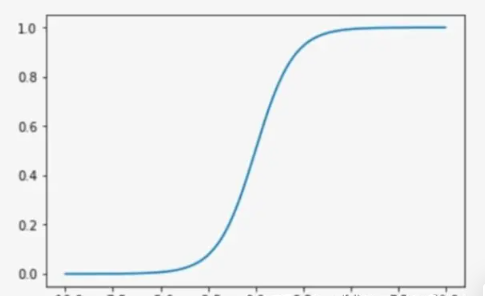
Softmax =多类别分类问题=只有一个正确答案=互斥输出(例如手写数字,鸢尾花)
9. optimizer.zero_grad(set_to_none=True):将优化器的梯度缓冲区清零,使用set_to_none=True
可以更有效地释放内存。
10. grad_scaler.scale(loss).backward():将损失进行反向传播,并自动缩放梯度。
11. torch.nn.utils.clip_grad_norm_(model.parameters(),gradient_clipping):对梯度进行裁剪,以防止梯度爆炸。
12. grad_scaler.step(optimizer) 这一步是在 AMP 上下文中对梯度进行缩放并执行优化器的 step 操作,用于更新模型的参数。梯度缩放器将缩放后的梯度应用于优化器,并进行参数更新。
13. grad_scaler.update():这一步用于更新梯度缩放器的状态,以便在下一次迭代中重新计算缩放比例。这样做可以确保在不同迭代中使用适当的梯度缩放比例。
14. pbar.update(images.shape[0]):更新进度条,表示已处理了当前批次的样本数。
15. global_step += 1:更新全局步数,用于记录训练过程中的总步数。
16. epoch_loss += loss.item():累积当前 epoch 的损失值,用于计算平均损失
17. Evaluation round
division_step = (n_train // (5 * batch_size)):计算在训练中每间隔多少个步骤进行一次模型评估和学习率调整。这个值是基于训练样本数量、批次大小和评估频率计算得出的。
if division_step > 0: 如果 division_step 大于 0,表示需要执行模型评估和学习率调整。
if global_step % division_step == 0: 如果当前全局步数是 division_step 的倍数,执行以下操作:
- 创建一个空的 histograms 字典,用于存储模型参数的直方图信息。
- 遍历模型的参数,为参数的值和梯度计算直方图,并将其添加到 histograms 字典中。这可以帮助你了解模型参数和梯度的分布情况。
- 使用 evaluate 函数评估模型在验证数据集上的性能,得到验证分数 val_score。
- 使用验证分数来更新学习率调度器 scheduler,以便根据验证性能调整学习率。
- 记录验证分数和其他相关信息到实验日志中,包括学习率、图像和掩膜的可视化,以及模型参数和梯度的直方图信息。
if save_checkpoint: 如果需要保存模型检查点,执行以下操作:
- 创建存储检查点的目录。
- 将模型的状态字典保存到文件中,并添加 mask_values 到状态字典中。这可以用于在以后恢复模型的训练状态。
- 记录保存检查点的信息到日志中。
6. args
def get_args():
parser = argparse.ArgumentParser(description='Train the UNet on images and target masks')
parser.add_argument('--epochs', '-e', metavar='E', type=int, default=5, help='Number of epochs')
parser.add_argument('--batch-size', '-b', dest='batch_size', metavar='B', type=int, default=1, help='Batch size')
parser.add_argument('--learning-rate', '-l', metavar='LR', type=float, default=1e-5,
help='Learning rate', dest='lr')
parser.add_argument('--load', '-f', type=str, default=False, help='Load model from a .pth file')
parser.add_argument('--scale', '-s', type=float, default=0.5, help='Downscaling factor of the images')
parser.add_argument('--validation', '-v', dest='val', type=float, default=10.0,
help='Percent of the data that is used as validation (0-100)')
parser.add_argument('--amp', action='store_true', default=False, help='Use mixed precision')
parser.add_argument('--bilinear', action='store_true', default=False, help='Use bilinear upsampling')
parser.add_argument('--classes', '-c', type=int, default=2, help='Number of classes')
return parser.parse_args()
7. main
if __name__ == '__main__':
args = get_args()
logging.basicConfig(level=logging.INFO, format='%(levelname)s: %(message)s')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
logging.info(f'Using device {device}')
# Change here to adapt to your data
# n_channels=3 for RGB images
# n_classes is the number of probabilities you want to get per pixel
model = UNet(n_channels=3, n_classes=args.classes, bilinear=args.bilinear)
model = model.to(memory_format=torch.channels_last)
logging.info(f'Network:\n'
f'\t{model.n_channels} input channels\n'
f'\t{model.n_classes} output channels (classes)\n'
f'\t{"Bilinear" if model.bilinear else "Transposed conv"} upscaling')
if args.load:
state_dict = torch.load(args.load, map_location=device)
del state_dict['mask_values']
model.load_state_dict(state_dict)
logging.info(f'Model loaded from {args.load}')
model.to(device=device)
try:
train_model(
model=model,
epochs=args.epochs,
batch_size=args.batch_size,
learning_rate=args.lr,
device=device,
img_scale=args.scale,
val_percent=args.val / 100,
amp=args.amp
)
except torch.cuda.OutOfMemoryError:
logging.error('Detected OutOfMemoryError! '
'Enabling checkpointing to reduce memory usage, but this slows down training. '
'Consider enabling AMP (--amp) for fast and memory efficient training')
torch.cuda.empty_cache()
model.use_checkpointing()
train_model(
model=model,
epochs=args.epochs,
batch_size=args.batch_size,
learning_rate=args.lr,
device=device,
img_scale=args.scale,
val_percent=args.val / 100,
amp=args.amp
)
- model = UNet(n_channels=3, n_classes=args.classes, bilinear=args.bilinear) 创建 UNet 模型,根据命令行参数指定的通道数和类别数。如果需要加载预训练模型,从文件中加载模型参数。
- model = model.to(memory_format=torch.channels_last) 这行代码将模型的张量存储格式设置为 torch.channels_last,这是 PyTorch 的一种存储格式
- if args.load:如果需要加载预训练模型,从文件中加载模型参数。
- model.to(device=device) 将模型计算迁移到指定设备上。
- try: train_model 使用 try 块来训练模型,如果在训练过程中出现 GPU 内存溢出错误,将尝试使用检查点策略来降低内存使用。
5. evalute.py
def evaluate(net, dataloader, device, amp):
net.eval()
num_val_batches = len(dataloader)
dice_score = 0
# iterate over the validation set
with torch.autocast(device.type if device.type != 'mps' else 'cpu', enabled=amp):
for batch in tqdm(dataloader, total=num_val_batches, desc='Validation round', unit='batch', leave=False):
image, mask_true = batch['image'], batch['mask']
# move images and labels to correct device and type
image = image.to(device=device, dtype=torch.float32, memory_format=torch.channels_last)
mask_true = mask_true.to(device=device, dtype=torch.long)
# predict the mask
mask_pred = net(image)
if net.n_classes == 1:
assert mask_true.min() >= 0 and mask_true.max() <= 1, 'True mask indices should be in [0, 1]'
mask_pred = (F.sigmoid(mask_pred) > 0.5).float()
# compute the Dice score
dice_score += dice_coeff(mask_pred, mask_true, reduce_batch_first=False)
else:
assert mask_true.min() >= 0 and mask_true.max() < net.n_classes, 'True mask indices should be in [0, n_classes['
# convert to one-hot format
mask_true = F.one_hot(mask_true, net.n_classes).permute(0, 3, 1, 2).float()
mask_pred = F.one_hot(mask_pred.argmax(dim=1), net.n_classes).permute(0, 3, 1, 2).float()
# compute the Dice score, ignoring background
dice_score += multiclass_dice_coeff(mask_pred[:, 1:], mask_true[:, 1:], reduce_batch_first=False)
net.train()
return dice_score / max(num_val_batches, 1)
- net.eval():将模型设置为评估模式,即不进行梯度计算,以便在验证阶段不影响模型的权重更新。
- 初始化 dice_score 用于累计 Dice 分数。
- 使用 torch.autocast 区块来开启混合精度(automatic mixed precision)计算环境,根据 amp
参数决定是否使用 GPU 加速混合精度计算。 - 使用 tqdm 迭代验证数据集中的每个批次。
- 将输入图像和真实标签移动到指定设备,并将图像张量的存储格式设置 torch.channels_last。
- 使用模型进行预测,得到预测的掩码 mask_pred。
- 根据模型的类别数,进行不同的处理:
如果类别数为 1,说明是二分类任务,将预测的掩码应用 sigmoid 函数,然后根据阈值 0.5 进行二值化,计算 Dice 分数。
如果类别数大于 1,说明是多类别任务(例如语义分割中的多类别分割),将预测的掩码和真实标签都转换为 one-hot 编码,并进行维度转换。然后计算 Dice 分数,忽略背景类别。 - 累计 Dice 分数。
- net.train():将模型恢复为训练模式。
- 返回 Dice 分数的均值,考虑到可能的空验证集情况,分母使用 max(num_val_batches, 1) 确保不会除以零。
6. predict.py
1. predict_img:
def predict_img(net,
full_img,
device,
scale_factor=1,
out_threshold=0.5):
net.eval()
img = torch.from_numpy(BasicDataset.preprocess(None, full_img, scale_factor, is_mask=False))
img = img.unsqueeze(0)
img = img.to(device=device, dtype=torch.float32)
with torch.no_grad():
output = net(img).cpu()
output = F.interpolate(output, (full_img.size[1], full_img.size[0]), mode='bilinear')
if net.n_classes > 1:
mask = output.argmax(dim=1)
else:
mask = torch.sigmoid(output) > out_threshold
return mask[0].long().squeeze().numpy()
这段代码定义了一个函数 predict_img,用于对输入图像进行预测并返回预测的掩码。
- net.eval():将模型设置为评估模式,同样不进行梯度计算。
- 将输入图像通过 BasicDataset.preprocess 函数进行预处理,将图像转换为合适的尺度。这个预处理函数会根据参数scale_factor 进行图像尺度的缩放,同时确保图像不会缩放得太小。
- 创建一个单批次的输入张量,将预处理后的图像添加一个额外的维度,然后将其移动到指定设备上。
- 使用 torch.no_grad() 上下文,执行模型的前向传播,得到预测的输出。
- 使用 F.interpolate 函数将输出的预测结果插值回原始图像尺寸,使用双线性插值法进行插值。
- 根据模型的类别数,进行不同的处理:
如果类别数大于 1,说明是多类别任务,选择预测的通道中最大的值作为掩码的预测结果。
如果类别数为 1,说明是二分类任务,应用 sigmoid 函数,并根据阈值 out_threshold 进行二值化,得到掩码的预测结果。 - 最后,将预测结果的张量转换为 NumPy 数组并返回。掩码数组将通过 .squeeze() 函数来去除多余的维度,并使用.numpy() 将 PyTorch 张量转换为 NumPy 数组。
2. args:
def get_args():
parser = argparse.ArgumentParser(description='Predict masks from input images')
parser.add_argument('--model', '-m', default='MODEL.pth', metavar='FILE',
help='Specify the file in which the model is stored')
parser.add_argument('--input', '-i', metavar='INPUT', nargs='+', help='Filenames of input images', required=True)
parser.add_argument('--output', '-o', metavar='OUTPUT', nargs='+', help='Filenames of output images')
parser.add_argument('--viz', '-v', action='store_true',
help='Visualize the images as they are processed')
parser.add_argument('--no-save', '-n', action='store_true', help='Do not save the output masks')
parser.add_argument('--mask-threshold', '-t', type=float, default=0.5,
help='Minimum probability value to consider a mask pixel white')
parser.add_argument('--scale', '-s', type=float, default=0.5,
help='Scale factor for the input images')
parser.add_argument('--bilinear', action='store_true', default=False, help='Use bilinear upsampling')
parser.add_argument('--classes', '-c', type=int, default=2, help='Number of classes')
return parser.parse_args()
3. get_output_filenames 、mask_to_image
def get_output_filenames(args):
def _generate_name(fn):
return f'{os.path.splitext(fn)[0]}_OUT.png'
return args.output or list(map(_generate_name, args.input))
def mask_to_image(mask: np.ndarray, mask_values):
if isinstance(mask_values[0], list):
out = np.zeros((mask.shape[-2], mask.shape[-1], len(mask_values[0])), dtype=np.uint8)
elif mask_values == [0, 1]:
out = np.zeros((mask.shape[-2], mask.shape[-1]), dtype=bool)
else:
out = np.zeros((mask.shape[-2], mask.shape[-1]), dtype=np.uint8)
if mask.ndim == 3:
mask = np.argmax(mask, axis=0)
for i, v in enumerate(mask_values):
out[mask == i] = v
return Image.fromarray(out)
- get_output_filenames(args):这个函数用于生成输出文件名。如果 args.output为指定的,那么直接使用这个值,否则根据输入文件名生成一个对应的输出文件名,将输入文件的扩展名去掉并加上 _OUT.png。
- mask_to_image(mask: np.ndarray, mask_values):这个函数用于将预测的掩码转换为图像形式。它接收两个参数:预测的掩码数组 mask 和掩码值的列表mask_values。
如果 mask_values 是一个嵌套的列表,表示多类别掩码,根据掩码的形状创建一个对应大小的零矩阵out,并将每个类别的掩码值填充到对应位置。
如果 mask_values 是 [0, 1],表示二分类掩码,创建一个布尔类型的零矩阵out。
如果 mask_values 是其他列表或数组,表示每个类别的掩码值,创建一个无符号整数类型的零矩阵 out。
然后,根据掩码的维度,如果掩码是多通道的,取其中预测值最大的通道作为掩码,否则将掩码值与对应的类别值进行映射,并将映射后的值填充到 out 中。
最后,将填充好的矩阵 out 转换为 PIL 图像对象,并返回。这个函数实现了将预测的掩码转换为可视化的图像形式。
3. main
if __name__ == '__main__':
args = get_args()
logging.basicConfig(level=logging.INFO, format='%(levelname)s: %(message)s')
in_files = args.input
out_files = get_output_filenames(args)
net = UNet(n_channels=3, n_classes=args.classes, bilinear=args.bilinear)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
logging.info(f'Loading model {args.model}')
logging.info(f'Using device {device}')
net.to(device=device)
state_dict = torch.load(args.model, map_location=device)
mask_values = state_dict.pop('mask_values', [0, 1])
net.load_state_dict(state_dict)
logging.info('Model loaded!')
for i, filename in enumerate(in_files):
logging.info(f'Predicting image {filename} ...')
img = Image.open(filename)
mask = predict_img(net=net,
full_img=img,
scale_factor=args.scale,
out_threshold=args.mask_threshold,
device=device)
if not args.no_save:
out_filename = out_files[i]
result = mask_to_image(mask, mask_values)
result.save(out_filename)
logging.info(f'Mask saved to {out_filename}')
if args.viz:
logging.info(f'Visualizing results for image {filename}, close to continue...')
plot_img_and_mask(img, mask)
- 加载预训练的模型权重,同时获取掩码值列表 mask_values。
- 循环处理每个输入图像文件:
- 打开图像文件。
- 调用 predict_img 函数预测图像对应的掩码。
- 如果不指定 --no-save 参数,将预测的掩码转换为图像并保存到输出文件。
- 如果指定 --viz 参数,可视化图像和预测掩码。














 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









