







Hadoop Distributed File System (HDFS)是一种分布式文件系统,具有高容错性,可运行在廉价的硬件上,具有高吞吐量,特别适合存放大规模数据集。HDFS实际架构非常复杂,今天通过一篇文章来浓缩最关键的几个点,结合图和源码等理解HDFS体系架构。
系统设计目标
- 硬件故障
具有硬件故障检测能力,可自动快速恢复。 - 流式数据访问
高数据访问吞吐量,而非低延时。 - 大数据集
需支持大数据集,一个集群可扩展到成百上千节点,支持容纳千万级数量的文件。 - 简单一致性模型
一次写入多次读取,一个文件在创建、写入、关闭后,不允许再修改(除了append和truncate操作)。 - 移动计算比移动数据更优
贴近数据计算,可以减小网络阻塞,扩大整体的系统吞吐量。HDFS需要支持把应用移动到靠近数据的节点上去运行。 - 适配异构硬件和软件平台
HDFS需支持在不同的硬件平台上迁移。
HDFS体系架构
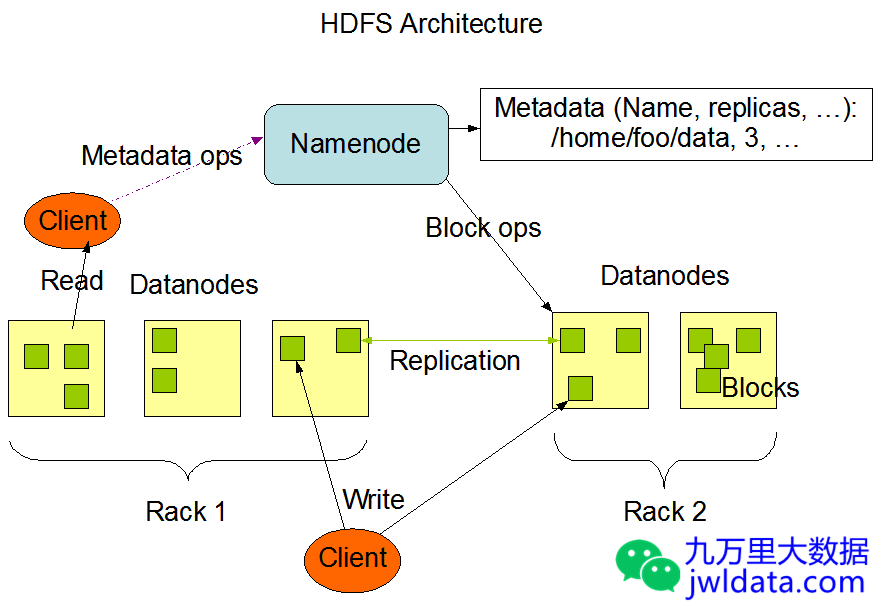
HDFS采用master/slave架构。一个HDFS集群通常由一个NameNode和若干DataNode组成。在不考虑NameNode高可用时,还会有一个SecondaryNameNode来负责做元数据的checkpoint。在NameNode的高可用架构下,SecondaryNameNode会被替换成另一个standby状态的NameNode,具体这里不展开。在整个HDFS涉及到许多的核心概念,下面做一个简单介绍。
- NameNode: NameNode负责管理文件系统的名字空间和管理客户端的访问。NameNode执行文件系统名字空间的操作比如文件的打开、关闭、重命名文件或者目录。它负责确定文件到block的映射,以及block到具体DataNode的映射。
- DataNode: DataNode是HDFS的实际数据存储节点,负责管理它所在节点的存储,客户端的读写请求。定期上报心跳(Heartbeat)和块的存储位置信息(Blockreport)。DataNode在NameNode的指令下进行数据块的创建、删除、复制。
- block: HDFS上一个大文件如果大于配置的blocksize(默认是128MB),会被分成多个数据块(block)存储,这些数据块会分散存储在不同的DataNode上。
- EditLog: 在HDFS发起的创建、删除等操作其实是一个事务,NameNode会使用事务日志(EditLog)来记录文件系统元数据的每一个变化。EditLog持久化在NameNode的本地磁盘上。在SecondaryNameNode或standby NameNode做checkpoint时,会合并FsImage和EditLog成新的FsImage。
- FsImage: FsImage是NameNode的元数据存储快照,持久化在NameNode的本地磁盘上。
- SecondaryNameNode: 辅助NameNode做FsImage的checkpoint操作。
HDFS整体架构如下图所示:
数据副本
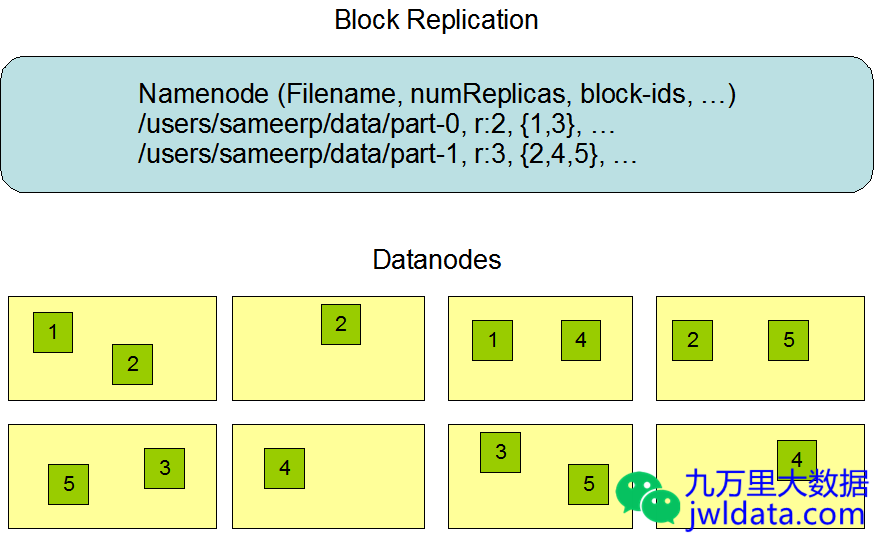
HDFS可以设置一个默认的副本因子(dfs.replication,默认为3),但应用也可以自己指定文件的副本数,比如设置成2。
HDFS的文件特点是一次写入多次读取(write-once-read-many),且在写入时任意时刻只支持一个写客户端。
NameNode保存着文件到block的映射关系,block到具体DataNode的映射,block的副本数等。
DataNode定期上报心跳(Heartbeat)和块的存储位置信息(Blockreport)。NameNode据此来判断DataNode是否在正常工作,是否有块丢失或块冗余,并通知DataNode重新生成丢失的块或删除冗余的块等操作。
HDFS的数据副本分布示例如下图所示:
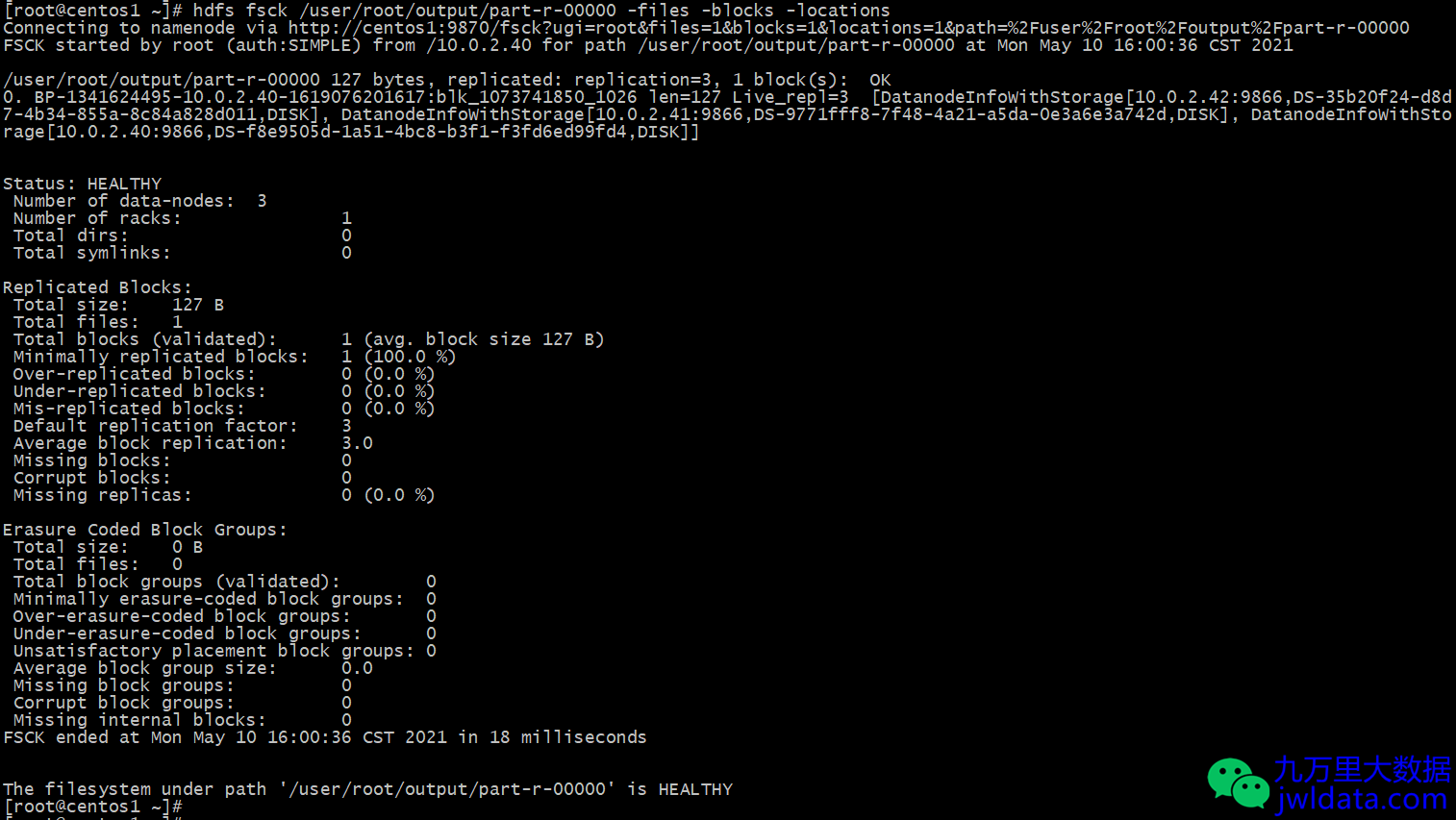
可以使用命令行查询HDFS文件的block在DataNode上的分布情况和副本数等信息。
hdfs fsck /user/root/output/part-r-00000 -files -blocks -locations
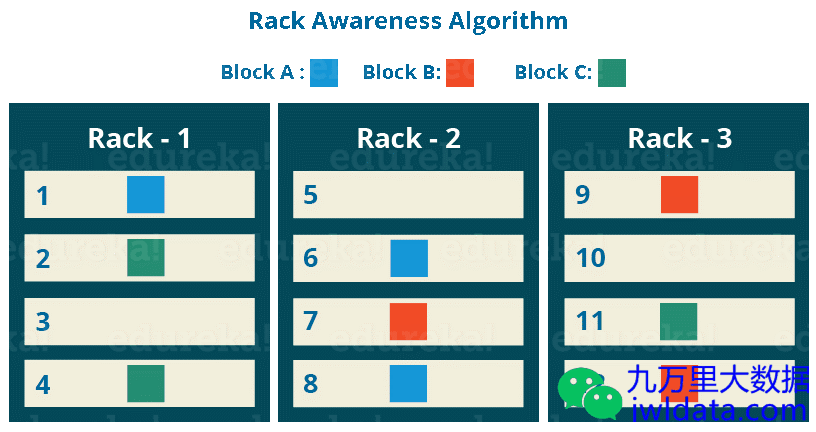
机架感知与数据读写
rack(机架)指的是在同一个物理网络交换机下的节点集合,在同一个rack内的2个节点之间网络带宽要比不同rack之间2个节点的网络带宽要大。HDFS集群的rack awareness提供了HDFS数据的灾备容错。
客户端在写HDFS时(经典三副本情况下):
第一个副本放在发起写请求的客户端上(如果客户端不在DataNode上,那么随机选取一个同rack的Datanode存放);
第二个副本放在与第一个副本所在DataNode不同rack的DataNode上;
第三个副本放在与第二个副本所在DataNode的相同rack的不同DataNode上。
可能理解起来比较拗口,可以看以下这张图,以及HDFS的源代码注释(BlockPlacementPolicyDefault类),方便理解。
BlockPlacementPolicyDefault类具体可参阅:
https://github.com/apache/hadoop/blob/release-2.6.0/hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/blockmanagement/BlockPlacementPolicyDefault.java
/**
* The class is responsible for choosing the desired number of targets
* for placing block replicas.
* The replica placement strategy is that if the writer is on a datanode,
* the 1st replica is placed on the local machine by default
* (By passing the {@link org.apache.hadoop.fs.CreateFlag#NO_LOCAL_WRITE} flag
* the client can request not to put a block replica on the local datanode.
* Subsequent replicas will still follow default block placement policy.).
* If the writer is not on a datanode, the 1st replica is placed on a random
* node.
* The 2nd replica is placed on a datanode that is on a different rack.
* The 3rd replica is placed on a datanode which is on a different node of the
* rack as the second replica.
*/
客户端在读HDFS时,向NameNode获取文件的元数据信息,NameNode返回文件的块存储位置,客户端选择块存储位置最近的节点进行块操作,通常优先级是本机 > 本机架 > 其他机架的节点。
客户端读取一个HDFS文件,首先获得文件的blocks,然后获取blocks的locations
https://github.com/apache/hadoop/blob/release-2.6.0/hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/DFSClient.java
从release-2.8.0-RC0起,HDFS调整了源代码结构。
https://github.com/apache/hadoop/blob/release-3.2.2-RC5/hadoop-hdfs-project/hadoop-hdfs-client/src/main/java/org/apache/hadoop/hdfs/DFSClient.java
/**
* Get block location info about file
*
* getBlockLocations() returns a list of hostnames that store
* data for a specific file region. It returns a set of hostnames
* for every block within the indicated region.
*
* This function is very useful when writing code that considers
* data-placement when performing operations. For example, the
* MapReduce system tries to schedule tasks on the same machines
* as the data-block the task processes.
*
* Please refer to
* {@link FileSystem#getFileBlockLocations(FileStatus, long, long)}
* for more details.
*/
public BlockLocation[] getBlockLocations(String src, long start,
long length) throws IOException {
checkOpen();
try (TraceScope ignored = newPathTraceScope("getBlockLocations", src)) {
LocatedBlocks blocks = getLocatedBlocks(src, start, length);
BlockLocation[] locations = DFSUtilClient.locatedBlocks2Locations(blocks);
HdfsBlockLocation[] hdfsLocations =
new HdfsBlockLocation[locations.length];
for (int i = 0; i < locations.length; i++) {
hdfsLocations[i] = new HdfsBlockLocation(locations[i], blocks.get(i));
}
return hdfsLocations;
}
}
参考资料
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html















 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









