







支持向量机(SVM)
标签(空格分隔): 监督学习
@author : duanxxnj@163.com
@time : 2016-07-31
二、软间隔最大化分类器
在这篇文章之前所有的讨论中,假设,所面对的数据在特征空间 ϕ(x) 中是线性可分的,那么,最终得到的SVM可以在输入空间 X 中得到一个准确的判别面,尽管其对应的判别面可能是一个非线性判别面。
然而,在现实的数据中,数据是线性不可分的(或者近似线性可分)。换一种说法就是:类条件分布存在重叠。如果这样,上面讲的算法最终只会有两种结果:1、决策面会出现严重的震荡,而无法收敛;2、即便收敛到了一个非线性的决策面,其决策面也会十分的复杂,泛化能力低。
因此,我们就需要对原始的SVM算法做一定的改动,让它对数据的要求,从线性可分扩展到线性不可分。即:允许部分训练数据存在分类错误的情况,以得到一个相对比较好的决策面。 这个改动后的SVM一般被称为 软间隔最大化分类器 ,而与之相对应的,前面论述的只可以解决线性可分数据的SVM,称为 硬间隔最大化分类器 。
2.1 软间隔最大化分类器的两个问题
那么,现在就有两个问题摆在我们面前:
1.在SVM中,对于非线性可分的数据而言,哪些样本点是存在分类错误的样本点?
2.对于分类错误的点,软间隔最大化分类器 如何处理以得到相对比较好的决策面?
两个问题,就是软间隔最大化分类器的核心问题,回答了这两个问题,掌握了软间隔最大化分类器。
哪些是分类错误的样本点
首先必须要知道,面对一个非线性可分的数据集,哪些样本点是分类错误的样本点?可以先看下面这幅图:
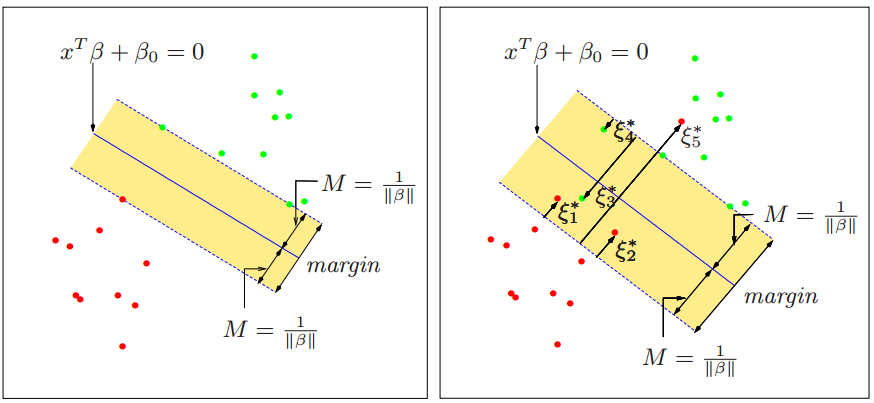
图中,左边那幅图对应的是数据线性可分时,SVM的状态。此时有决策面:
图中,右边那幅图对应的就是数据线性不可分时,SVM的状态。此时决策面依然是: xTβ+β0=0 ,最小间隔仍然为 M=1/||β|| 。不过,右图中 ξ∗i;i=1,2...5 就是非线性可分数据在SVM中分类错误的点。
那么总结一下,在非线性可分的情况下,样本点的状态一共有下面五种:
1.非支持向量,即是在
margin
两侧,被正确分类的样本点。这些样本点对于SVM的决策面没有贡献。
2.在
margin
边界上面的点,这个是支持向量,且被正确分类。
3.在
margin
内部,被正确分类的点,比如
ξ∗1,ξ∗2,ξ∗4
,这些也是支持向量。
4.在决策面上的点,这些点可以拒绝判断,也可以直接认为是分类正确的点。
5.真正的被分类错误的点:
ξ∗3,ξ∗5
,这些点直接走到了决策面的另一边去了。
很容易发现,相对于数据线性可分的情况而言,非线性可分数据的状态多了三种情况,也就是上面五种情况的后三种,线性可分的数据只存在前面两种情况。
而后面三种情况的样本点的间隔,都比最小间隔
r
也就是图中的
分类错误的样本点的处理:软间隔变量
前面提到了,后面三种情况的样本点的间隔,都比最小间隔
r
也就是图中的
对于前面第三种情况:在 margin 内部,被正确分类的点,比如 ξ∗1,ξ∗2,ξ∗4 。这些点的间隔为:
ξ∗i=ξi∗r; 0<ξi<1对于前面第四种情况:在决策面上的点,这些点的间隔为:
ξ∗i=ξi∗r; ξi=1对于前面第五种情况:真正的被分类错误的点: ξ∗3,ξ∗5 ,这些直接走到了决策面的另一边去了的点,这些点的间隔为:
ξ∗i=ξi∗r; ξi>1
为了将前面的第一种情况:非支持向量,即是在 margin 两侧,被正确分类的样本点。和第二种情况:在 margin 边界上面的点,这个是支持向量,且被正确分类。也统一的用软间隔变量 ξ 来表示,这里将SVM的优化公式重写为下面这个形式:
而前面第一种情况和第二种情况所对应的 ξi=0 。
和“最小间隔最大化”章节中讨论的一样,
w
和
那么,上面的式子又可以改写为:
可以看到,上面的式子是最大化 1/||w|| ,很容易知道,其等价于 最小化 ||w||2 ,那么最小间隔最大化,最终就可以变为下面这个式子:
这里,最小间隔为:
2.2 软间隔最大化分类器 的优化公式
上面提到的第五种情况,真正的被分类错误的点: ξ∗3,ξ∗5 ,这些直接走到了决策面的另一边去了的点,所对应的 ξi>1 。如果说我们知道 ∑Ni=1ξi≤K ,那么,就可以说,这个 软间隔最大化分类器 的训练错误样本数,最多为 K 个。让训练误差尽量的小也是我们的一个优化目标,这样,软间隔最大化分类器 就成了一个多目标的优化问题:
由于上面两个优化目标的限制条件是一样的,可以将两个优化目标合成一个优化目标:
这里的参数
C
是损失参数(cost parameter),用于权衡
- C 越小,模型越偏向于最小化
||w||2 ,而忽略 ∑Ni=1ξi ,这样模型非常简单,但模型的错误率相对较高。- C 越大,模型越偏向于最小化 ∑Ni=1ξi ,而忽略 ||w||2 ,这样模型的错误率相对较低,但模型相对较为复杂。
需要强调: ξi 是对于SVM而言,分类错误的样本点 xi 的分类错误间隔相对于最小间隔 r 的比例。我们不可能让错误的比例无限的增长,那样分类错误就太大了。所以,我们需要对错误间隔进行限制,而限制的手段,就是为总的错误间隔比例加一上限:
∑ξi≤constant 。这是软间隔最大化分类器 优化公式的另一种解释。
2.3 软间隔最大化分类器 的对偶问题
这里的步骤和 1.5 拉格朗日对偶性 几乎雷同,首先将 软间隔最大化分类器 的优化公式转换为拉个朗日函数的形式,其原始的优化公式为:
minw,b,ξ{12||w||2+C∑i=1Nξi}st:ti{wTϕ(xi)+b}≥1−ξi;i=1,2,...Nξi≥0;i=1,2,...N拉个朗日函数为:
L(w,b,ξ,α,μ)=12||w||2+C∑i=1Nξi优化目标−∑i=1Nαi{ti{wTϕ(xi)+b}−1+ξi}−∑i=1Nμiξn不等式约束其中, αi,μi 为拉格朗日乘子。将 L(w,b,ξ,α,μ) 分别对 w,b,ξ 求偏导:
∇wL(w,b,ξ,α,μ)∇bL(w,b,ξ,α,μ)∇ξiL(w,b,ξ,α,μ)=w−∑i=1Nαitiϕ(xi)=0=∑i=1Nαiti=0=C−αi−βi=0;i=1,2,..N就可以得到:
w=∑i=1Nαitiϕ(xi)∑i=1Nαiti=0C−αi−βi=0;i=1,2..N将上面三个式子带入到 L(w,b,ξ,α,μ) 中,和之前 1.6 最小间隔最大化求解 中的推导一样,最终可以得到:
minw,b,ξL(w,b,ξ,α,μ)=−12∑i=1N∑j=1N{αiαjtitj<ϕ(xi),ϕ(xj)>}+∑i=iNαi这里的 <ϕ(xi),ϕ(xj)> <script type="math/tex" id="MathJax-Element-1553"><\phi(x_i),\phi(x_j)></script> 是 ϕ(xi) 和 ϕ(xj) 的內积。
再对 minw,b,ξL(w,b,ξ,α,μ) 求极大化,即可得到 软间隔最大化分类器 的对偶问题:
maxα{−12∑i=1N∑j=1N{αiαjtitj<ϕ(xi),ϕ(xj)>}+∑i=iNαi}s.t. ∑i=1NαitiC−αi−μiαiμi=0=0≥0≥0;i=1,2,...N这个就是原问题的对偶问题,当然了,可以将这个对偶问题的目标函数的符号换一下,,让它成为一个最小化的问题,并将后面三个式子做一个合并:
minα{12∑i=1N∑j=1N{αiαjtitj<ϕ(xi),ϕ(xj)>}−∑i=iNαi}s.t. ∑i=1Nαiti0≤αi=0≤C;i=1,2,...N这就是 软间隔最大化分类器 的对偶问题,和前面相比,这里的对偶问题只是限制条件 0≤αi≤C 和前面不同,其他的是一模一样的。
2.4 软间隔最大化分类器 求解
很显然,得到了软间隔最大化分类器 的对偶形式之后,其优化求解出来的就是最优解 α∗ 。这里再次说明:假设 α∗ 我们已经通过某种算法得到了,至于这个算法是什么后面的章节会详细的说明,这里不同担心。
仿照 1.5 拉格朗日对偶性 中的公式推导 ,假设 x∗,α∗,ξ∗,α∗,μ∗ 为最优解,可以很容易推出 软间隔最大化分类器 拉格朗日优化的KKT条件为:
∇wL(x∗,α∗,ξ∗,α∗,μ∗)∇bL(x∗,α∗,ξ∗,α∗,μ∗)∇ξL(x∗,α∗,ξ∗,α∗,μ∗)α∗i(ti{w∗Tϕ(xi)+b∗}−1+ξ∗i)ti{w∗Tϕ(xi)+b∗}−1+ξ∗iα∗iμ∗iξ∗iξ∗iμ∗i=w∗−∑i=1Nα∗itiϕ(xi)=0=∑i=1Nα∗iti=0=C−αi−μi=0=0;i=1,2,...N≥0;i=1,2,...N≥0;i=1,2,...N=0;i=1,2,...N≥0;i=1,2,...N≥0;i=1,2,...N在假设知道 α∗ 的情况下,由KKT条件的第一个公式: ∇wL(x∗,α∗,ξ∗,α∗,μ∗)=w∗−∑Ni=1α∗itiϕ(xi)=0 可以知道, w 的最优解为:
w∗=∑i=1Nα∗itiϕ(xi) 再找到一个 0<αj<C ,其所对应的样本点满足: ti{w∗Tϕ(xi)+b∗}−1=0 ,那么,就可以和前面的推导一样,得到:
b∗=1ti−w∗Tϕ(xi)同时,需要注意: t2i=1 ,并带入 w∗T ,就可以将上面这个式子重写为:
b∗=ti−∑j=1Nα∗jtj<ϕ(xj),ϕ(xi)>当然,为了稳妥起见,很多时候,我们会将所有的支持向量 xi∈S 对应的 b∗i 都求出来,然后用其均值,作为最终的 b∗ 。这里 S 是支持向量的集合,也就是
α∗i>0 所对应的点集:b∗=1Ns∑i=1Nsb∗i这样,就可以求得最终的决策超平面为:
∑i=1N{α∗iti<ϕ(xi),ϕ(x)>}+b∗=0分类决策函数可以写为:
f(x)=sign{∑i=1N{α∗iti<ϕ(xi),ϕ(x)>}+b∗}
2.5 对参数 α,ξ 的讨论
基于上面的推导,可以很容易的看出,软间隔最大化分类器 就是在 硬间隔最大化分类器 的基础上,处理非线性可分的数据。而参数 α,ξ 起着决定样本点类别的作用,那么,这里就对这两个参数做一下讨论,看看这两个参数是如何判断非线性可分数据集中的样本点的类别的。
为了方便,这里直接用一张表格说明参数 α,ξ 和样本点之间的关系,图种叉叉的部分,说明这种情况并不存在,下面将对这个表格做详细的说明:

在 2.1 软间隔最大化分类器的两个问题 中,就讨论过,非线性可分情况下,SVM中的样本点一共有五种情况,也就是上面表格中的所对应的五种情况。
从表格中可以粗略的观察到:
- 当 αi=0 时,对应的样本点是非支持向量;当 αi>0 时,对应的样本点是支持向量
- 当 ξ≤1 时,对应的样本点可以被正确的分类;当 ξ>1 时,对应的样本点分类错误现在基于参数 α、ξ 对上面五种情况再做更详细的讨论:
1.当 ξi=0,αi=0 时,此时的样本点 xi 并不是支持向量,其被完全的分类正确,样本点满足: ti{wTϕ(xi)+b}>1 。
变量关系:当 αi=0 时,由KKT条件中的第三条: C−αi−μi=0 可以知道, μi=C ;再由KKT条件第七条: μ∗iξ∗i=0 可以知道: ξi=0 ;最后根据KKT条件的第四条和第五条,可以很容易知道: ti{wTϕ(xi)+b}>1 。2.当 ξi=0,0<αi<C 时,此时样本点刚好在SVM的间隔边界上,是支持向量,被正确分类,样本点满足: ti{wTϕ(xi)+b}=1 。
变量关系:当 0<αi<C 时,由KKT条件中的第三条: C−αi−μi=0 可以知道, 0<μi<C ;再由KKT条件第七条: μ∗iξ∗i=0 ,可以知道: ξi=0 。最后根据KKT条件的第四条和第五条,可以很容易知道: ti{wTϕ(xi)+b}=1 。3.当 0<ξi<1,αi=C 时,此时样本点在SVM的正确的间隔边界内,是支持向量,被正确分类,样本点满足: 0<ti{wTϕ(xi)+b}<1 。
变量关系:当 αi=C 时,由KKT条件中的第三条: C−αi−μi=0 可以知道, μi=0 ;再由KKT条件第六、七条: ξ∗i≥0;μ∗iξ∗i=0 ,可以知道: ξi>0 。根据KKT条件的第四条和第五条,可以很容易知道: ti{wTϕ(xi)+b}=1−ξi 。那么,此时 0<ξi<1 ,所以 0<ti{wTϕ(xi)+b}<1 ,即,其对应的样本点在分类正确的间隔中。4.当 ξi=1,αi=C 时,此时样本点在SVM决策面上,是支持向量,被正确分类,样本点满足: ti{wTϕ(xi)+b}=0 。
变量关系:这里的变量关系的分析和第三种情况一样,差别仅仅是 ξi=1 ,由: ti{wTϕ(xi)+b}=1−ξi ,可以很容易知道: ti{wTϕ(xi)+b}=0 ,这样,样本点 xi 就刚好在SVM的决策面上了。5.当 ξi>1,αi=C 时,是支持向量,被错误分类,样本点满足: ti{wTϕ(xi)+b}<0 。
变量关系:这里的变量关系的分析和第三种情况一样,差别仅仅是 ξi>1 ,由: ti{wTϕ(xi)+b}=1−ξi ,可以很容易知道: ti{wTϕ(xi)+b}<0 ,这样,样本点 xi 就在决策面错误的一边,被错误分类了。由于变量 α 是我们最终要求解的变量,这里再单独对变量 α 做一个总结。首先,这里取 g(x) 如下,即SVM的决策面函数:
g(x)=∑i=1N{αiti<ϕ(xi),ϕ(x)>}+b那么,根据前面的表格,可以很容易得到:
αi=00<αi<Cαi=C⇔tig(xi)≥1⇔tig(xi)=1⇔tig(xi)≤1总的来说就是:
- 在SVM间隔区间外的点,对应的 αi=0
- 在SVM间隔区间边缘上的点,对应的 0<αi<C
- 在SVM间隔区间内部的点,对应的 αi=C















 7715
7715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









