






如果你想进一步深入AI编程的魔法世界,那么TensorFlow和PyTorch这两个深度学习框架将是你的不二之选。它们可以帮助你构建更加复杂的神经网络模型,实现图像识别、语音识别等高级功能。
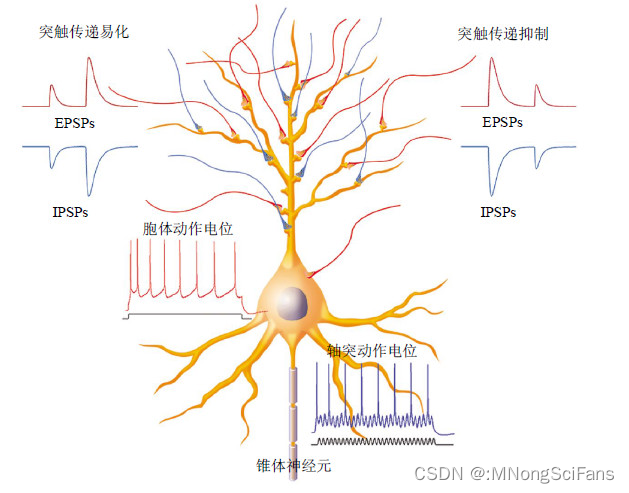
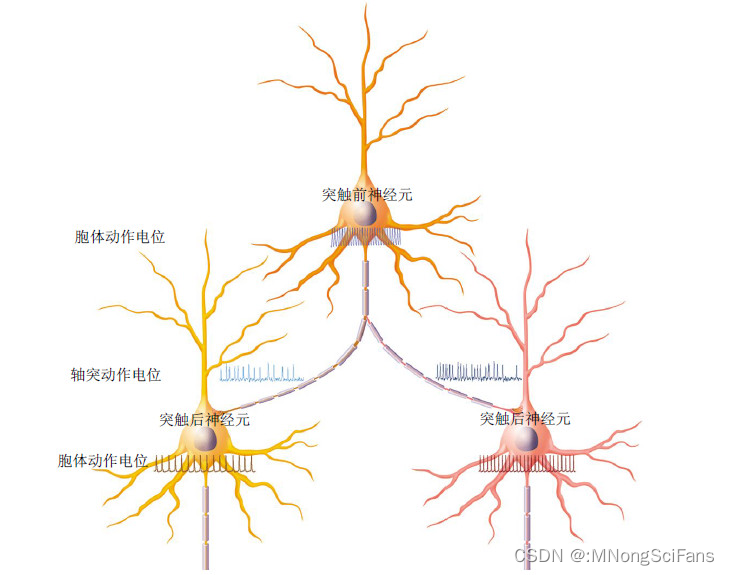

模型原理:神经网络是一种模拟人脑神经元结构的计算模型,通过模拟神经元的输入、输出和权重调整机制来实现复杂的模式识别和分类等功能。
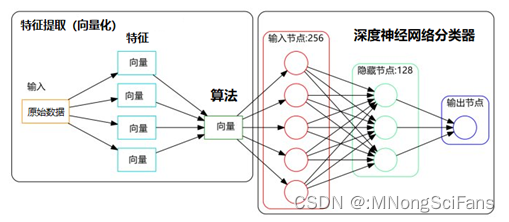
神经网络由多层神经元组成,输入层接收外界信号,经过各层神经元的处理后,最终输出层输出结果。
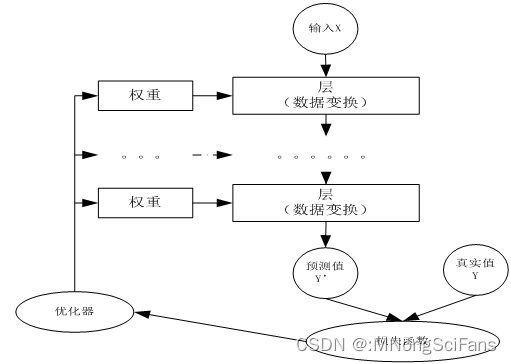
模型训练:神经网络的训练是通过反向传播算法实现的。在训练过程中,根据输出结果与实际结果的误差,逐层反向传播误差,并更新神经元的权重和偏置项,以减小误差。
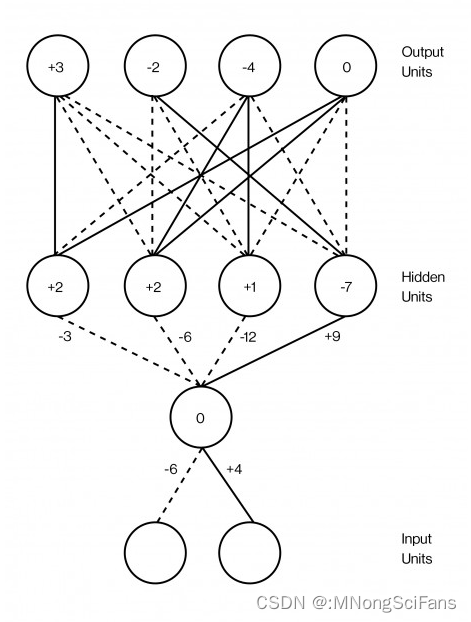
优点:能够处理非线性问题,具有强大的模式识别能力,能够从大量数据中学习复杂的模式。
缺点:容易陷入局部最优解,过拟合问题严重,训练时间长,需要大量的数据和计算资源。
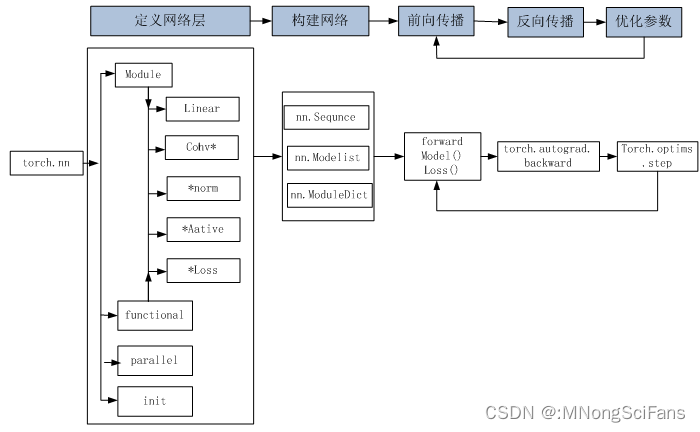
使用场景:适用于图像识别、语音识别、自然语言处理、推荐系统等场景。

示例代码(使用Python的TensorFlow库构建一个简单的神经网络分类器):
# -*- coding: utf-8 -*-
"""
Created on Tue Mar 19 16:50:22 2024
@author: admin
"""
# 使用TensorFlow实现一个简单的神经网络模型
import tensorflow as tf
# 假设你有一个输入数据x和一个目标值y
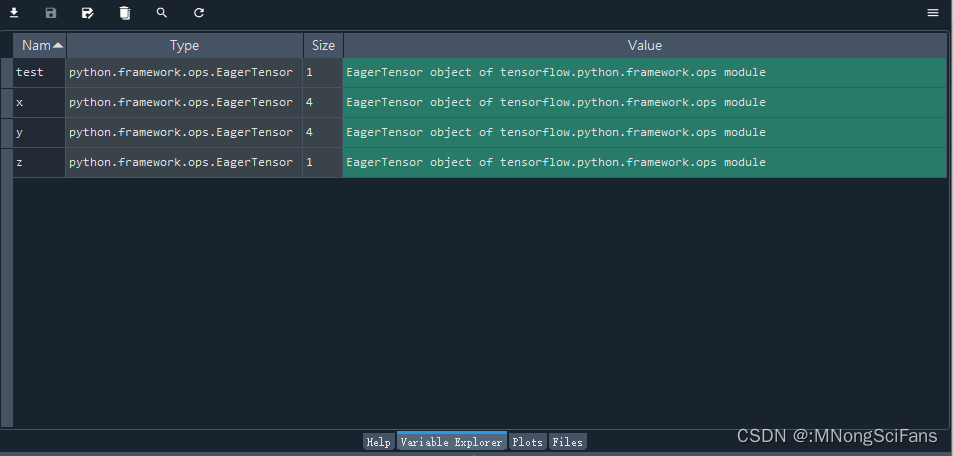
x = tf.constant([[1.0], [2.0], [3.0], [4.0]])
y = tf.constant([[1.0], [2.6], [9.3], [17.8]])
# 创建一个简单的神经网络模型
model = tf.keras.models.Sequential([tf.keras.layers.Dense(units=1, input_shape=[1])])
# 编译模型
model.compile(optimizer='sgd', loss='mean_squared_error')
# 训练模型
model.fit(x, y, epochs=10)
test = tf.constant([[1.8]])
# 使用模型进行预测
print(model.predict(test))

# -*- coding: utf-8 -*-
"""
Created on Wed Mar 20 12:34:26 2024
@author: admin
"""
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import mnist
# 加载MNIST数据集 mnist.load_data() Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
(x_train, y_train), (x_test, y_test) = mnist.load_data("mnist.npz") # 导入数据集
# 归一化处理输入数据
x_train = x_train / 255.0
x_test = x_test / 255.0
# 构建神经网络模型
model = models.Sequential()
model.add(layers.Flatten(input_shape=(28, 28)))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
# 编译模型并设置损失函数和优化器等参数
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
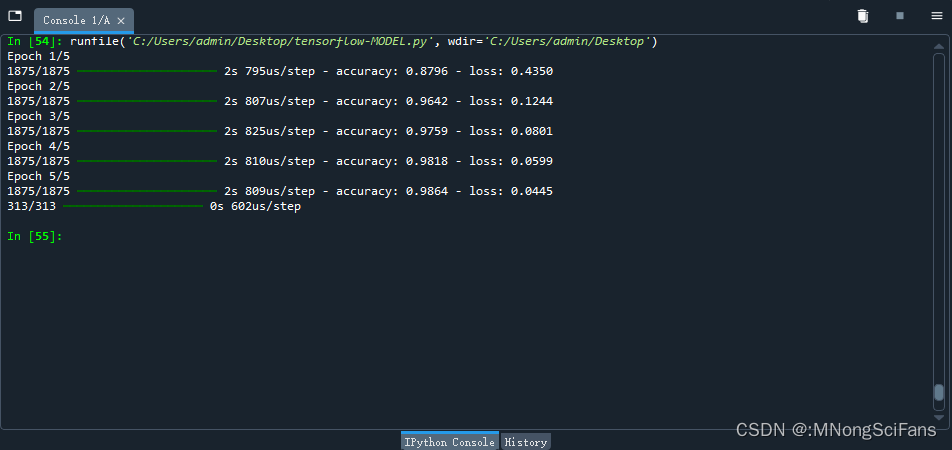
model.fit(x_train, y_train, epochs=5)
# 进行预测
predictions = model.predict(x_test)

参见:
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











