







接着前面系列博客讲,此篇来介绍下tensorflow的模型库的使用,当前安装tensorflow的时候,models中库不会自动安装,可能对比pytorch,会觉得tensorflow自带的object detection模型好少,其实不然。下面就对tensorflow的models中的objection模块进行一个详细的使用介绍。
python 3.6.5
tensorflow-gpu 2.6.2
cuda version: 11.2
cudnn version: cudnn-11.2-linux-x64-v8.1.1.33
主要参考资料来自github上面的文档介绍。
之前很多博客中提到,一个新东西,要善于从官网,github原始Repository,paper去着手,前面学习tensorrt也是这样的,一个好的东西,它的官方文档必然是很全面的,看的过程中有问题了,再去看看他人的帖子,有没有这方面的答疑。对于一个研发人员,虽然知识一直在更新,但学习新知识的方法,能力(英文阅读能力,code能力,相关的专业理论知识)有了,就不必担心跟不上节奏。
一.跑通eager mode下的自带示例
1.如下链接可以进入object_detection的tutorial

2.如下链接里即可以看到使用demo

3. 如下一大块是说要提前配置下环境

4.可以参考博主的配置步骤,如下:
(1)安装下protoc
sudo apt install protobuf-compiler(2)下载GitHub - tensorflow/models: Models and examples built with TensorFlow
博主这里放在如下路径下面:

(3)终端cd到research目录下去,执行如下语句
protoc object_detection/protos/*.proto --python_out=.
(4)完毕后,执行如下命令语句
cp object_detection/packages/tf2/setup.py .可看到目录下多了一个setup.py文件

(5)执行如下语句,安装一些requirements,同时将object_detection安装到tensorflow的site-packages下
python -m pip --default-timeout=100000 install --use-feature=2020-resolver . --ignore-installed![]()
(6)完毕后,可以看到object_detection已经安装,就可以畅快的做一些事情啦。

5.然后按照教程就可以跑下代码了,基本过程就是import一些库,加载小黄鸭的数据集,对应的框标签位置,框中物体的类型,同时再把这些信息在原图上show下,然后读网络的配置文件,以及对应的预训练模型,然后训练,完毕后再对测试集进行一次预测,把预测结果保存到本地。代码中所用到的预训练模型可以提前下好
models/tf2_detection_zoo.md at master · tensorflow/models · GitHub

下载完毕后,把里面的checkpoint拷贝到如下目录下(结合自己的路径)

博主所用demo代码如下:
import matplotlib
print(matplotlib.get_backend())
import matplotlib.pyplot as plt
import os
import random
import io
import imageio
import glob
import scipy.misc
import numpy as np
from six import BytesIO
from PIL import Image, ImageDraw, ImageFont
from IPython.display import display, Javascript
from IPython.display import Image as IPyImage
import tensorflow as tf
from object_detection.utils import label_map_util
from object_detection.utils import config_util
from object_detection.utils import visualization_utils as viz_utils
from object_detection.utils import colab_utils
from object_detection.builders import model_builder
matplotlib.use('module://backend_interagg')
print(matplotlib.get_backend())
def load_image_into_numpy_array(path):
"""Load an image from file into a numpy array.
Puts image into numpy array to feed into tensorflow graph.
Note that by convention we put it into a numpy array with shape
(height, width, channels), where channels=3 for RGB.
Args:
path: a file path.
Returns:
uint8 numpy array with shape (img_height, img_width, 3)
"""
img_data = tf.io.gfile.GFile(path, 'rb').read()
image = Image.open(BytesIO(img_data))
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
def plot_detections(image_np,
boxes,
classes,
scores,
category_index,
figsize=(12, 16),
image_name=None):
"""Wrapper function to visualize detections.
Args:
image_np: uint8 numpy array with shape (img_height, img_width, 3)
boxes: a numpy array of shape [N, 4]
classes: a numpy array of shape [N]. Note that class indices are 1-based,
and match the keys in the label map.
scores: a numpy array of shape [N] or None. If scores=None, then
this function assumes that the boxes to be plotted are groundtruth
boxes and plot all boxes as black with no classes or scores.
category_index: a dict containing category dictionaries (each holding
category index `id` and category name `name`) keyed by category indices.
figsize: size for the figure.
image_name: a name for the image file.
"""
image_np_with_annotations = image_np.copy()
viz_utils.visualize_boxes_and_labels_on_image_array(
image_np_with_annotations,
boxes,
classes,
scores,
category_index,
use_normalized_coordinates=True,
min_score_thresh=0.8)
if image_name:
plt.imsave(image_name, image_np_with_annotations)
else:
plt.imshow(image_np_with_annotations)
# Load images and visualize
train_image_dir = '/home/sxhlvye/Trial2/models-master/research/object_detection/test_images/ducky/train/'
train_images_np = []
for i in range(1, 6):
image_path = os.path.join(train_image_dir, 'robertducky' + str(i) + '.jpg')
train_images_np.append(load_image_into_numpy_array(image_path))
plt.rcParams['axes.grid'] = False
plt.rcParams['xtick.labelsize'] = False
plt.rcParams['ytick.labelsize'] = False
plt.rcParams['xtick.top'] = False
plt.rcParams['xtick.bottom'] = False
plt.rcParams['ytick.left'] = False
plt.rcParams['ytick.right'] = False
plt.rcParams['figure.figsize'] = [14, 7]
for idx, train_image_np in enumerate(train_images_np):
plt.subplot(2, 3, idx+1)
plt.imshow(train_image_np)
plt.show()
gt_boxes = [
np.array([[0.436, 0.591, 0.629, 0.712]], dtype=np.float32),
np.array([[0.539, 0.583, 0.73, 0.71]], dtype=np.float32),
np.array([[0.464, 0.414, 0.626, 0.548]], dtype=np.float32),
np.array([[0.313, 0.308, 0.648, 0.526]], dtype=np.float32),
np.array([[0.256, 0.444, 0.484, 0.629]], dtype=np.float32)
]
# By convention, our non-background classes start counting at 1. Given
# that we will be predicting just one class, we will therefore assign it a
# `class id` of 1.
duck_class_id = 1
num_classes = 1
category_index = {duck_class_id: {'id': duck_class_id, 'name': 'rubber_ducky'}}
# Convert class labels to one-hot; convert everything to tensors.
# The `label_id_offset` here shifts all classes by a certain number of indices;
# we do this here so that the model receives one-hot labels where non-background
# classes start counting at the zeroth index. This is ordinarily just handled
# automatically in our training binaries, but we need to reproduce it here.
label_id_offset = 1
train_image_tensors = []
gt_classes_one_hot_tensors = []
gt_box_tensors = []
for (train_image_np, gt_box_np) in zip(
train_images_np, gt_boxes):
train_image_tensors.append(tf.expand_dims(tf.convert_to_tensor(
train_image_np, dtype=tf.float32), axis=0))
gt_box_tensors.append(tf.convert_to_tensor(gt_box_np, dtype=tf.float32))
zero_indexed_groundtruth_classes = tf.convert_to_tensor(
np.ones(shape=[gt_box_np.shape[0]], dtype=np.int32) - label_id_offset)
gt_classes_one_hot_tensors.append(tf.one_hot(
zero_indexed_groundtruth_classes, num_classes))
print('Done prepping data.')
dummy_scores = np.array([1.0], dtype=np.float32) # give boxes a score of 100%
plt.figure(figsize=(30, 15))
for idx in range(5):
plt.subplot(2, 3, idx+1)
plot_detections(
train_images_np[idx],
gt_boxes[idx],
np.ones(shape=[gt_boxes[idx].shape[0]], dtype=np.int32),
dummy_scores, category_index)
plt.show()
tf.keras.backend.clear_session()
print('Building model and restoring weights for fine-tuning...', flush=True)
num_classes = 1
pipeline_config = '/home/sxhlvye/Trial2/models-master/research/object_detection/configs/tf2/ssd_resnet50_v1_fpn_640x640_coco17_tpu-8.config'
checkpoint_path = '/home/sxhlvye/Trial2/models-master/research/object_detection/test_data/checkpoint/ckpt-0'
# Load pipeline config and build a detection model.
#
# Since we are working off of a COCO architecture which predicts 90
# class slots by default, we override the `num_classes` field here to be just
# one (for our new rubber ducky class).
configs = config_util.get_configs_from_pipeline_file(pipeline_config)
model_config = configs['model']
model_config.ssd.num_classes = num_classes
model_config.ssd.freeze_batchnorm = True
detection_model = model_builder.build(
model_config=model_config, is_training=True)
# Set up object-based checkpoint restore --- RetinaNet has two prediction
# `heads` --- one for classification, the other for box regression. We will
# restore the box regression head but initialize the classification head
# from scratch (we show the omission below by commenting out the line that
# we would add if we wanted to restore both heads)
fake_box_predictor = tf.compat.v2.train.Checkpoint(
_base_tower_layers_for_heads=detection_model._box_predictor._base_tower_layers_for_heads,
# _prediction_heads=detection_model._box_predictor._prediction_heads,
# (i.e., the classification head that we *will not* restore)
_box_prediction_head=detection_model._box_predictor._box_prediction_head,
)
fake_model = tf.compat.v2.train.Checkpoint(
_feature_extractor=detection_model._feature_extractor,
_box_predictor=fake_box_predictor)
ckpt = tf.compat.v2.train.Checkpoint(model=fake_model)
ckpt.restore(checkpoint_path).expect_partial()
# Run model through a dummy image so that variables are created
image, shapes = detection_model.preprocess(tf.zeros([1, 640, 640, 3]))
prediction_dict = detection_model.predict(image, shapes)
_ = detection_model.postprocess(prediction_dict, shapes)
print('Weights restored!')
tf.keras.backend.set_learning_phase(True)
# These parameters can be tuned; since our training set has 5 images
# it doesn't make sense to have a much larger batch size, though we could
# fit more examples in memory if we wanted to.
batch_size = 4
learning_rate = 0.01
num_batches = 100
# Select variables in top layers to fine-tune.
trainable_variables = detection_model.trainable_variables
to_fine_tune = []
prefixes_to_train = [
'WeightSharedConvolutionalBoxPredictor/WeightSharedConvolutionalBoxHead',
'WeightSharedConvolutionalBoxPredictor/WeightSharedConvolutionalClassHead']
for var in trainable_variables:
if any([var.name.startswith(prefix) for prefix in prefixes_to_train]):
to_fine_tune.append(var)
# Set up forward + backward pass for a single train step.
def get_model_train_step_function(model, optimizer, vars_to_fine_tune):
"""Get a tf.function for training step."""
# Use tf.function for a bit of speed.
# Comment out the tf.function decorator if you want the inside of the
# function to run eagerly.
@tf.function
def train_step_fn(image_tensors,
groundtruth_boxes_list,
groundtruth_classes_list):
"""A single training iteration.
Args:
image_tensors: A list of [1, height, width, 3] Tensor of type tf.float32.
Note that the height and width can vary across images, as they are
reshaped within this function to be 640x640.
groundtruth_boxes_list: A list of Tensors of shape [N_i, 4] with type
tf.float32 representing groundtruth boxes for each image in the batch.
groundtruth_classes_list: A list of Tensors of shape [N_i, num_classes]
with type tf.float32 representing groundtruth boxes for each image in
the batch.
Returns:
A scalar tensor representing the total loss for the input batch.
"""
shapes = tf.constant(batch_size * [[640, 640, 3]], dtype=tf.int32)
model.provide_groundtruth(
groundtruth_boxes_list=groundtruth_boxes_list,
groundtruth_classes_list=groundtruth_classes_list)
with tf.GradientTape() as tape:
preprocessed_images = tf.concat(
[detection_model.preprocess(image_tensor)[0]
for image_tensor in image_tensors], axis=0)
prediction_dict = model.predict(preprocessed_images, shapes)
losses_dict = model.loss(prediction_dict, shapes)
total_loss = losses_dict['Loss/localization_loss'] + losses_dict['Loss/classification_loss']
gradients = tape.gradient(total_loss, vars_to_fine_tune)
optimizer.apply_gradients(zip(gradients, vars_to_fine_tune))
return total_loss
return train_step_fn
optimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=0.9)
train_step_fn = get_model_train_step_function(
detection_model, optimizer, to_fine_tune)
print('Start fine-tuning!', flush=True)
for idx in range(num_batches):
# Grab keys for a random subset of examples
all_keys = list(range(len(train_images_np)))
random.shuffle(all_keys)
example_keys = all_keys[:batch_size]
# Note that we do not do data augmentation in this demo. If you want a
# a fun exercise, we recommend experimenting with random horizontal flipping
# and random cropping :)
gt_boxes_list = [gt_box_tensors[key] for key in example_keys]
gt_classes_list = [gt_classes_one_hot_tensors[key] for key in example_keys]
image_tensors = [train_image_tensors[key] for key in example_keys]
# Training step (forward pass + backwards pass)
total_loss = train_step_fn(image_tensors, gt_boxes_list, gt_classes_list)
if idx % 10 == 0:
print('batch ' + str(idx) + ' of ' + str(num_batches)
+ ', loss=' + str(total_loss.numpy()), flush=True)
print('Done fine-tuning!')
test_image_dir = '/home/sxhlvye/Trial2/models-master/research/object_detection/test_images/ducky/test/'
test_images_np = []
for i in range(1, 50):
image_path = os.path.join(test_image_dir, 'out' + str(i) + '.jpg')
test_images_np.append(np.expand_dims(
load_image_into_numpy_array(image_path), axis=0))
# Again, uncomment this decorator if you want to run inference eagerly
@tf.function
def detect(input_tensor):
"""Run detection on an input image.
Args:
input_tensor: A [1, height, width, 3] Tensor of type tf.float32.
Note that height and width can be anything since the image will be
immediately resized according to the needs of the model within this
function.
Returns:
A dict containing 3 Tensors (`detection_boxes`, `detection_classes`,
and `detection_scores`).
"""
preprocessed_image, shapes = detection_model.preprocess(input_tensor)
prediction_dict = detection_model.predict(preprocessed_image, shapes)
return detection_model.postprocess(prediction_dict, shapes)
# Note that the first frame will trigger tracing of the tf.function, which will
# take some time, after which inference should be fast.
label_id_offset = 1
for i in range(len(test_images_np)):
input_tensor = tf.convert_to_tensor(test_images_np[i], dtype=tf.float32)
detections = detect(input_tensor)
plot_detections(
test_images_np[i][0],
detections['detection_boxes'][0].numpy(),
detections['detection_classes'][0].numpy().astype(np.uint32)
+ label_id_offset,
detections['detection_scores'][0].numpy(),
category_index, figsize=(15, 20), image_name="gif_frame_" + ('%02d' % i) + ".jpg")
预测结果可看到

二.通过Training and evalution guide(CPU,GPU, or TPU)来训练预测自己的数据集
主要是参考官方例子
models/tf2_training_and_evaluation.md at master · tensorflow/models · GitHub
1.数据集准备
还是拿博主的sidewalk数据集来做说明,标注过程见博主之前一篇做SSD的博客
balancap/SSD-Tensorflow使用及训练预测自己的数据集_竹叶青lvye的博客-CSDN博客_tensorflow训练自己的数据集![]() https://blog.csdn.net/jiugeshao/article/details/116902463?spm=1001.2014.3001.5501模拟VOC2007的目录结构,放置自己的数据集,如下
https://blog.csdn.net/jiugeshao/article/details/116902463?spm=1001.2014.3001.5501模拟VOC2007的目录结构,放置自己的数据集,如下

需要参考的,如下是链接
链接: 链接: https://pan.baidu.com/s/1QQn62qosT2pXmgnsBgxosw 提取码: i7a9
2.将如上数据集生成record格式
博主这里并没有按照tutorial用命令行方式,可在pycharm中直接运行如下py文件,博主所用的工程在篇尾会附上
# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
r"""Convert raw PASCAL dataset to TFRecord for object_detection.
Example usage:
python object_detection/dataset_tools/create_pascal_tf_record.py \
--data_dir=/home/user/VOCdevkit \
--year=VOC2012 \
--output_path=/home/user/pascal.record
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import hashlib
import io
import logging
import os
from lxml import etree
import PIL.Image
import tensorflow.compat.v1 as tf
from object_detection.utils import dataset_util
from object_detection.utils import label_map_util
flags = tf.app.flags
flags.DEFINE_string('data_dir', '/home/sxhlvye/Trial2/test_object_detection', 'Root directory to raw PASCAL VOC dataset.')
flags.DEFINE_string('set', 'test', 'Convert training set, validation set or '
'merged set.')
flags.DEFINE_string('annotations_dir', 'Annotations',
'(Relative) path to annotations directory.')
flags.DEFINE_string('year', 'VOC2007', 'Desired challenge year.')
flags.DEFINE_string('output_path', '/home/sxhlvye/Trial2/test_object_detection/data/pascal_test.record', 'Path to output TFRecord')
flags.DEFINE_string('label_map_path', '/home/sxhlvye/Trial2/test_object_detection/data/label_map.txt',
'Path to label map proto')
flags.DEFINE_boolean('ignore_difficult_instances', False, 'Whether to ignore '
'difficult instances')
FLAGS = flags.FLAGS
SETS = ['train', 'val', 'trainval', 'test']
YEARS = ['VOC2007', 'VOC2012', 'merged']
def dict_to_tf_example(data,
dataset_directory,
label_map_dict,
ignore_difficult_instances=False,
image_subdirectory='JPEGImages'):
"""Convert XML derived dict to tf.Example proto.
Notice that this function normalizes the bounding box coordinates provided
by the raw data.
Args:
data: dict holding PASCAL XML fields for a single image (obtained by
running dataset_util.recursive_parse_xml_to_dict)
dataset_directory: Path to root directory holding PASCAL dataset
label_map_dict: A map from string label names to integers ids.
ignore_difficult_instances: Whether to skip difficult instances in the
dataset (default: False).
image_subdirectory: String specifying subdirectory within the
PASCAL dataset directory holding the actual image data.
Returns:
example: The converted tf.Example.
Raises:
ValueError: if the image pointed to by data['filename'] is not a valid JPEG
"""
img_path = os.path.join(data['folder'], image_subdirectory, data['filename'])
full_path = os.path.join(dataset_directory, img_path)
with tf.gfile.GFile(full_path, 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = PIL.Image.open(encoded_jpg_io)
if image.format != 'BMP':
raise ValueError('Image format not BMP')
key = hashlib.sha256(encoded_jpg).hexdigest()
width = int(data['size']['width'])
height = int(data['size']['height'])
xmin = []
ymin = []
xmax = []
ymax = []
classes = []
classes_text = []
truncated = []
poses = []
difficult_obj = []
if 'object' in data:
for obj in data['object']:
difficult = bool(int(obj['difficult']))
if ignore_difficult_instances and difficult:
continue
difficult_obj.append(int(difficult))
xmin.append(float(obj['bndbox']['xmin']) / width)
ymin.append(float(obj['bndbox']['ymin']) / height)
xmax.append(float(obj['bndbox']['xmax']) / width)
ymax.append(float(obj['bndbox']['ymax']) / height)
classes_text.append(obj['name'].encode('utf8'))
classes.append(label_map_dict[obj['name']])
truncated.append(int(obj['truncated']))
poses.append(obj['pose'].encode('utf8'))
example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(
data['filename'].encode('utf8')),
'image/source_id': dataset_util.bytes_feature(
data['filename'].encode('utf8')),
'image/key/sha256': dataset_util.bytes_feature(key.encode('utf8')),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature('jpeg'.encode('utf8')),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmin),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmax),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymin),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymax),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
'image/object/difficult': dataset_util.int64_list_feature(difficult_obj),
'image/object/truncated': dataset_util.int64_list_feature(truncated),
'image/object/view': dataset_util.bytes_list_feature(poses),
}))
return example
def main(_):
if FLAGS.set not in SETS:
raise ValueError('set must be in : {}'.format(SETS))
if FLAGS.year not in YEARS:
raise ValueError('year must be in : {}'.format(YEARS))
data_dir = FLAGS.data_dir
years = ['VOC2007', 'VOC2012']
if FLAGS.year != 'merged':
years = [FLAGS.year]
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
label_map_dict = label_map_util.get_label_map_dict(FLAGS.label_map_path)
for year in years:
logging.info('Reading from PASCAL %s dataset.', year)
examples_path = os.path.join(data_dir, year, 'ImageSets', 'Main',
FLAGS.set + '.txt')
annotations_dir = os.path.join(data_dir, year, FLAGS.annotations_dir)
examples_list = dataset_util.read_examples_list(examples_path)
for idx, example in enumerate(examples_list):
if idx % 4 == 0:
logging.info('On image %d of %d', idx, len(examples_list))
path = os.path.join(annotations_dir, example + '.xml')
with tf.gfile.GFile(path, 'r') as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = dataset_util.recursive_parse_xml_to_dict(xml)['annotation']
tf_example = dict_to_tf_example(data, FLAGS.data_dir , label_map_dict,
FLAGS.ignore_difficult_instances)
writer.write(tf_example.SerializeToString())
print(idx, " over!")
writer.close()
if __name__ == '__main__':
tf.app.run()
上面会生成测试集的record, 如下修改上面两处(将test改为train),运行即可生成训练集record
flags.DEFINE_string('set', 'train', 'Convert training set, validation set or '
'merged set.')
flags.DEFINE_string('output_path', '/home/sxhlvye/Trial2/test_object_detection/data/pascal_train.record', 'Path to output TFRecord')同理,如下,改为val后,运行即可生成验证集record
flags.DEFINE_string('set', 'val', 'Convert training set, validation set or '
'merged set.')
flags.DEFINE_string('output_path', '/home/sxhlvye/Trial2/test_object_detection/data/pascal_val.record', 'Path to output TFRecord')博主的record文件路径如下(结合自己的路径)

label_map.txt中的信息如下:
item {
id: 1
name: 'sidewalk'
}
3. 准备好预训练模型以及对应模型的config文件,上面第一个环节均用到了,将它们放入如下文件夹路径下:

4.修改ssd_resnet50_v1_fpn_640x640_coco17_tpu-8.config,里面的一些介绍可从官网去查看,这里说明下博主改了哪里
(1)num_classes改为了1

(2)fine_tune_checkpoint路径给下,type这块记得要改为detection
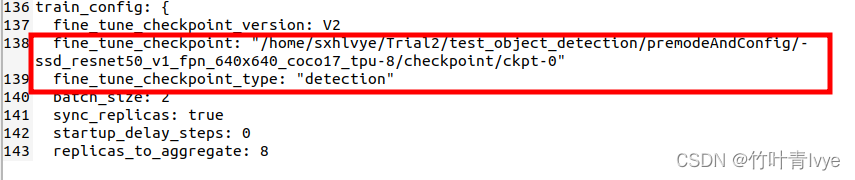
如上的batach_size修改为2,结合自己的gpu显存来设
(3)如下结合自己的路径修改下
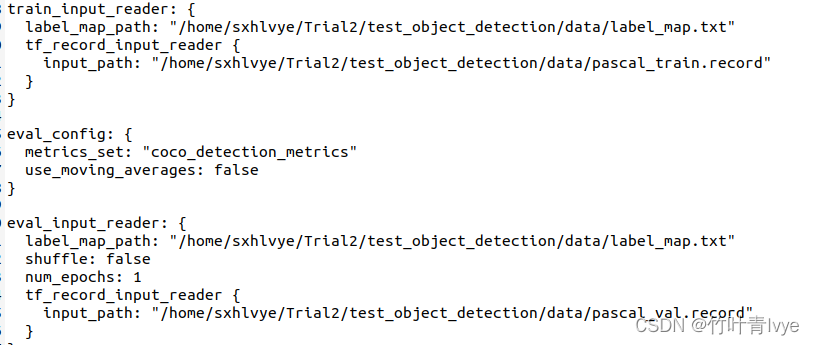
5. 创建一个文件夹用于保存自己训练的模型,博主这里取名为mycode

6.将上一环节所下载的models-master/research/object_detection的model_main_tf2.py拷贝走,后面会在此基础上做修改,博主工程test_object_detection目录结构如下:
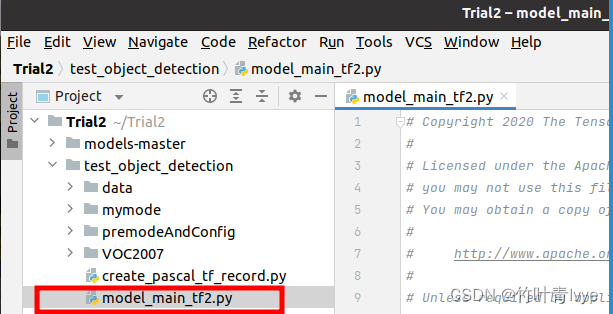
7.修改model_main_tf2.py中的代码如下:
# Copyright 2020 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
r"""Creates and runs TF2 object detection models.
For local training/evaluation run:
PIPELINE_CONFIG_PATH=path/to/pipeline.config
MODEL_DIR=/tmp/model_outputs
NUM_TRAIN_STEPS=10000
SAMPLE_1_OF_N_EVAL_EXAMPLES=1
python model_main_tf2.py -- \
--model_dir=$MODEL_DIR --num_train_steps=$NUM_TRAIN_STEPS \
--sample_1_of_n_eval_examples=$SAMPLE_1_OF_N_EVAL_EXAMPLES \
--pipeline_config_path=$PIPELINE_CONFIG_PATH \
--alsologtostderr
"""
from absl import flags
import tensorflow.compat.v2 as tf
from object_detection import model_lib_v2
flags.DEFINE_string('pipeline_config_path', '/home/sxhlvye/Trial2/test_object_detection/premodeAndConfig/ssd_resnet50_v1_fpn_640x640_coco17_tpu-8.config', 'Path to pipeline config '
'file.')
flags.DEFINE_integer('num_train_steps', None, 'Number of train steps.')
flags.DEFINE_bool('eval_on_train_data', False, 'Enable evaluating on train '
'data (only supported in distributed training).')
flags.DEFINE_integer('sample_1_of_n_eval_examples', None, 'Will sample one of '
'every n eval input examples, where n is provided.')
flags.DEFINE_integer('sample_1_of_n_eval_on_train_examples', 5, 'Will sample '
'one of every n train input examples for evaluation, '
'where n is provided. This is only used if '
'`eval_training_data` is True.')
flags.DEFINE_string(
'model_dir', '/home/sxhlvye/Trial2/test_object_detection/mymode', 'Path to output model directory '
'where event and checkpoint files will be written.')
flags.DEFINE_string(
'checkpoint_dir', '', 'Path to directory holding a checkpoint. If '
'`checkpoint_dir` is provided, this binary operates in eval-only mode, '
'writing resulting metrics to `model_dir`.')
flags.DEFINE_integer('eval_timeout', 3600, 'Number of seconds to wait for an'
'evaluation checkpoint before exiting.')
flags.DEFINE_bool('use_tpu', False, 'Whether the job is executing on a TPU.')
flags.DEFINE_string(
'tpu_name',
default=None,
help='Name of the Cloud TPU for Cluster Resolvers.')
flags.DEFINE_integer(
'num_workers', 1, 'When num_workers > 1, training uses '
'MultiWorkerMirroredStrategy. When num_workers = 1 it uses '
'MirroredStrategy.')
flags.DEFINE_integer(
'checkpoint_every_n', 1000, 'Integer defining how often we checkpoint.')
flags.DEFINE_boolean('record_summaries', True,
('Whether or not to record summaries defined by the model'
' or the training pipeline. This does not impact the'
' summaries of the loss values which are always'
' recorded.'))
FLAGS = flags.FLAGS
def main(unused_argv):
flags.mark_flag_as_required('model_dir')
flags.mark_flag_as_required('pipeline_config_path')
tf.config.set_soft_device_placement(True)
if FLAGS.checkpoint_dir:
print("start eval continuously")
model_lib_v2.eval_continuously(
pipeline_config_path=FLAGS.pipeline_config_path,
model_dir=FLAGS.model_dir,
train_steps=FLAGS.num_train_steps,
sample_1_of_n_eval_examples=FLAGS.sample_1_of_n_eval_examples,
sample_1_of_n_eval_on_train_examples=(
FLAGS.sample_1_of_n_eval_on_train_examples),
checkpoint_dir=FLAGS.checkpoint_dir,
wait_interval=300, timeout=FLAGS.eval_timeout)
print("over!")
else:
if FLAGS.use_tpu:
# TPU is automatically inferred if tpu_name is None and
# we are running under cloud ai-platform.
resolver = tf.distribute.cluster_resolver.TPUClusterResolver(
FLAGS.tpu_name)
tf.config.experimental_connect_to_cluster(resolver)
tf.tpu.experimental.initialize_tpu_system(resolver)
strategy = tf.distribute.experimental.TPUStrategy(resolver)
elif FLAGS.num_workers > 1:
strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy()
else:
strategy = tf.compat.v2.distribute.MirroredStrategy()
with strategy.scope():
print("start to train_loop")
model_lib_v2.train_loop(
pipeline_config_path=FLAGS.pipeline_config_path,
model_dir=FLAGS.model_dir,
train_steps=FLAGS.num_train_steps,
use_tpu=FLAGS.use_tpu,
checkpoint_every_n=FLAGS.checkpoint_every_n,
record_summaries=FLAGS.record_summaries)
print("over")
if __name__ == '__main__':
tf.compat.v1.app.run()
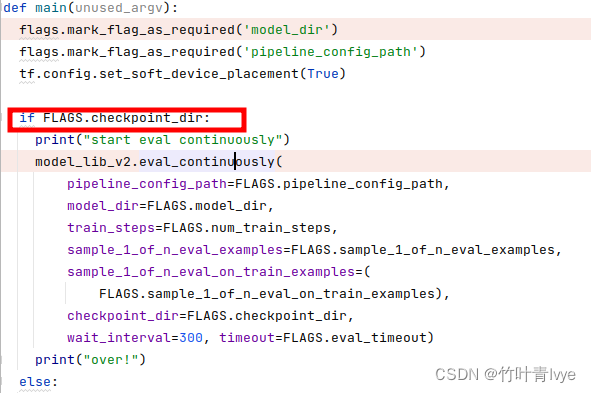
这边值得一提的是,如下给的值此时应该为空
flags.DEFINE_string(
'checkpoint_dir', '', 'Path to directory holding a checkpoint. If '
'`checkpoint_dir` is provided, this binary operates in eval-only mode, '
'writing resulting metrics to `model_dir`.')因为代码中有逻辑判断,如果有checkpoint时,会执行推断分支过程,而不是训练过程
运行如上py文件,开始训练,因为按照默认的config参数来的,所以会迭代25000次,耐心等待2~3小时。结束后,可看到训练效果还不错。

保存的模型如下:

8.通过tensorboard来查看训练过程日志
终端执行如下命令即可:
tensorboard --logdir=/home/sxhlvye/Trial2/test_object_detection/mymode

然后网页输入 http://localhost:6006/即可浏览
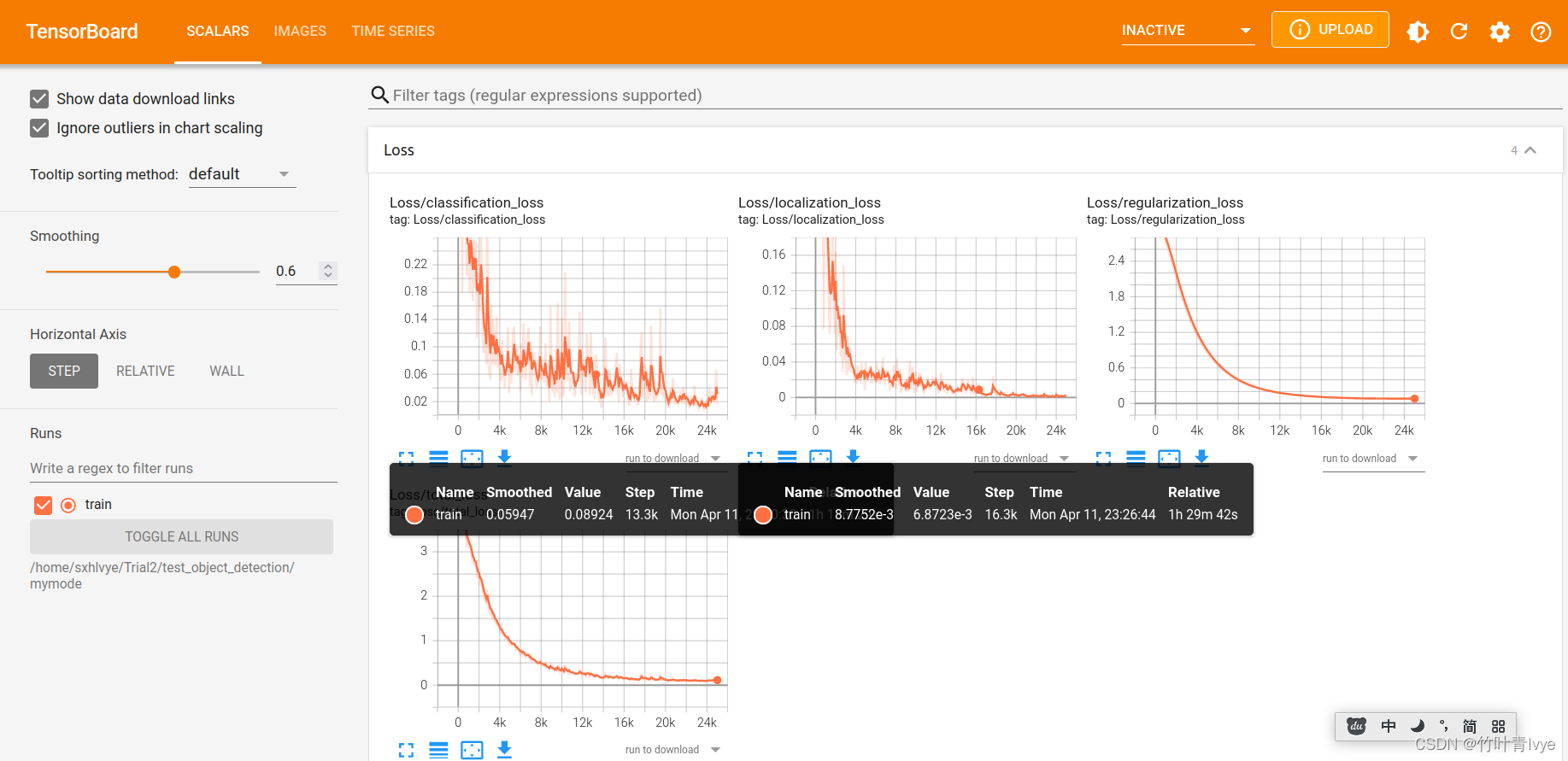
9.训练完毕后,开始进行预测,预测部分博主在源代码基础上增加了预测图片的结果保存,有需要的童鞋可以借鉴下
(1)预测还是继续执行上面的代码,model_main_tf2.py中的文件可以只修改此处,将训练完毕后模型所保存的目录代入进入,程序会用最近一次的模型去预测图片
flags.DEFINE_string(
'checkpoint_dir', '/home/sxhlvye/Trial2/test_object_detection/mymode', 'Path to directory holding a checkpoint. If '
'`checkpoint_dir` is provided, this binary operates in eval-only mode, '
'writing resulting metrics to `model_dir`.')(2) 同时修改前面所安装到python site-packages下的object_detection中的model_lib_v2.py文件

(3) 文末会附上该文件,主要增加代码之处如下,会将预测集里第一张图片的结果保存本地,而不是要到tensorboard中去查看。

(4)同时别忘了更改ssd_resnet50_v1_fpn_640x640_coco17_tpu-8.config中的一处,意思是让程序去加载测试集的record去跑下结果,因为在训练集和验证集上预测结果好,没有什么太大意义。

10.再次运行model_main_tf2.py文件,部分运行结果如下,博主加了统计预测时间的代码,一张图片在60ms左右。
tensorboar over!
i: 1
do inference cost:0.06209795s
INFO:tensorflow:Finished eval step 1
I0412 12:31:42.044180 139726501308224 model_lib_v2.py:1053] Finished eval step 1
tensorboar over!
i: 2
do inference cost:0.06254292s
INFO:tensorflow:Finished eval step 2
I0412 12:31:42.242587 139726501308224 model_lib_v2.py:1053] Finished eval step 2
tensorboar over!
i: 3
do inference cost:0.06211330s
INFO:tensorflow:Finished eval step 3
I0412 12:31:42.418719 139726501308224 model_lib_v2.py:1053] Finished eval step 3
tensorboar over!
i: 4
do inference cost:0.06145392s
INFO:tensorflow:Finished eval step 4
I0412 12:31:42.578115 139726501308224 model_lib_v2.py:1053] Finished eval step 4
tensorboar over!
i: 5
do inference cost:0.06143694s
INFO:tensorflow:Finished eval step 5
I0412 12:31:42.757224 139726501308224 model_lib_v2.py:1053] Finished eval step 5
tensorboar over!
i: 6
do inference cost:0.06659715s
INFO:tensorflow:Finished eval step 6
I0412 12:31:42.951520 139726501308224 model_lib_v2.py:1053] Finished eval step 6
tensorboar over!
i: 7
do inference cost:0.06043519s
INFO:tensorflow:Finished eval step 7
I0412 12:31:43.130409 139726501308224 model_lib_v2.py:1053] Finished eval step 7
tensorboar over!
start to eval_metrics
creating index...
index created!
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
INFO:tensorflow:Performing evaluation on 8 images.
I0412 12:31:43.239027 139726501308224 coco_evaluation.py:293] Performing evaluation on 8 images.
INFO:tensorflow:Loading and preparing annotation results...
I0412 12:31:43.239184 139726501308224 coco_tools.py:116] Loading and preparing annotation results...
INFO:tensorflow:DONE (t=0.00s)
I0412 12:31:43.240644 139726501308224 coco_tools.py:138] DONE (t=0.00s)
DONE (t=0.03s).
Accumulating evaluation results...
DONE (t=0.01s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.483
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 1.000
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.548
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.485
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.562
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.650
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.662
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.662
evalute!
eval loop over
INFO:tensorflow:Eval metrics at step 25000
I0412 12:31:43.281148 139726501308224 model_lib_v2.py:1106] Eval metrics at step 25000
INFO:tensorflow: + DetectionBoxes_Precision/mAP: 0.483213
I0412 12:31:43.282772 139726501308224 model_lib_v2.py:1109] + DetectionBoxes_Precision/mAP: 0.483213
INFO:tensorflow: + DetectionBoxes_Precision/mAP@.50IOU: 1.000000
I0412 12:31:43.283632 139726501308224 model_lib_v2.py:1109] + DetectionBoxes_Precision/mAP@.50IOU: 1.000000
INFO:tensorflow: + DetectionBoxes_Precision/mAP@.75IOU: 0.547855
I0412 12:31:43.285666 139726501308224 model_lib_v2.py:1109] + DetectionBoxes_Precision/mAP@.75IOU: 0.547855
INFO:tensorflow: + DetectionBoxes_Precision/mAP (small): -1.000000
I0412 12:31:43.286555 139726501308224 model_lib_v2.py:1109] + DetectionBoxes_Precision/mAP (small): -1.000000
INFO:tensorflow: + DetectionBoxes_Precision/mAP (medium): -1.000000
I0412 12:31:43.287268 139726501308224 model_lib_v2.py:1109] + DetectionBoxes_Precision/mAP (medium): -1.000000
INFO:tensorflow: + DetectionBoxes_Precision/mAP (large): 0.484896
I0412 12:31:43.288106 139726501308224 model_lib_v2.py:1109] + DetectionBoxes_Precision/mAP (large): 0.484896
INFO:tensorflow: + DetectionBoxes_Recall/AR@1: 0.562500
I0412 12:31:43.288901 139726501308224 model_lib_v2.py:1109] + DetectionBoxes_Recall/AR@1: 0.562500
INFO:tensorflow: + DetectionBoxes_Recall/AR@10: 0.650000
I0412 12:31:43.289659 139726501308224 model_lib_v2.py:1109] + DetectionBoxes_Recall/AR@10: 0.650000
INFO:tensorflow: + DetectionBoxes_Recall/AR@100: 0.662500
I0412 12:31:43.290457 139726501308224 model_lib_v2.py:1109] + DetectionBoxes_Recall/AR@100: 0.662500
INFO:tensorflow: + DetectionBoxes_Recall/AR@100 (small): -1.000000
I0412 12:31:43.291078 139726501308224 model_lib_v2.py:1109] + DetectionBoxes_Recall/AR@100 (small): -1.000000
INFO:tensorflow: + DetectionBoxes_Recall/AR@100 (medium): -1.000000
I0412 12:31:43.291646 139726501308224 model_lib_v2.py:1109] + DetectionBoxes_Recall/AR@100 (medium): -1.000000
INFO:tensorflow: + DetectionBoxes_Recall/AR@100 (large): 0.662500
I0412 12:31:43.292283 139726501308224 model_lib_v2.py:1109] + DetectionBoxes_Recall/AR@100 (large): 0.662500
INFO:tensorflow: + Loss/localization_loss: 0.231716
I0412 12:31:43.292888 139726501308224 model_lib_v2.py:1109] + Loss/localization_loss: 0.231716
INFO:tensorflow: + Loss/classification_loss: 0.440314
I0412 12:31:43.293469 139726501308224 model_lib_v2.py:1109] + Loss/classification_loss: 0.440314
INFO:tensorflow: + Loss/regularization_loss: 0.081252
I0412 12:31:43.294081 139726501308224 model_lib_v2.py:1109] + Loss/regularization_loss: 0.081252
INFO:tensorflow: + Loss/total_loss: 0.753282
I0412 12:31:43.294680 139726501308224 model_lib_v2.py:1109] + Loss/total_loss: 0.753282
eager_eval_loop over!
summary!
global_step.numpy(): 25000
configs['train_config'].num_steps: 25000
over!
Process finished with exit code 0
第一张图片保存了预测结果,我们来看看是啥样,还是挺不错的,分数也挺高

再用tensorboar去看看预测集结果,每次预测完毕后都event事件都会写在eval文件夹里

还是输入此命令去查看
tensorboard --logdir=/home/sxhlvye/Trial2/test_object_detection/mymode
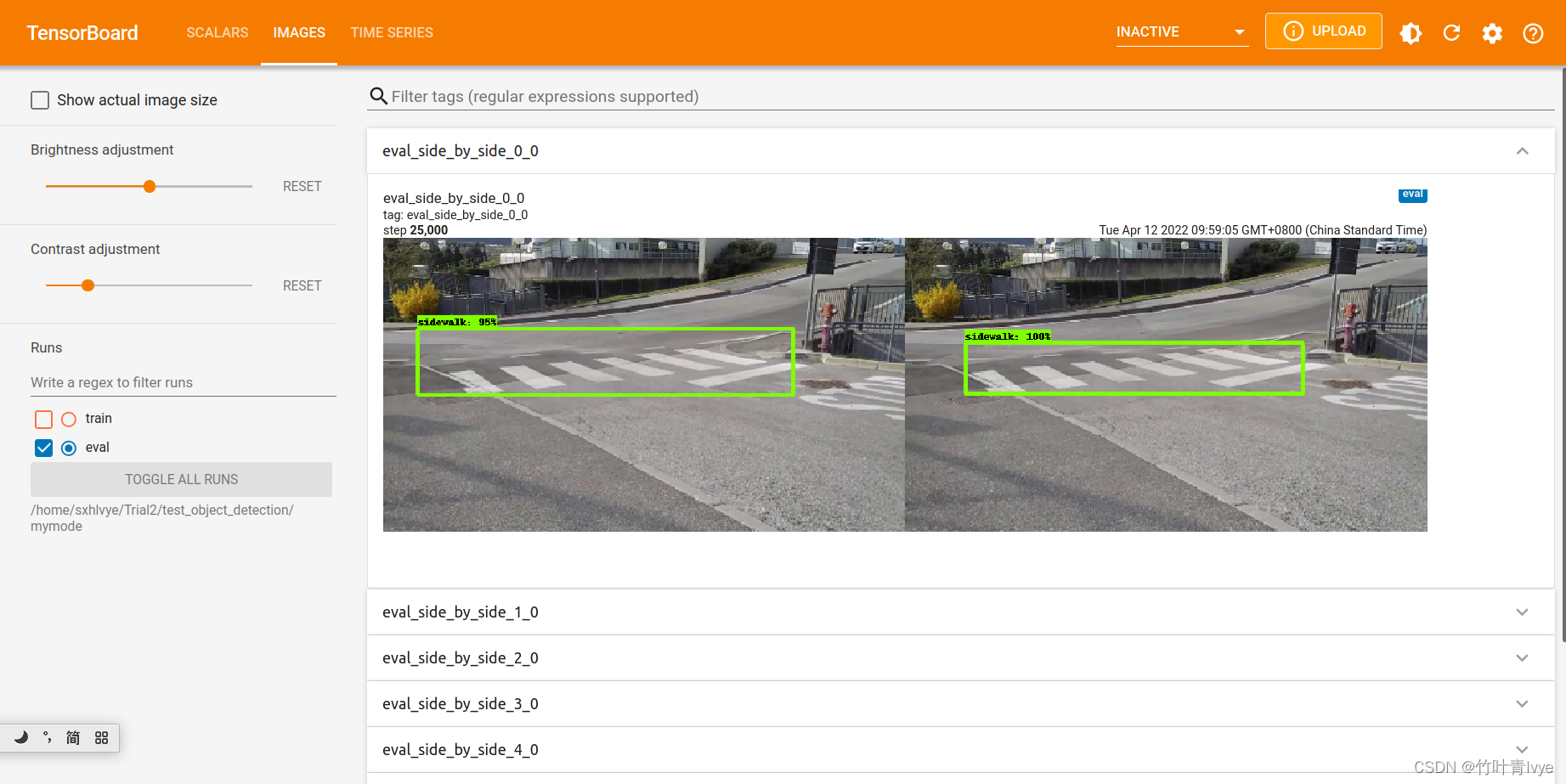
到此,训练预测自己的数据集就完毕了!
博主工程路径如下:
链接: https://pan.baidu.com/s/1Nj76vvSj0i_2gN7IaAoRAA 提取码: dxev
博客中提到的model_main_tf2.py文件如下
链接: https://pan.baidu.com/s/1RZs2J1TVIQi-QjItKb0JtA 提取码: rgo5
补充:
博主这边也尝试了下轻量级网络模型mobilenet
models/tf2_detection_zoo.md at master · tensorflow/models · GitHub
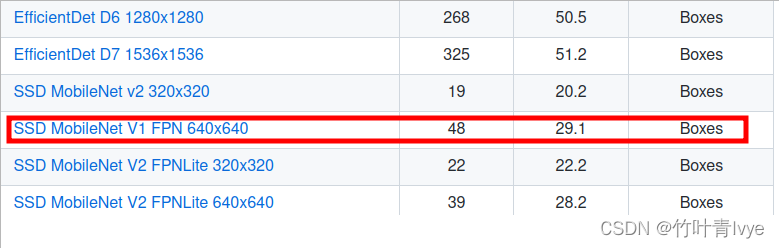

训练预测方式参考如上,训练完毕部分信息如下:

对相同的图片进行预测,信息如下:
tensorboar over!
i: 1
do inference cost:0.03755847s
INFO:tensorflow:Finished eval step 1
I0416 23:25:55.263175 140056523752256 model_lib_v2.py:1053] Finished eval step 1
tensorboar over!
i: 2
do inference cost:0.04484537s
INFO:tensorflow:Finished eval step 2
I0416 23:25:55.408541 140056523752256 model_lib_v2.py:1053] Finished eval step 2
tensorboar over!
i: 3
do inference cost:0.03724565s
INFO:tensorflow:Finished eval step 3
I0416 23:25:55.547942 140056523752256 model_lib_v2.py:1053] Finished eval step 3
tensorboar over!
i: 4
do inference cost:0.04007730s
INFO:tensorflow:Finished eval step 4
I0416 23:25:55.675304 140056523752256 model_lib_v2.py:1053] Finished eval step 4
tensorboar over!
i: 5
do inference cost:0.04049982s
INFO:tensorflow:Finished eval step 5
I0416 23:25:55.811226 140056523752256 model_lib_v2.py:1053] Finished eval step 5
tensorboar over!
i: 6
do inference cost:0.03766041s
INFO:tensorflow:Finished eval step 6
I0416 23:25:55.953728 140056523752256 model_lib_v2.py:1053] Finished eval step 6
tensorboar over!
i: 7
do inference cost:0.03949502s
INFO:tensorflow:Finished eval step 7
I0416 23:25:56.096909 140056523752256 model_lib_v2.py:1053] Finished eval step 7
tensorboar over!

ct要比上面模型快,约40ms,检测结果也是正确的,且得分为100%















 1918
1918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











