






1.摘要
最大期望算法(Expectation-Maximum algorithm, EM)也称期望最大化算法,是一类通过迭代进行极大似然估计的优化算法,是著名的数据挖掘十大算法之一,在机器学习、数据挖掘中具有一定的影响力。EM算法是最常见的隐变量估计方法,被广泛应用于很多机器学习中,包括高斯混合模型(Gaussian mixture model,GMM),和隐式马尔科夫算法(Hidden Markov Model, HMM)的参数估计等。
2.EM算法简介
EM算法是一种通过不断迭代来进行优化的策略,计算方法中每一次迭代分为两步,其中一步为期望步(E步),另一种为极大步(M步),因此被称为EM算法。EM算法是为了解决数据缺失情况下的参数估计问题而提出的,基本思想是:首先根据已经得到的观测数据来估计出模型参数的值,然后根据上一步估计出的参数估计值来估计缺失数据的值,再讲估计出的损失数据与以及得到的观测数据进行对比,以此来重新对参数值进行估计,不断反复迭代,直至收敛,迭代结束,返回结果。
3.预备知识
3.1贝叶斯公式
贝叶斯定理是关于随机事件A和B的条件概率(或边缘概率)的一则定理。其中P(A|B)是在B发生的情况下A发生的可能性。贝叶斯公式为:
P
(
B
i
∣
A
)
=
P
(
B
i
)
P
(
A
∣
B
i
)
∑
j
=
1
n
P
(
B
j
)
P
(
A
∣
B
j
)
P(B_i|A)=\cfrac{P(B_i)P(A|B_i)}{\sum_{j=1}^nP(B_j)P(A|B_j)}
P(Bi∣A)=∑j=1nP(Bj)P(A∣Bj)P(Bi)P(A∣Bi)
3.2 极大似然估计
3.2.1似然函数
对于函数 l ( θ ) = P ( x ∣ θ ) l(\theta)=P(x|θ) l(θ)=P(x∣θ),x表示某一个具体的数据, θ \theta θ表示模型的参数。在似然函数中,x是已知确定的, θ \theta θ是变量,它描述对于不同的模型参数,出现x这个样本点的概率是多少。
3.2.2问题描述
假如有一个罐子,里面有红白两种颜色的球,数目多少不知,两种颜色的比例也不知。目的是得到罐中红球和白球的比例,但不能把罐中的球全部拿出来数。现在我们可以每次任意从已经摇匀的罐中拿一个球出来,记录球的颜色,然后把拿出来的球再放回罐中。这个过程可以重复,我们可以用记录的球的颜色来估计罐中红白球的比例。假如在前面的十次次重复记录中,有七次是白球,请问罐中白球所占的比例最有可能是多少?
我们可以假设白球的比例是θ,那红球的比例是1-θ。因为每抽一个球出来,在记录颜色之后,我们把抽出的球放回了罐中并摇匀,所以每次抽出来的球的颜 色服从同一独立分布。
把一次抽出来球的颜色称为一次抽样。题目中在十次次抽样中,七次是白球的,三次为黑球事件的概率是P(样本结果|θ)。
如果第一次抽象的结果记为x1,第二次抽样的结果记为x2…那么样本结果为(x1,x2…,x10)。这样,我们可以得到表达式:
L
(
θ
)
=
P
(
样
本
结
果
∣
θ
)
L(θ)=P(样本结果|θ)
L(θ)=P(样本结果∣θ)
=
P
(
x
1
,
x
2
,
…
,
x
10
∣
θ
)
= P(x1,x2,…,x10|θ)
=P(x1,x2,…,x10∣θ)
=
P
(
x
1
∣
θ
)
P
(
x
2
∣
θ
)
…
P
(
x
10
∣
θ
)
= P(x1|θ)P(x2|θ)…P(x10|θ)
=P(x1∣θ)P(x2∣θ)…P(x10∣θ)
=
θ
7
(
1
−
θ
)
3
= θ^7(1-θ)^3
=θ7(1−θ)3
这是个关于的函数。而极大似然估计,就是要找到一个
θ
\theta
θ,使对应的
l
(
θ
)
l(θ)
l(θ)最大:
θ
^
=
arg max
l
(
θ
)
\hat{\theta}=\argmax l(θ)
θ^=argmaxl(θ)
3.2.3极大似然函数估计值的求解步骤
首先,写出似然函数:
L
(
θ
)
=
L
(
x
1
,
x
2
,
.
.
.
,
x
n
∣
θ
)
=
∏
i
=
1
n
p
(
x
i
∣
θ
)
,
θ
∈
Θ
L(\theta)=L(x_1,x_2,...,x_n|\theta)=\prod\limits_{i=1}^np(x_i|\theta),\theta\in\Theta
L(θ)=L(x1,x2,...,xn∣θ)=i=1∏np(xi∣θ),θ∈Θ
其次,对似然函数取对数:
l
(
θ
)
=
l
o
g
L
(
x
1
,
x
2
,
.
.
.
,
x
n
∣
θ
)
=
l
o
g
∏
i
=
1
n
p
(
x
i
∣
θ
)
=
∑
i
=
1
n
l
o
g
p
(
x
i
∣
θ
)
l(\theta)=logL(x_1,x_2,...,x_n|\theta)=log\prod\limits_{i=1}^np(x_i|\theta)=\sum\limits_{i=1}^nlogp(x_i|\theta)
l(θ)=logL(x1,x2,...,xn∣θ)=logi=1∏np(xi∣θ)=i=1∑nlogp(xi∣θ)
然后对上式求导,另导数为0,得到似然方程。
最后,解似然方程,得到的参数值即为所求。
3.3Jensen不等式(琴生不等式)
3.3.1定义
设f是定义域为实数的函数,如果对所有的实数x,f(x)的二阶导数都大于0,那么f是凸函数。
Jensen不等式定义如下:
如果f是凸函数,X是随机变量,那么: E[f(X)]>=f(E[x]) 。当且仅当X是常量时,该式取等号。其中,E(X)表示X的数学期望。
注:Jensen不等式应用于凹函数时,不等号方向反向。当且仅当x是常量时,该不等式取等号。
3.3.2举例

图3-1
图3-1中,实线f表示凸函数,X是随机变量,有0.5的概率是a,有0.5的概率是b。X的期望值就是a和b的中值,从图中可以看到E[f(X)]>=f(E[x])成立。
4.EM算法详解
4.1问题描述
有两个袋子A和B,里面各有红球和白球,进行随机抽样,每次抽样先随机抽取一个袋子,再随机抽取一个球。每一次抽取到的球都不知道是从哪个袋子中抽取的,这个时候需要估计的是,这个球来自哪一个袋子,每个袋子的红球和白球的比例是多少,如图4-1。对于具体的问题使用EM算法求解步骤如图4-2所示:
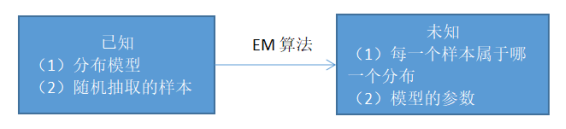
图4-1EM算法要解决的问题

图4-2 EM算法求解步骤
4.2EM算法公式及推导
4.2.1EM公式
E步:计算联合分布的条件概率期望:
Q
i
(
z
i
)
=
p
(
z
i
∣
x
i
,
θ
t
)
Q_i(z_i)=p(z_i|x_i,\theta_t)
Qi(zi)=p(zi∣xi,θt)
l
(
θ
,
θ
t
)
=
∑
i
=
1
n
∑
z
i
Q
i
(
z
i
)
l
o
g
p
(
x
i
,
z
i
∣
θ
)
Q
i
(
z
i
)
l(\theta,\theta_t)=\sum\limits_{i=1}^n\sum\limits_{z_i}Q_i(z_i)log\cfrac{p(x_i,z_i|\theta)}{Qi(z_i)}
l(θ,θt)=i=1∑nzi∑Qi(zi)logQi(zi)p(xi,zi∣θ)
M步:极大化
l
(
θ
,
θ
t
)
l(θ,θ_t)
l(θ,θt),得到θ_{t+1}:
θ
t
+
1
=
a
r
g
m
a
x
l
(
θ
,
θ
t
)
\theta_{t+1}=argmax l(\theta,\theta_t)
θt+1=argmaxl(θ,θt)
4.2.2EM公式导出
对于n个样本观察数据x=(x1,x2,…,xn),找出样本的模型参数θ, 极大化模型分布的对数似然函数:
l
(
θ
)
=
∑
i
=
1
n
l
o
g
p
(
x
i
∣
θ
)
l(\theta)=\sum\limits_{i=1}^n log p(x_i|\theta)
l(θ)=i=1∑nlogp(xi∣θ)
θ
^
=
a
r
g
m
a
x
∑
i
=
1
n
l
o
g
p
(
x
i
∣
θ
)
\hat{\theta}=argmax\sum\limits_{i=1}^n log p(x_i|\theta)
θ^=argmaxi=1∑nlogp(xi∣θ)
如果将得到的观察数据有未观察到的隐含数据
z
=
(
z
1
,
z
2
,
.
.
.
,
z
n
)
z=(z_1,z_2,...,z_n)
z=(z1,z2,...,zn),即上文中每个样本来自哪个分布是未知的,此时有极大化模型分布的对数似然函数:
θ
^
=
a
r
g
m
a
x
∑
i
=
1
n
l
o
g
p
(
x
i
∣
θ
)
=
a
r
g
m
a
x
∑
i
=
1
n
l
o
g
∑
z
i
p
(
x
i
,
z
i
∣
θ
)
\hat{\theta}=argmax\sum\limits_{i=1}^n log p(x_i|\theta)=argmax\sum\limits_{i=1}^n log \sum\limits_{z_i}p(x_i,z_i|\theta)
θ^=argmaxi=1∑nlogp(xi∣θ)=argmaxi=1∑nlogzi∑p(xi,zi∣θ)
使用Jensen不等式对这个式子进行缩放,分子分母同乘以一个未知分布Qi(zi)其中log(x)为凹函数:
∑
i
=
1
n
l
o
g
∑
z
i
p
(
x
i
,
z
i
∣
θ
)
=
∑
i
=
1
n
l
o
g
∑
z
i
Q
i
(
z
i
)
p
(
x
i
,
z
i
∣
θ
)
Q
i
(
z
i
)
(
1
)
\sum\limits_{i=1}^n log \sum\limits_{z_i}p(x_i,z_i|\theta)=\sum\limits_{i=1}^n log \sum\limits_{z_i}Q_i(z_i)\cfrac{p(x_i,z_i|\theta)}{Q_i(z_i)}\quad(1)
i=1∑nlogzi∑p(xi,zi∣θ)=i=1∑nlogzi∑Qi(zi)Qi(zi)p(xi,zi∣θ)(1)
≥
∑
i
=
1
n
∑
z
i
Q
i
(
z
i
)
l
o
g
p
(
x
i
,
z
i
∣
θ
)
Q
i
(
z
i
)
(
2
)
\qquad\qquad\quad\quad\quad\quad\ge\sum\limits_{i=1}^n \sum\limits_{z_i}Q_i(z_i)log\cfrac{p(x_i,z_i|\theta)}{Q_i(z_i)}\quad(2)
≥i=1∑nzi∑Qi(zi)logQi(zi)p(xi,zi∣θ)(2)
此时可以得到
l
o
g
l
(
θ
)
log l(θ)
logl(θ)的下界。在
θ
θ
θ已经给定的条件下,
l
o
g
l
(
θ
)
log l(θ)
logl(θ)的值取决于
Q
i
(
z
i
)
Q_i(z_i)
Qi(zi)和
p
(
x
i
,
z
i
∣
θ
)
p(x_i,z_i|θ)
p(xi,zi∣θ)。我们可以通过调整这两个概率来使
l
o
g
l
(
θ
)
log l(θ)
logl(θ)的下界不断上升,来毕竟
l
o
g
l
(
θ
)
log l(θ)
logl(θ)的真实值。当
∑
i
=
1
n
l
o
g
∑
z
i
p
(
x
i
,
z
i
∣
θ
)
≥
∑
i
=
1
n
∑
z
i
Q
i
(
z
i
)
l
o
g
p
(
x
i
,
z
i
∣
θ
)
Q
i
(
z
i
)
\sum\limits_{i=1}^n log \sum\limits_{z_i}p(x_i,z_i|\theta)\ge\sum\limits_{i=1}^n \sum\limits_{z_i}Q_i(z_i)log\cfrac{p(x_i,z_i|\theta)}{Q_i(z_i)}
i=1∑nlogzi∑p(xi,zi∣θ)≥i=1∑nzi∑Qi(zi)logQi(zi)p(xi,zi∣θ)变成等式时,即可说明调整后的概率等价于
l
o
g
l
(
θ
)
log l(θ)
logl(θ)。
等式成立时,有:
p
(
x
i
,
z
i
∣
θ
)
Q
i
(
z
i
)
=
c
,
c
为
常
数
\cfrac{p(x_i,z_i|\theta)}{Q_i(z_i)}=c,c为常数
Qi(zi)p(xi,zi∣θ)=c,c为常数
由于
Q
i
(
z
i
)
Q_i(z_i)
Qi(zi)是一个分布,所以满足
∑
z
Q
i
(
z
i
)
=
1
\sum\limits_{z}Q_i(z_i)=1
z∑Qi(zi)=1和
∑
z
p
(
x
i
,
z
i
∣
θ
)
=
c
\sum\limits_{z}p(x_i,z_i|\theta)=c
z∑p(xi,zi∣θ)=c。
可得:
∑
z
Q
i
(
z
i
)
=
p
(
x
i
,
z
i
∣
θ
)
∑
z
p
(
x
i
,
z
i
∣
θ
)
=
p
(
x
i
,
z
i
∣
θ
)
p
(
x
i
∣
θ
)
=
p
(
z
i
∣
x
i
,
θ
)
\sum\limits_{z}Q_i(z_i)=\cfrac{p(x_i,z_i|\theta)}{\sum\limits_{z}p(x_i,z_i|\theta)}=\cfrac{p(x_i,z_i|\theta)}{p(x_i|\theta)}=p(z_i|x_i,\theta)
z∑Qi(zi)=z∑p(xi,zi∣θ)p(xi,zi∣θ)=p(xi∣θ)p(xi,zi∣θ)=p(zi∣xi,θ)
由此可知道
Q
i
(
z
i
)
Q_i(z_i)
Qi(zi)由后验概率计算得出。由此在得到
Q
i
(
z
i
)
Q_i(z_i)
Qi(zi)后,调整
θ
θ
θ,去极大化
l
(
θ
)
l(θ)
l(θ)的下界,来得到更优的
θ
θ
θ。
4.3EM算法流程
4.3.1输入
n个样本观察数据 x = ( x 1 , x 2 , . . . , x n ) x=(x_1,x_2,...,x_n) x=(x1,x2,...,xn),初始化 θ θ θ值,联合分布 p ( x , z ∣ θ ) p(x,z|θ) p(x,z∣θ),条件分布 p ( z ∣ x , θ ) p(z|x,θ) p(z∣x,θ),最大迭代次数maxiteration。
4.3.2算法步骤
(1)随机初始化模型参数
θ
θ
θ。
(2)t=1,2,…,maxiteration开始迭代:
(3)E步:计算联合分布的条件概率期望。
Q
i
(
z
i
)
=
p
(
z
i
∣
x
i
,
θ
t
)
Q_i(z_i)=p(z_i|x_i,\theta_t)
Qi(zi)=p(zi∣xi,θt)
l
(
θ
,
θ
t
)
=
∑
i
=
1
n
∑
z
i
Q
i
(
z
i
)
l
o
g
p
(
x
i
,
z
i
∣
θ
)
Q
i
(
z
i
)
l(\theta,\theta_t)=\sum\limits_{i=1}^n\sum\limits_{z_i}Q_i(z_i)log\cfrac{p(x_i,z_i|\theta)}{Qi(z_i)}
l(θ,θt)=i=1∑nzi∑Qi(zi)logQi(zi)p(xi,zi∣θ)
(4)M步:极大化l(θ,θt),得到θt+1。
θ
t
+
1
=
a
r
g
m
a
x
l
(
θ
,
θ
t
)
\theta_{t+1}=argmax l(\theta,\theta_t)
θt+1=argmaxl(θ,θt)
(5)当θt+1已经收敛时,结束并输出结果,否则继续进行(2)和(3)进行迭代。
4.3.3输出
最后输出迭代得到的参数θ。
5.EM算法的简单实现
5.1问题及实现描述
有两个袋子A和B,里面各有红球和白球若干个,进行随机抽样,每次抽样先随机抽取一个袋子,再随机抽取一个球。每一次抽取到的球都不知道是从哪个袋子中抽取的,这个时候需要估计的是,这个球来自哪一个袋子,每个袋子的红球和白球的比例是多少。
我们可以对样本随机抽样,得到x1,x2,…,xn,将选定A袋子的概率记为w,选定B的概率记为1-w。A袋子红球和白球的比例记为p和1-p,B袋子红球和白球的比例记为q和1-q。通过样本x1,x2,…,xn使用极大似然估计来估计w、p和q。记取到红球为1,取到白球为0,一共取十次,得到的结果为x=[1,1,0,1,0,0,1,0,1,1]。
设Z来表示球来自于哪个袋子,
Z
=
z
1
,
z
2
,
.
.
.
,
z
1
0
Z={z_1,z_2,...,z_10}
Z=z1,z2,...,z10,令θ={w,p,q}。
取出一个球的概率为:
P
(
x
∣
θ
)
=
w
p
x
(
1
−
p
)
1
−
x
+
(
1
−
w
)
q
x
(
1
−
q
)
1
−
x
P(x|\theta)=wp^x(1-p)^{1-x}+(1-w)q^x(1-q)^{1-x}
P(x∣θ)=wpx(1−p)1−x+(1−w)qx(1−q)1−x
可得极大似然函数的对数:
l
(
θ
)
=
l
o
g
P
(
x
∣
θ
)
=
∑
i
=
1
n
l
o
g
[
w
p
x
i
(
1
−
p
)
1
−
x
i
+
(
1
−
w
)
q
x
i
(
1
−
q
)
1
−
x
i
]
l(\theta)=logP(x|\theta)=\sum\limits_{i=1}^nlog[wp^{x_i}(1-p)^{1-x_i}+(1-w)q^{x_i}(1-q)^{1-x_i}]
l(θ)=logP(x∣θ)=i=1∑nlog[wpxi(1−p)1−xi+(1−w)qxi(1−q)1−xi]
可得似然函数最大值θ。
E步:假设当前模型的参数为θ={w,p,q}时,计算后验概率:
A
:
μ
=
P
(
Z
∣
X
θ
)
=
w
p
x
i
(
1
−
p
)
1
−
x
i
w
p
x
i
(
1
−
p
)
1
−
x
i
+
(
1
−
w
)
q
x
i
(
1
−
q
)
1
−
x
i
A:\mu=P(Z|X\theta)=\cfrac{wp^{x_i}(1-p)^{1-x_i}}{wp^{x_i}(1-p)^{1-x_i}+(1-w)q^{x_i}(1-q)^{1-x_i}}
A:μ=P(Z∣Xθ)=wpxi(1−p)1−xi+(1−w)qxi(1−q)1−xiwpxi(1−p)1−xi
B
:
1
−
μ
B:1-\mu
B:1−μ
M步:将μ看做固定值,写出后验概率的期望,并分别求偏导,得到新的参数θ={w,p,q}:
E
Z
∣
X
,
θ
(
L
(
θ
∣
X
,
Z
)
)
=
∑
i
=
1
n
[
μ
l
o
g
w
p
x
i
(
1
−
p
)
1
−
x
i
μ
+
(
1
−
μ
)
l
o
g
(
1
−
w
)
q
x
i
(
1
−
q
)
1
−
x
i
1
−
μ
]
(
1
)
E_{Z|X,\theta}(L(\theta|X,Z))=\sum\limits_{i=1}^n[\mu log\cfrac{wp^{x_i}(1-p)^{1-x_i}}{\mu}+(1-\mu)log\cfrac{(1-w)q^{x_i}(1-q)^{1-x_i}}{1-\mu}]\quad(1)
EZ∣X,θ(L(θ∣X,Z))=i=1∑n[μlogμwpxi(1−p)1−xi+(1−μ)log1−μ(1−w)qxi(1−q)1−xi](1)
w
=
1
n
∑
i
=
1
n
μ
i
(
2
)
w=\cfrac{1}{n}\sum\limits_{i=1}^n\mu_i\quad(2)
w=n1i=1∑nμi(2)
p
=
∑
i
=
1
n
μ
i
x
i
∑
i
=
1
n
μ
i
(
3
)
p=\cfrac{\sum\limits_{i=1}^n\mu_ix_i}{\sum\limits_{i=1}^n\mu_i}\quad(3)
p=i=1∑nμii=1∑nμixi(3)
q
=
∑
i
=
1
n
(
1
−
μ
i
)
x
i
∑
i
=
1
n
(
1
−
μ
i
)
(
4
)
q=\cfrac{\sum\limits_{i=1}^n(1-\mu_i)x_i}{\sum\limits_{i=1}^n(1-\mu_i)}\quad(4)
q=i=1∑n(1−μi)i=1∑n(1−μi)xi(4)
5.2 代码实现及结果
先定义E步和M步:
import math
def cal_mu(w,p,q,xi):
return w * math.pow(p, xi) * math.pow(1 - p, 1 - xi) / \
float(w * math.pow(p, xi) * math.pow(1 - p, 1 - xi) +
(1 - w) * math.pow(q, xi) * math.pow(1 - q, 1 - xi))
def e_step(w,p,q,x):
mu=[cal_mu(w,p,q,xi) for xi in x]
return mu
def m_step(mu,x):
w=sum(mu)/len(mu)
p=sum([mu[i]*x[i] for i in range(len(mu))])/sum(mu)
q=sum([(1-mu[i])*x[i] for i in range(len(mu))])/\
sum([1-mu[i] for i in range(len(mu))])
return [w,p,q]
再定义迭代过程,输入参数,返回结果:
def run(x,w,p,q,maxiteration):
for i in range(maxiteration):
mu=e_step(w,p,q,x)
print(i,[w,p,q])
if [w,p,q]==m_step(mu,x):
break
else:
[w,p,q]=m_step(mu,x)
print([w,p,q])
if __name__=="__main__":
x = [1, 1, 0, 1, 0, 0, 1, 0, 1, 1]
[w,p,q]=[0.4,0.6,0.7]
run(x,w,p,q,100)
结果:
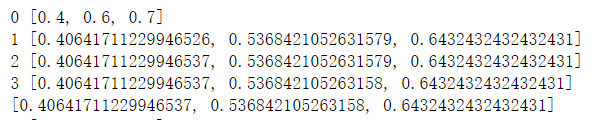
6.EM算法收敛性
当
θ
θ
θ取到
θ
t
θ_t
θt时,可得:
θ
t
+
1
=
arg max
θ
∑
j
=
1
n
∑
i
Q
j
t
(
z
i
)
l
o
g
P
(
y
j
,
z
i
∣
θ
)
Q
j
t
(
z
i
)
\theta^{t+1}=\argmax\limits_\theta \sum\limits_{j=1}^n\sum\limits_iQ_j^t(z_i)log\cfrac{P(y_j,z_i|\theta)}{Q_j^t(z_i)}
θt+1=θargmaxj=1∑ni∑Qjt(zi)logQjt(zi)P(yj,zi∣θ)
l
(
θ
t
+
1
)
=
∑
j
=
1
n
l
o
g
∑
i
Q
j
t
(
z
i
)
P
(
y
j
,
z
i
∣
θ
t
+
1
)
Q
j
t
(
z
i
)
(
1
)
l(\theta_{t+1})=\sum\limits_{j=1}^nlog\sum\limits_iQ_j^t(z_i)\cfrac{P(y_j,z_i|\theta^{t+1})}{Q_j^t(z_i)}\qquad(1)
l(θt+1)=j=1∑nlogi∑Qjt(zi)Qjt(zi)P(yj,zi∣θt+1)(1)
≥
∑
j
=
1
n
∑
i
Q
j
t
(
z
i
)
l
o
g
P
(
y
j
,
z
i
∣
θ
t
+
1
)
Q
j
t
(
z
i
)
(
2
)
\quad\qquad \ge\sum\limits_{j=1}^n\sum\limits_iQ_j^t(z_i)log\cfrac{P(y_j,z_i|\theta^{t+1})}{Q_j^t(z_i)}\qquad(2)
≥j=1∑ni∑Qjt(zi)logQjt(zi)P(yj,zi∣θt+1)(2)
≥
∑
j
=
1
n
∑
i
Q
j
t
(
z
i
)
l
o
g
P
(
y
j
,
z
i
∣
θ
t
)
Q
j
t
(
z
i
)
(
3
)
\quad\qquad \ge\sum\limits_{j=1}^n\sum\limits_iQ_j^t(z_i)log\cfrac{P(y_j,z_i|\theta^t)}{Q_j^t(z_i)}\quad\qquad(3)
≥j=1∑ni∑Qjt(zi)logQjt(zi)P(yj,zi∣θt)(3)
式(2)是根据Jensen不等式得来的,由于 θ t + 1 θ_{t+1} θt+1不一定等于 θ t θ_{t} θt,故等号不一定成立。由于 θ t + 1 θ_{t+1} θt+1使得似然函数取最大值,可得式(3)。由此得出 l ( θ ) l(θ) l(θ)在迭代下是递增的,根据单调有界收敛可得 l ( θ ) l(θ) l(θ)有上界,故EM算法可以保证收敛到一个稳定点,但是却不能保证收敛到全局的极大值点,因此它是局部最优的算法。
7.EM算法的优缺点
7.1优点
具有简单性和普适性,可看作是一种非梯度优化方法。
7.2缺点
EM算法对初始值敏感,EM算法需要初始化参数θ,而参数θ的选择直接影响收敛效率以及能否得到全局最优解。且EM算法不能保证找到全局最优值。
在5.2的代码实现及结果中,采用不同的初始值,得到的结果如图7-1:

图7-1
8.EM算法的应用
8.1K-means
K-means的目标是将样本集划分为K个簇,同一个簇内样本的距离尽可能小,不同簇内的样本距离尽可能大,即最小化每个簇中样本与质心的距离。从EM算法的角度来看,K-means的参数就是每个簇的质心,隐变量为每个样本属于哪个簇。在不知道样本属于哪个簇的情况下,运用EM算法来得到每个簇的质心μ。
假设有k个簇,随机选定k个点作为质心
μ
1
,
μ
2
,
.
.
.
,
μ
k
μ_1,μ_2,...,μ_k
μ1,μ2,...,μk,进行:
(1)固定μ_i(i=1,2,…,k),将样本划分到距离最近的
μ
i
μ_i
μi中,用
r
n
i
r_{n_i}
rni来表示第n个样本所属的簇。这一步对应EM算法的E步。
(2)固定
r
n
i
r_{n_i}
rni,根据上一步的划分结果重新计算每个簇的质心,来最小化每个簇中样本与质心的距离。这一步对应EM算法的M步。
K-means可以保证收敛到局部最优值,但在非凸目标函数的情况下不能保证收敛到全局最优值。
8.2高斯混合模型
高斯混合模型多用于聚类,与K-means不同的是其采用概率模型来表达聚类原型。关于高斯分布(Gaussian Distribution)为:对于随机变量,其概率密度函数可表示为:
N
(
x
∣
μ
,
σ
2
)
=
1
2
π
σ
2
e
−
(
x
−
μ
)
2
2
σ
2
{\ N}(x|\mu,\sigma^2)=\cfrac{1}{\sqrt{2\pi\sigma^2}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}
N(x∣μ,σ2)=2πσ21e−2σ2(x−μ)2
若x为n维随机向量,则多元高斯分布(Multivariate Gaussian Distribution)为:
N
(
x
∣
μ
,
Σ
)
=
1
(
2
π
)
n
2
∣
Σ
∣
1
2
e
−
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
{\ N}(x|\mu,\Sigma)=\cfrac{1}{(2\pi)^{\frac{n}{2}}|\Sigma|^\frac{1}{2}} e^{-\frac{1}{2}(x-\mu)^\ T \Sigma^{-1}(x-\mu)}
N(x∣μ,Σ)=(2π)2n∣Σ∣211e−21(x−μ) TΣ−1(x−μ)
高斯混合模型,本质上是k个高斯分布的线性组合,可以描述更多样的分布:
p
(
x
)
=
∑
k
=
1
K
π
k
N
(
x
∣
μ
k
,
Σ
k
)
p(x)=\sum\limits_{k=1}^K\pi_k{\ N}(x|\mu k,\Sigma_k)
p(x)=k=1∑Kπk N(x∣μk,Σk)
其中
π
k
π_k
πk为混合系数,
∑
k
=
1
K
π
k
=
1
\sum\limits_{k=1}^K {\pi_k}=1
k=1∑Kπk=1。
对于高斯混合模型来说,先依照
π
k
π_k
πk选择第k个高斯分模型,然后依照其概率密度函数进行采样生成相应的样本。高斯混合模型的隐变量为样本来自于第几个分模型。
定义一个k维随机向量
z
=
z
1
,
z
2
,
.
.
.
,
z
k
z={z_1,z_2,...,z_k}
z=z1,z2,...,zk,其中只有一个
z
i
(
i
=
1
,
2
,
.
.
.
,
k
)
z_i(i=1,2,...,k)
zi(i=1,2,...,k)为1,其余为0,表示样本来自于第i个分模型。
(1)将
π
k
π_k
πk视为选择第k个分模型的先验概率,计算
x
i
(
i
=
1
,
2
,
.
.
.
,
k
)
x_i(i=1,2,...,k)
xi(i=1,2,...,k)属于第j个分模型的后验概率,对应EM算法的E步。
(2)
x
i
(
i
=
1
,
2
,
.
.
.
,
k
)
x_i(i=1,2,...,k)
xi(i=1,2,...,k)属于第j个分模型的后验概率来计算每一个样本的
μ
μ
μ和
Σ
Σ
Σ来更新参数,对应EM算法的M步。
高斯混合模型相比于K-means更具一般性,能形成各种不同大小和形状的簇。K-means可视为高斯混合聚类中每个样本仅指派给一个混合成分的特例,且各混合成分协方差相等,均为对角矩阵。
但高斯混合模型的计算量较大收敛慢。因此常先对样本集运用k-means,依据得到的各个簇来定高斯混合模型的初始值。其中质心即为均值向量,协方差矩阵为每个簇中样本的协方差矩阵,混合系数为每个簇中样本占总体样本的比例。
8.3在半监督学习上的应用
在现实分类问题中,常遇到少量样本是带有标签,大部分样本缺失标签的情况。为了能利用无标签的样本,可以采用EM算法,将标签视为隐变量,来利用数据进行训练,主要步骤为:
(1)仅利用有标签的样本训练模型,得到初始参数θ。
(2)E步:利用训练好的模型预测无标签样本,将样本分类到概率最大的类别。
(3)M步:用所有的样本重新训练模型,得到参数
θ
t
+
1
θ_{t+1}
θt+1。
重复(2)和(3)直到收敛,得到最终的模型。
9.总结
EM算法是迭代求解最大值的算法,计算含有隐含变量的概率模型参数估计。EM算法在每一次迭代时分为两步,E步和M步。一轮轮迭代更新隐含数据和模型分布参数,直到收敛,即得到我们需要的模型参数。
10.参考
【1】EM算法及其应用(一)
【2】EM算法及其应用(二)
【3】EM算法(Expectation Maximization Algorithm)详解
【4】EM算法整理及其python实现
【5】DEMPSTER,A. P. Maximum likelihood from incomplete data via the EM algorithm[J]. Journal of the Royal Statal Society, 1977, 39.
【6】李航.统计学习方法.北京:清华大学出版社,2012
【7】机器学习-白板推导系列(十)-EM算法(Expectation Maximization)
【8】复旦-机器学习课程 第十讲 EM















 514
514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









