






一些碎碎念
钓鱼网站有典型的几种特征:
- 有表单
- 有跳转链接
- 有一些很抓马的关键词
- 巨长巨长的链
通过三种判定条件划分它们的不同类别:
- 有没有表单
- 有没有跳转链接
- 有没有关键词出现
本菜鸡的思路是,先访问网站获取源码,过滤它有没有表单或者链接,后台截图ocr识别文字得到列表,然后搞到一本字典,看有没有关键词,然后计算关键词占比,结合前面的条件判断危险性。
ocr白嫖百度的paddler里的模型,直接用轻量型的预训练ch和en模型识别。
百度的PaddlerOCR
因为老子不写论文,卷不过它们这些科研佬,就不训练深度学习模型了(主要是耗时耗力,不如白嫖的质量高、时间短)。
好了现在要解决的问题就是怎么隐式截图?不要紧,你的大爹chatgpt会帮你。
这里用的google浏览器启动器来后台打开网页,所以要下载一个chrome_driver.exe,并加入系统环境路径。
有了怎么截图、ocr模型,钓鱼的测试网站哪里来?
来来来,这里有个好东西:______,记录了各种乱七八糟的网站,有可能是钓鱼也有可能是真的网站,只是写得太像钓鱼了。最好人工筛选一下,不然你今天能打开的钓鱼网站,明天就被查杀了。
还有一个kali上可以用setoolkit配置钓鱼模板文件,还可以安装一个mip22专门用于构建钓鱼的脚本工具包。
接下来,字典呢?这个字典就靠你自己人工搞一下了,什么login submit这些很经典的,credit financial这些可能有关money的也是。
然后我自定义的钓鱼等级规则如下:
待定......
包含的项数越多越完整就等级越高,越危险,不过有些正规网站也这样啊(doge),那就勇敢点击,反正我又不是正经反钓鱼的。
老实说对这些东西没啥兴趣,因为钓鱼不就是这样吗,我还是想知道setoolkit的逻辑是什么,已经在看源码了。
话说kali虚拟机其实是可以设置代理的,大部分肯定觉得在虚拟机里面访问twitter,是不是有什么大病。但是,我觉得吧,万一呢,你以后需要在虚拟机里用科技咋办0-0?
写一点点就好了,因为有人抄得比我自己写得还要快捏。
~~~~~~~~~~~~~不华丽的分割线~~~~~~~~~~~~

~~~~~~~~~~~~~不华丽的分割线~~~~~~~~~~~~
建立钓鱼网站
Kali上使用建站工具setookit
Kali上使用建站工具mip22
1.安装
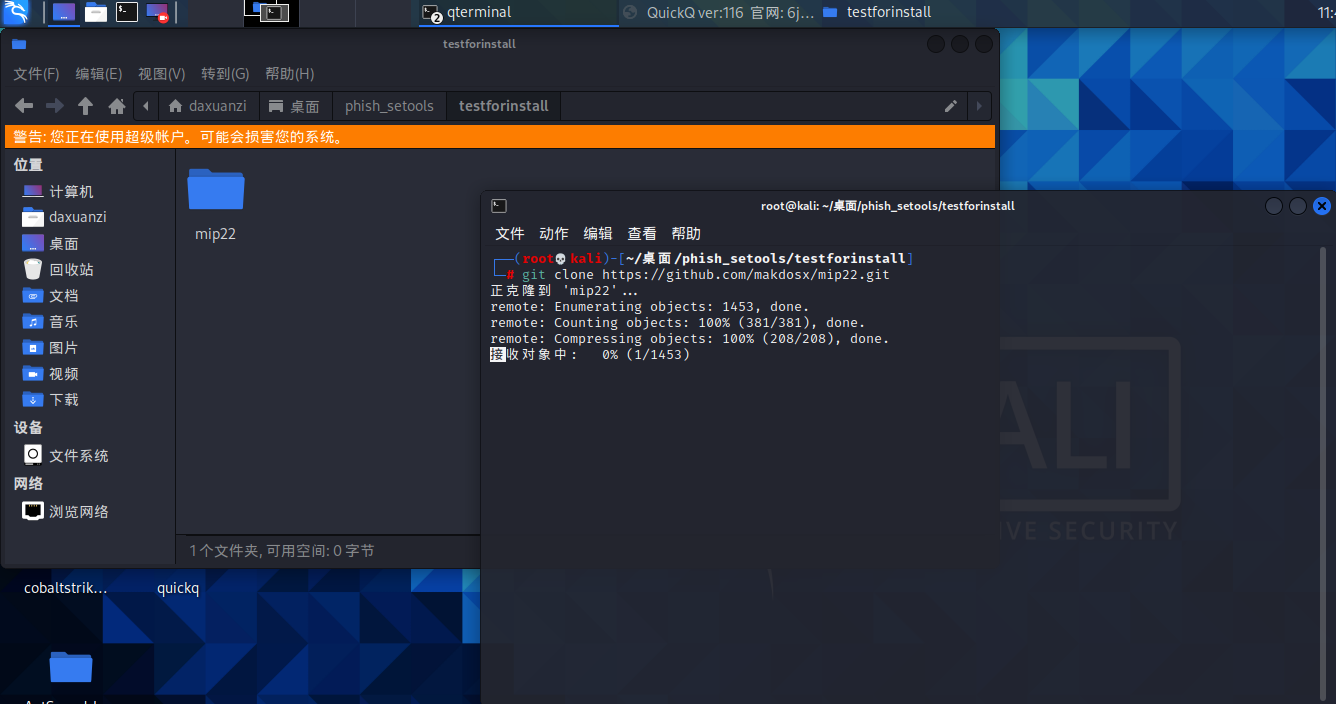
启动脚本mip22.sh
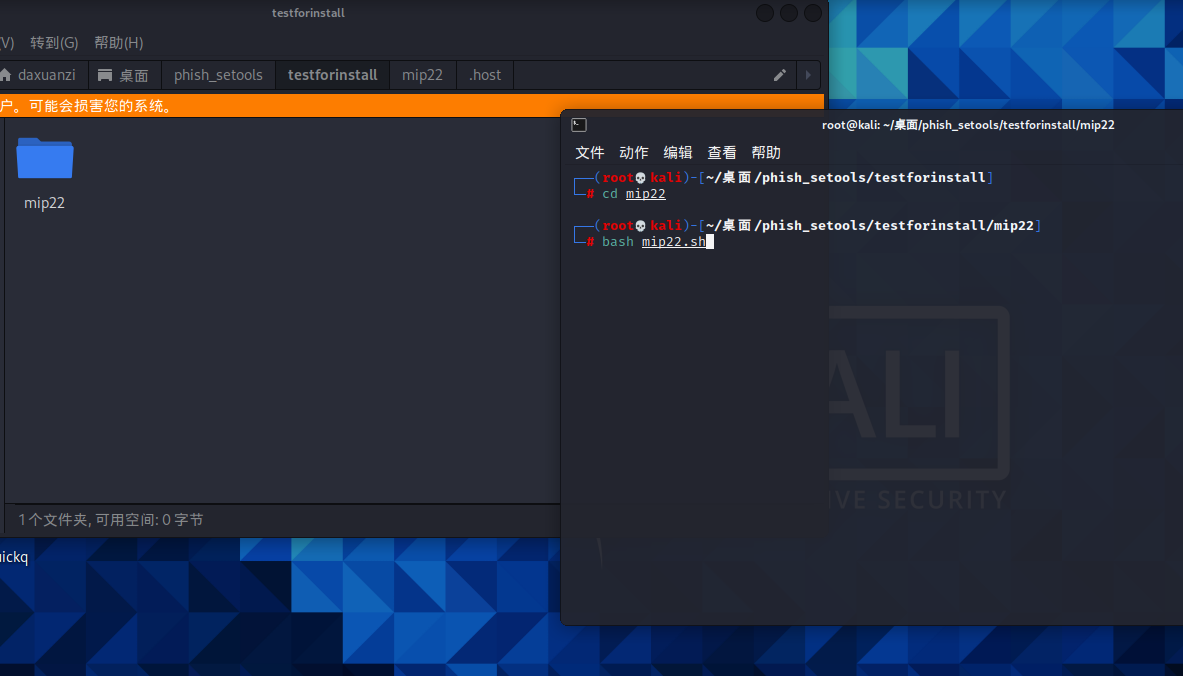
现在文件夹里会出现cloudflared-linux-amd64,注意把它复制到.host里。
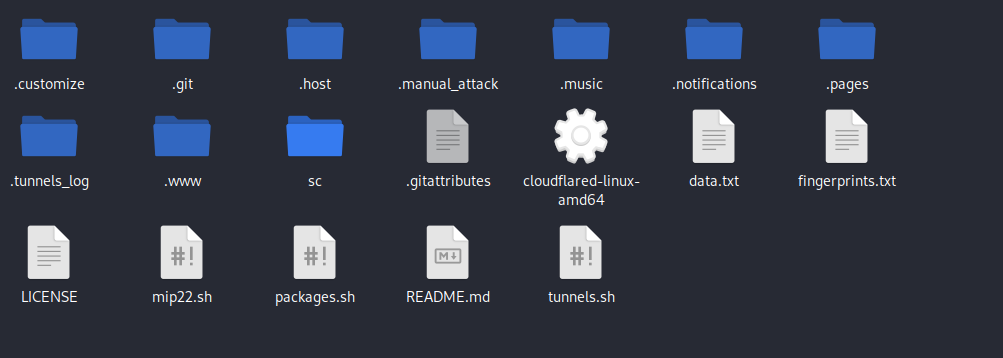
在.host里新建cloudflared文件夹,然后把这东西复制到里面。
然后再启动一次
启动工具结束
2.开始建站
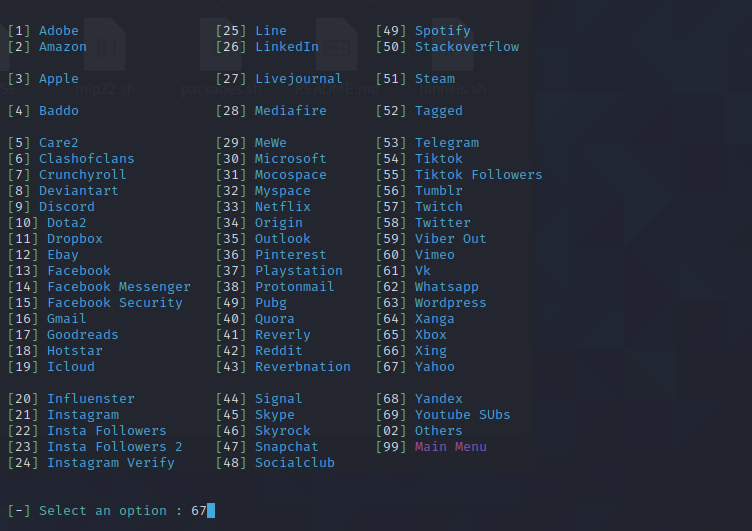
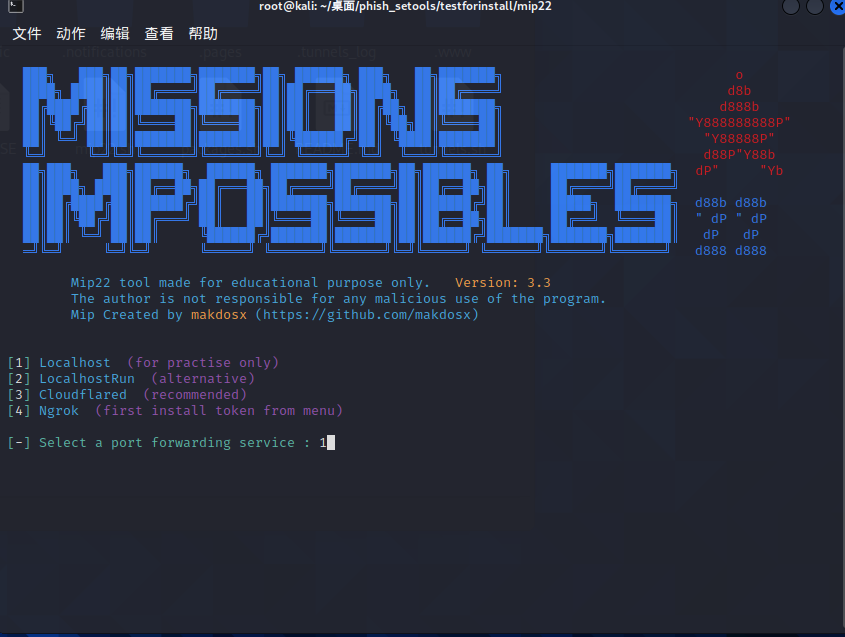
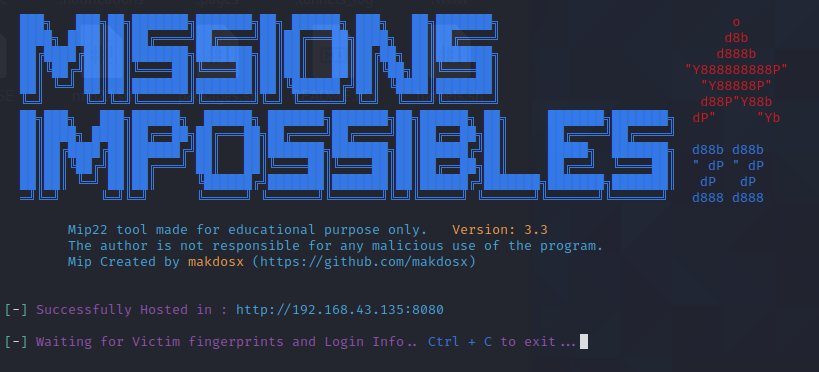
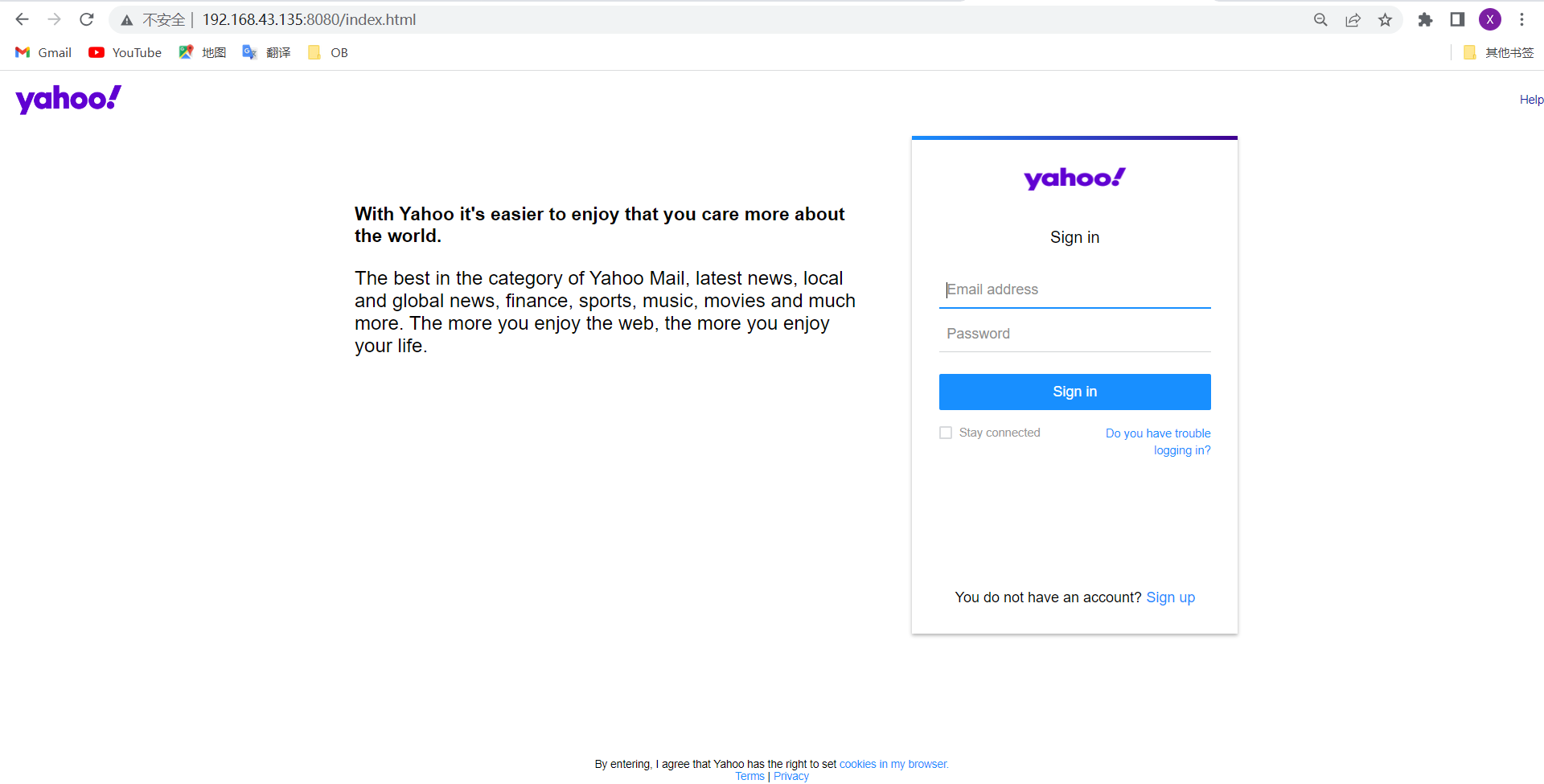
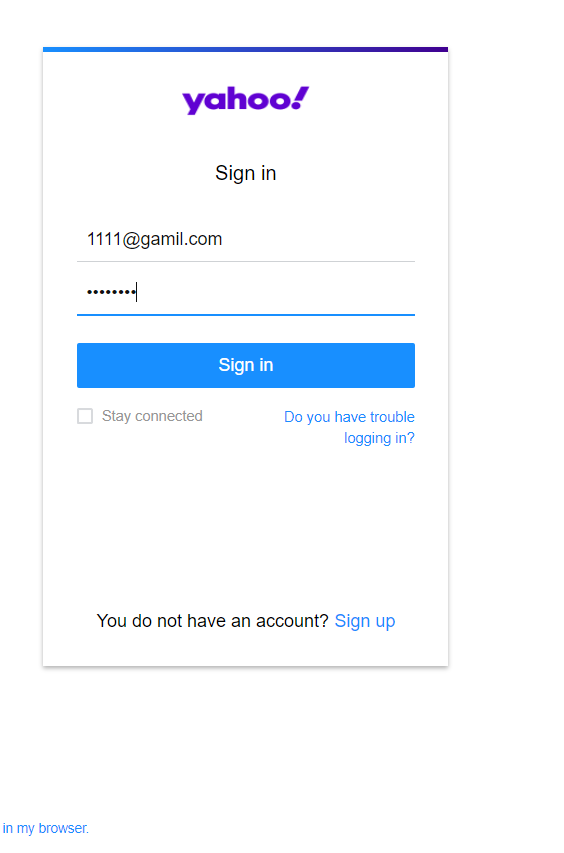
后台可以直接收到登录的信息如下: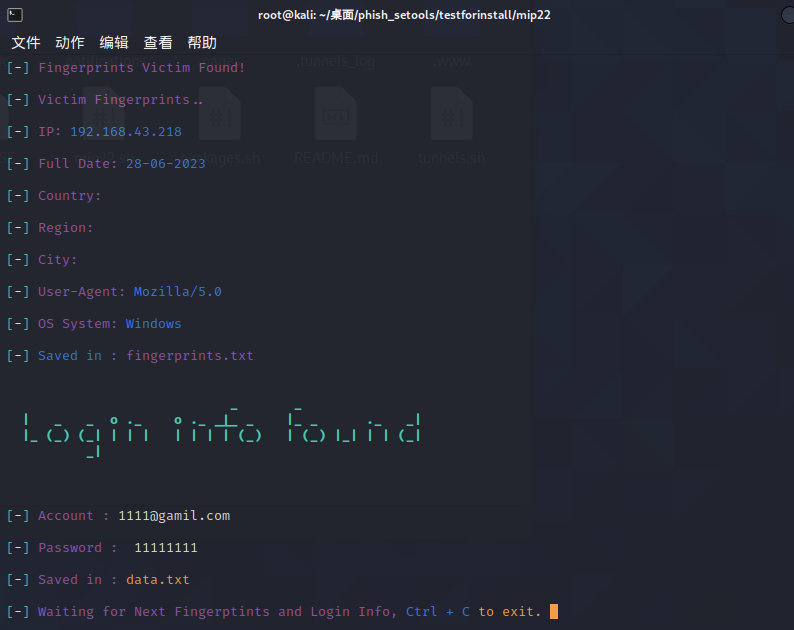
3.要使用ngrok来映射网址,好像只能用一次,用作钓鱼会被封号斗罗,只有第一次是成功的。
首先,编写测试脚本test.sh,放在和mip22.sh一样的文件夹下。
#!/bin/bash
GREEN='\033[0;32m'
WHITE='\033[1;37m'
MAGENTA='\033[0;35m'
CYAN='\033[0;36m'
ngrok_start() {
echo -e "\n${GREEN}[${WHITE}-${GREEN}]${MAGENTA} Initializing... ${MAGENTA}( ${CYAN}http://$host:$port ${MAGENTA})"
echo -ne "\n\n${GREEN}[${WHITE}-${GREEN}]${MAGENTA} Launching Ngrok..."
if [[ `command -v termux-chroot` ]]; then
sleep 2 && termux-chroot ./.host/ngrok http "$host":"$port" > /dev/null 2>&1 &
else
sleep 2 && ./.host/ngrok http "$host":"$port" > /dev/null 2>&1 &
fi
sleep 5 # 增加等待时间以确保Ngrok成功启动
ngrok_status=$(curl -s -N http://127.0.0.1:4040/api/tunnels)
http_url=$(echo "$ngrok_status" | grep -o 'http://[^"]*' | grep -vE "$host")
https_url=$(echo "$ngrok_status" | grep -o 'https://[^"]*' | grep -vE "$host")
echo -e "\n${GREEN}[${WHITE}-${GREEN}]${WHITE} URL http : ${GREEN}$http_url"
echo -e "\n${GREEN}[${WHITE}-${GREEN}]${WHITE} URL https : ${GREEN}$https_url"
}
# 设置您的host和port变量
host="kali ip"
port="8080"
# 调用ngrok_start函数
ngrok_start
然后测试运行输出以下结果:
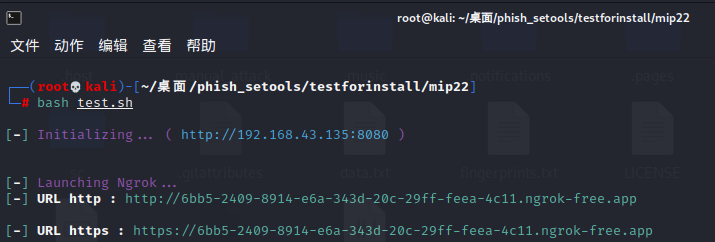
然后访问这两个网址的任何一个,打开即可。
由于已经测试被封号了T_T,所以就不用这个功能了。
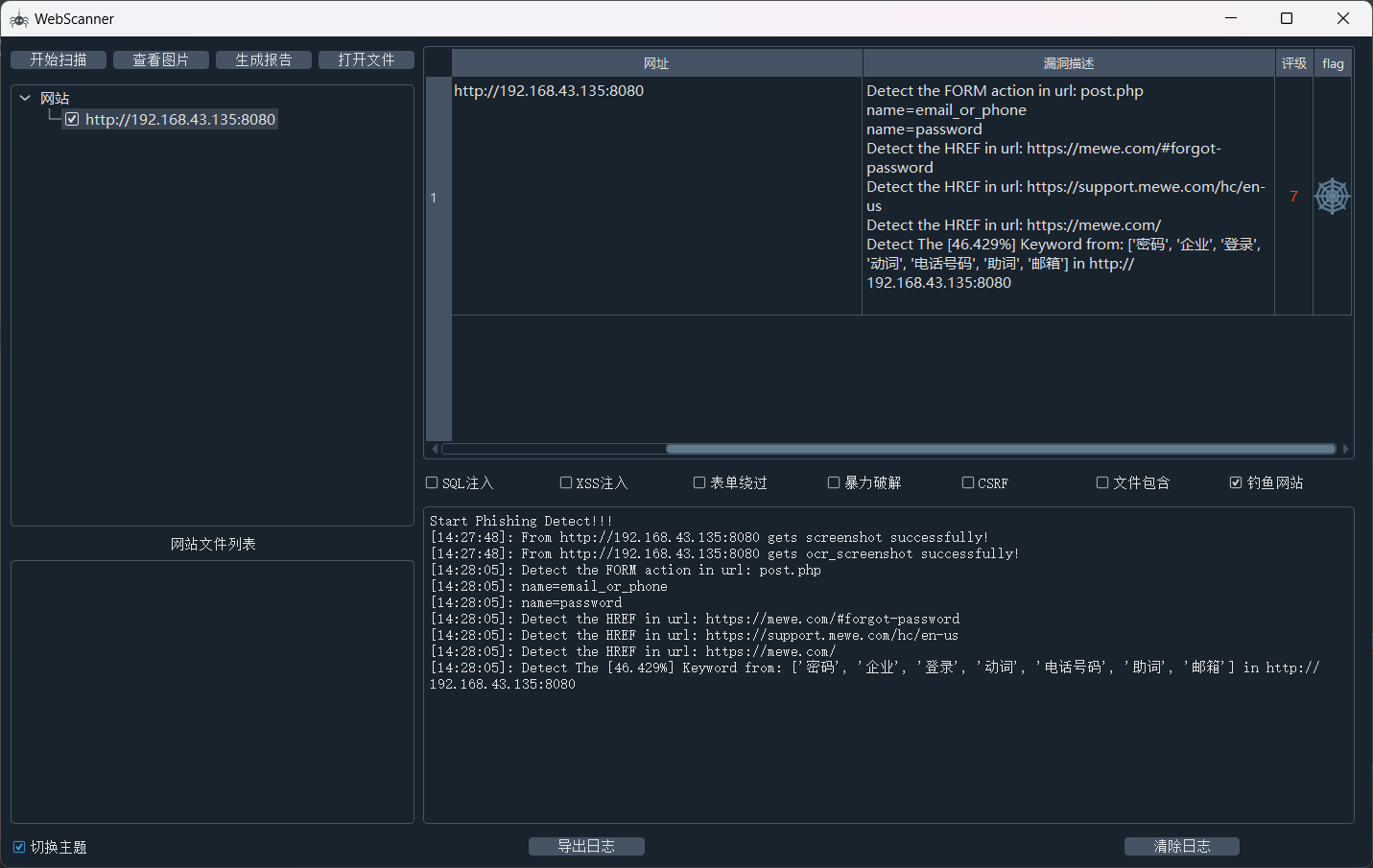
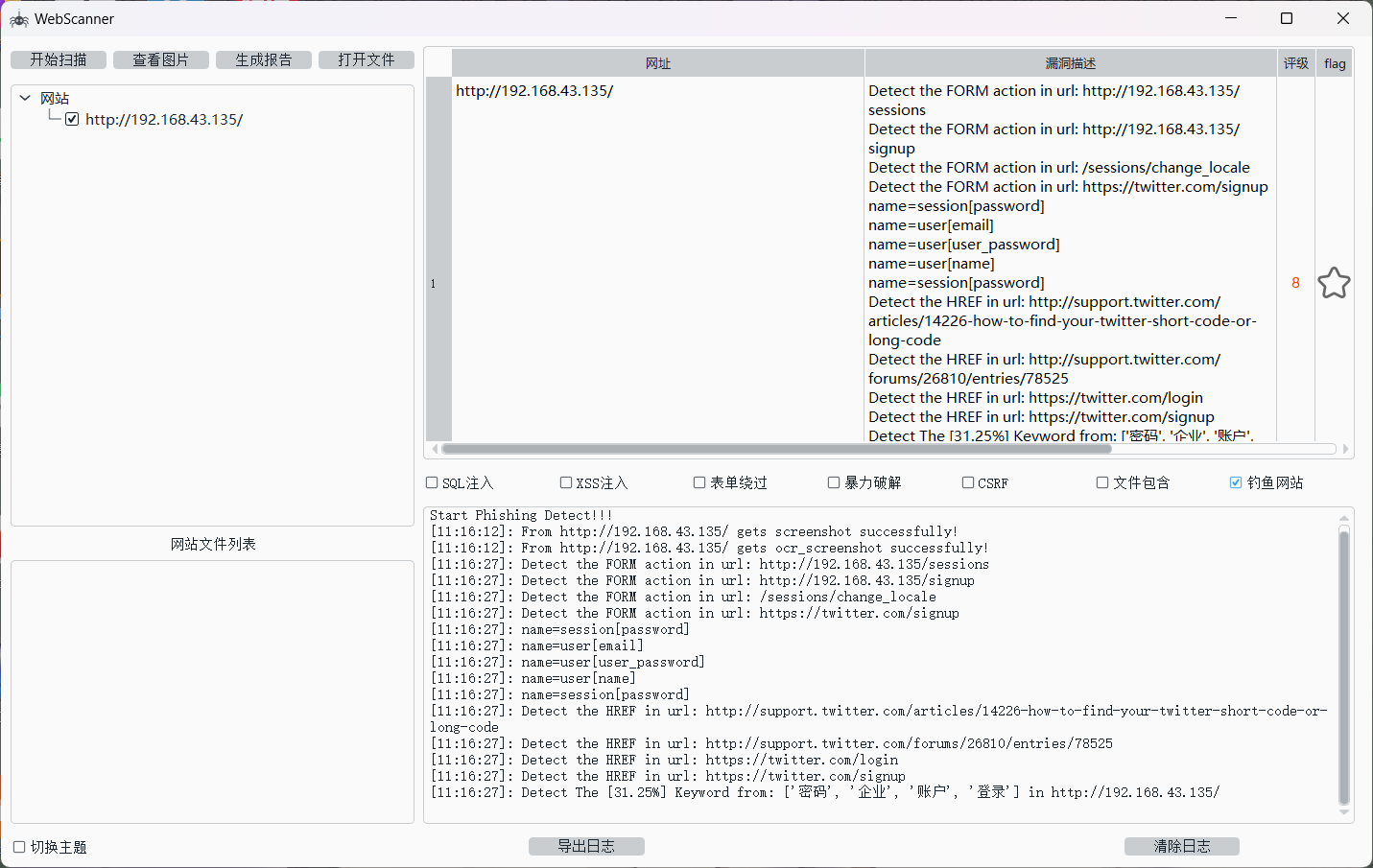
通过以上两种方式可以得到两个钓鱼网站,一个是推特登录,一个是Mewe的登录。
代码实现
由于直接用request.get(url)有可能被拦截获取不到网页源码,或者是直接打不开网页,我直接用自动化测试工具selenium来做,下载谷歌的chromedriver.exe,必须和当前你使用的浏览器的版本相匹配,否则失败。
钓鱼主类 PhishDetector
传入的config.ini是我写的配置文件,这里要使用的话直接替换成自己的绝对路径的位置
因为这是我写的子模块,只能透露这些了。
记得下载百度的飞桨库,这里我写的是调用特定功能才会使用特定库,所以不能立马发现哪个库没装,要自己仔细看。
import time
from selenium import webdriver
# from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as ec
from selenium.webdriver.support.wait import WebDriverWait
# 截图 存 src/main/phish/target/screenshot_{}-{}.png
# ocr 结果 存 src/main/phish/out/ocr_image_{}_{}.png
# 生成 log 存 src/log/phishing_log_{}.txt
class PhishDetector:
def __init__(self, config_ini):
super(PhishDetector, self).__init__()
self.config_ini = config_ini
self.target_img = self.config_ini['main_project']['project_path'] + self.config_ini['phish']['phish_target_img']
self.phish_log = self.config_ini['main_project']['project_path'] + self.config_ini['phish']['phish_log']
self.log_content = []
self.codes = ''
self.item_work = []
self.ocr_result = {}
self.warnings = []
self.image_data = []
def check_and_create_directory(self, path):
import os
if not os.path.exists(path):
os.makedirs(path)
def get_screen_shot_invisible(self, url, img_path):
# 隐式截图
# chrome_options = Options()
# chrome_options.add_argument("--headless")
# chrome_driver = webdriver.Chrome(options=chrome_options)
chrome_driver = webdriver.Chrome()
chrome_driver.get(url)
chrome_driver.maximize_window()
self.codes = chrome_driver.page_source
wait = WebDriverWait(chrome_driver, 10)
wait.until(ec.visibility_of_element_located((By.TAG_NAME, 'body')))
chrome_driver.get_screenshot_as_file(img_path)
chrome_driver.quit()
def screenshot_ocr_operator(self, input_path):
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, lang="en", show_log=False) # need to run only once to download and load model into memory
result = ocr.ocr(input_path, cls=True)
result = result[0]
txts = [line[1][0] for line in result]
self.image_data = [input_path, result]
return txts
def from_screen_To_ocr_result(self, url):
current_time = time.strftime("%Y-%m-%d_%H-%M-%S", time.localtime())
log_time = time.strftime("%H:%M:%S", time.localtime())
self.log_content.clear()
self.log_content.append('Start Phishing Detect!!!\n')
item_name = r'/screenshot_{}_.png'.format(current_time)
real_path = self.target_img + item_name
self.get_screen_shot_invisible(url, real_path)
self.log_content.append('[{}]: From {} gets screenshot successfully!\n'.format(log_time, url))
# print('The image from: {} screenshot gets sucessfully~~'.format(url))
self.ocr_result[url] = self.screenshot_ocr_operator(real_path)
self.log_content.append('[{}]: From {} gets ocr_screenshot successfully!\n'.format(log_time, url))
# print('The image from: {} ocr gets sucessfully~~'.format(url))
def level_judge_operator(self, url):
data = self.ocr_result
current_time = time.strftime("%Y-%m-%d_%H-%M-%S", time.localtime())
log_time = time.strftime("%H:%M:%S", time.localtime())
level_judge_obj = LevelJudge()
# code
identify_url_code_info = level_judge_obj.identify_url_source(self.codes)
self.warnings.clear()
for item in identify_url_code_info:
self.warnings.append(item)
temp_content = ['[{}]: {}'.format(log_time, item) for item in identify_url_code_info]
self.log_content += temp_content
#
# print('[{}]:{}'.format(log_time, identify_url_code_info))
keyword_prop, keywords = level_judge_obj.keyword_container(text_item=data[url])
# print('key_prop:{}, keywords:{}'.format(keyword_prop,keywords))
if keyword_prop != 0.00:
self.log_content.append('[{}]: Detect The [{}%] Keyword from: {} in {}\n'.format(log_time, keyword_prop, keywords, url))
self.warnings.append('Detect The [{}%] Keyword from: {} in {}\n'.format(keyword_prop, keywords, url))
# print('[{}]: Detect The [{}%] Keyword from: {} in {}\n'.format(log_time, keyword_prop, keywords, url))
log_file = self.phish_log.format(current_time)
log_string = ''.join(self.log_content)
warning_string = ''.join(self.warnings)
with open(log_file,'w',encoding='utf-8') as file:
file.write(log_string)
file.close()
# print('write end.\n')
return log_string, warning_string评级器类 LevelJudge
用于评价你传入的钓鱼网站的等级,但是其实我只写了判断过程,没有写评级标准,所以就只是把警告信息写出来,而不是判断数据属于哪个等级。
首先是ocr的识别结果和字典数据匹配,计算命中率和命中类别。
再接下来,之前已经通过自动化工具获取了源码,对源码进行两种不同的分析,我分开写的表单和跳转链接检测,还不够严谨,应该加上一个黑名单标记,但是我这里暂时没有写,先这样吧。
总之,有表单的话就再继续往下面搜,搜input元素里面的name是什么,是否危险;
有跳转链接,就提取有效的网址链接,因为有些链接是资源和样式,没啥用,直接筛选掉。
结合上述两个信息和匹配占比,共同输出危险信息。
class LevelJudge:
def __init__(self):
super(LevelJudge, self).__init__()
self.keywords = ['登录', '密码', '邮箱', '电话号码', '助词','动词','账户','金钱','符号','认证','安装','企业']
self.keywords_list = {
# 登录
'登录': ['log', 'id', 'register', 'sign'],
# 密码
'密码': ['keyword', 'pass'],
# 邮箱
'邮箱': ['email', 'address', 'send', 'contact'],
# 电话号码
'电话号码': ['number', 'phone', 'call', 'mobile'],
# 助词
'助词': ['success', 'successful', 'opportunity', 'congratulations', 'welcome', 'from','home','with'],
# 动词
'动词': ['submit', 'enter', 'continue', 'next', 'connect','support','to','help'],
# 账户
'账户': ['account', 'freeze', 'activate', 'profile', 'details', 'virgin', 'term'],
# 金钱
'金钱': ['money', 'bussiness', 'financial', 'finance'],
# 特殊符号
'符号': ['$', '¥', '@', '>>', '*'],
# 认证
'认证': ['identify', 'vertification', 'detail', 'name', 'game','birth', 'country', 'postcode', 'indicates','privacy'],
# 安装
'安装': ['launch', 'launching','install'],
# 企业
'企业': ['facebook', 'twitter','google','steam','community','mewe']
}
def convert_upper_to_lower(self, text_item):
new_data = [item.lower() for item in text_item]
return new_data
def keyword_container(self, text_item):
init_texts = self.convert_upper_to_lower(text_item=text_item)
shot_count = 0
shot_class = set()
total_count = 0
for text in init_texts:
for item in self.keywords:
value_list = self.keywords_list[item]
# print(value_list)
for value in value_list:
if value in text:
shot_count += 1
shot_class.add(item)
total_count += len(text.split())
# 保留三位小数
if total_count != 0:
shot_pro = round(shot_count / total_count * 100, 3)
else:
shot_pro = 0
return shot_pro, list(shot_class)
def identify_url_source(self, codes):
source_code = codes
form_warning = self.form_container(source_code=source_code)
href_warning = self.href_container(source_code=source_code)
return form_warning + href_warning
def form_container(self, source_code):
import re
pattern = r'<form.*?action="(.*?)".*?>'
init_matches = re.findall(pattern, source_code)
info = []
matches = list(set(init_matches)) # 去重
if matches:
for match in matches:
info.append(f"Detect the FORM action in url: {match}\n")
else:
info.append("Detect No form in url.\n")
attributes_list = self.get_form_input_attributes(source_code=source_code)
attributes_strings = [', '.join([f'{key}={value}' for key, value in attributes.items()]) + '\n' for attributes in attributes_list]
info = info + attributes_strings
return info
def get_form_input_attributes(self, source_code):
import re
pattern = r'<form.*?>(.*?)</form>'
exclude_names = ['lang', 'redirect', 'scribe_log']
matches = re.findall(pattern, source_code, re.DOTALL)
attributes_list = []
for match in matches:
input_pattern = r'<input.*?>'
init_matches = re.findall(input_pattern, match)
input_matches = list(set(init_matches)) # 去重
for input_match in input_matches:
# 删除无关的样式和类
input_match = re.sub(r'class=".*?"', '', input_match)
input_match = re.sub(r'style=".*?"', '', input_match)
# 删除指定的属性
input_match = re.sub(r'role=".*?"', '', input_match)
input_match = re.sub(r'label=".*?"', '', input_match)
input_match = re.sub(r'id=".*?"', '', input_match)
input_match = re.sub(r'required', '', input_match)
input_match = re.sub(r'type=".*?"', '', input_match)
# 删除checked、placeholder和autocomplete,maxlength属性
input_match = re.sub(r'checked=".*?"', '', input_match)
input_match = re.sub(r'placeholder=".*?"', '', input_match)
input_match = re.sub(r'autocomplete=".*?"', '', input_match)
input_match = re.sub(r'maxlength=".*?"','', input_match)
# 检查name和value同时出现
if 'name="' in input_match and 'value="' not in input_match:
# 提取属性
attributes = re.findall(r'(\w+)\s*=\s*"(.*?)"', input_match)
attributes_dict = dict(attributes)
if attributes_dict.get('name') not in exclude_names:
attributes_list.append(attributes_dict)
return attributes_list
def href_container(self, source_code):
import re
pattern = r'href=[\'"](.*?)[\'"]'
init_matches = re.findall(pattern, source_code)
matches = list(set(init_matches))
info = []
if matches:
for match in matches:
if match != '/' and match != '#' and match != '\\\\' and match != '':
if match.startswith(('http://', 'https://')) and not match.endswith(('.ico', '.css', '.js','.png','.jpeg','jpg')):
info.append(f"Detect the HREF in url: {match}\n")
else:
info.append("Detect No href in url.\n")
return info调用方式
创建调用类interface.py
class interface(object):
def __init__(self, config_ini):
super(interface, self).__init__()
self.config_ini = config_ini
def phish_interface(self, url):
from phish.phish import PhishDetector
phish_detector = PhishDetector(self.config_ini)
phish_detector.from_screen_To_ocr_result(url=url)
log_word, warning = phish_detector.level_judge_operator(url=url)
self.image_data.append(phish_detector.image_data)
return log_word, warning
if __name__ == "__main__":
obj = interface()
# 自己传入钓鱼网址列表
url_list = ['http://192.xxx.xxx.xxx','http://xxx.xxx.xxx.xxx',
...,...,
'http://123.123.123.123']
# 单个测试
log, warning = obj.phish_interface(url='http://192.168.43.133')
print("log:\n",log)
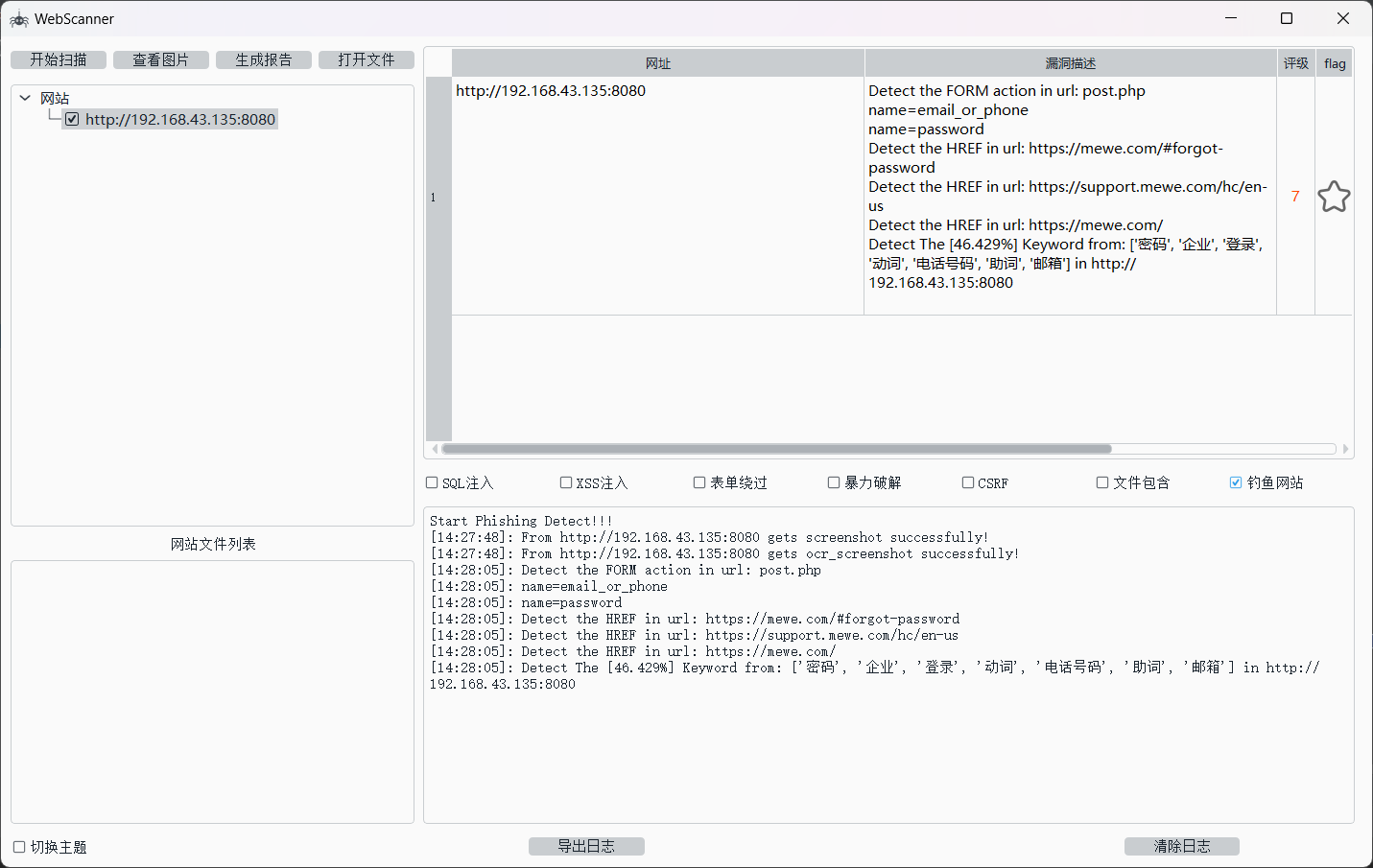
print("warning:\n",warning)我直接贴我的运行截图,但是因为这个项目是和其他人一起写的,所以其他源码暂时不放出来了。
MeWe:
OCR识别结果:

白天版
暗黑版
PDF报告 
Twitter:
OCR识别结果

警告信息
好了,差不多到这里,因为我又要开始写新的东西了,类似于IDE? 代码审计......难得我脑壳疼,因为UI和什么词法分析、语法分析以及还要管理后台啥的,什么造火箭!?
再加上遇上了一个事儿姐,浪费我人生中四个多小时给她讲代码,还要倒打我一耙。
真的是~~~~~无语~~~~~了,又给我亿点点震撼,流汗黄豆以御敌~~~~~~
😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅😅
肝疼,先去睡觉咯~~~















 307
307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









