



 文章介绍了如何通过后端采用流式传输(stream)改善GPT3.5接口的响应速度,前端实时解析并渲染每个字符,提高用户体验。对比了逐字输出和完整解析两种方法,前者在实际应用中表现更优。
文章介绍了如何通过后端采用流式传输(stream)改善GPT3.5接口的响应速度,前端实时解析并渲染每个字符,提高用户体验。对比了逐字输出和完整解析两种方法,前者在实际应用中表现更优。
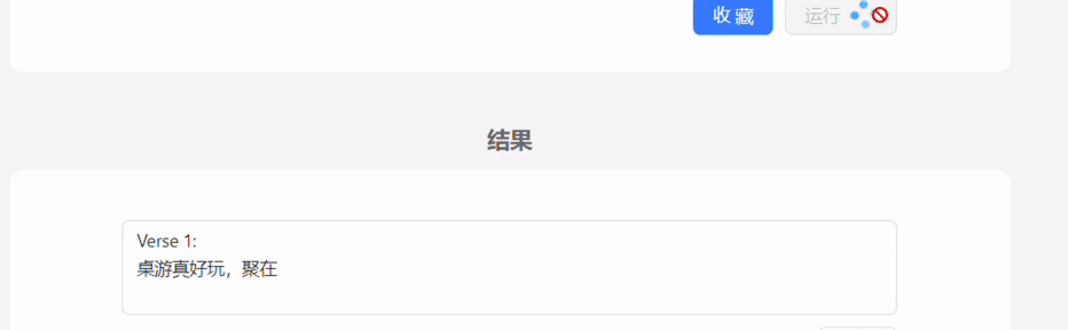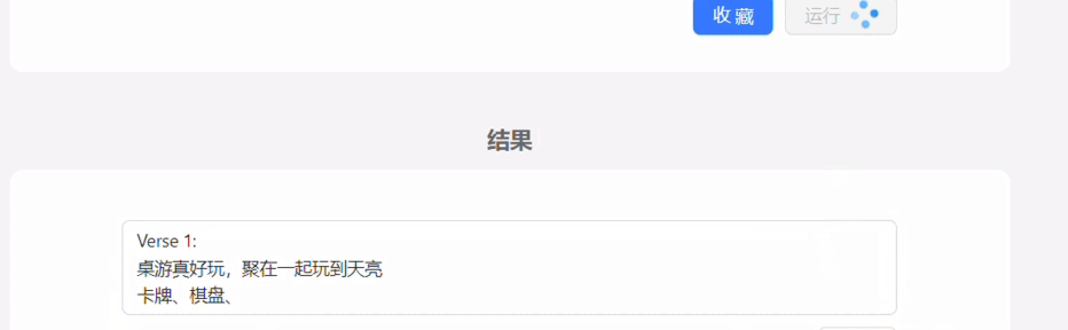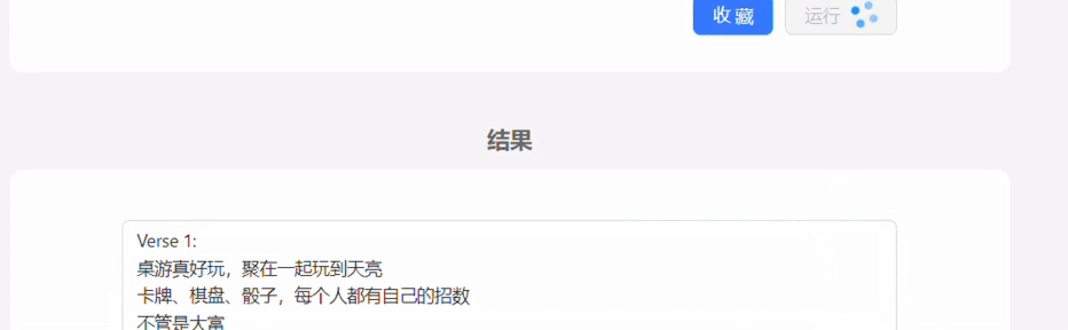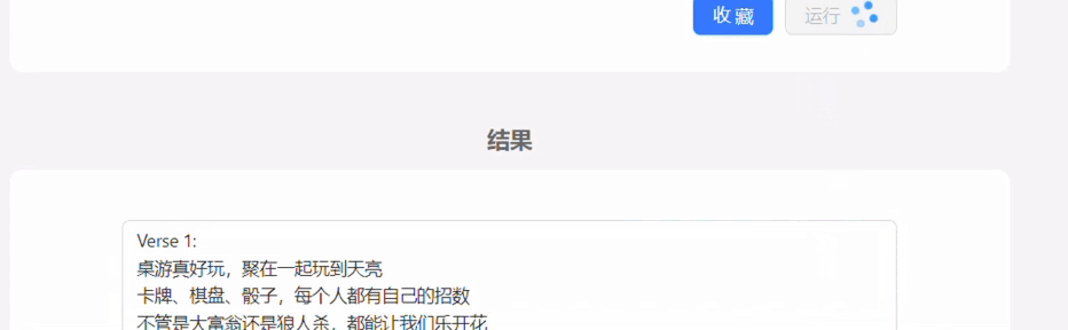
自己做的demo,本身也是用的GPT3.5接口
最近在捣鼓ai,对于ai,因为一般的gpt open API的速度会比较慢,而且ai的接口给到的也是一个字一个字给的,后端如果拿到所有字后再返回给前端,速度比较慢,用户体验很差
所以就需要:
1.后端采用流式传输(stream)拿到一个字就传输一个字
2.前端解析stream流,解析到一个字就渲染一个字
此处展示两种前端写法,其中只有第一种写法是可以逐字输出的
一、监听解析
首先打开一个后端的接口(使用了react的request包,如果是类umi的框架也可以使用框架封装好的request包)
import request from 'request';
const respons = request.post(`XXXXX`, { //你的后端接口
responseType: 'stream',
method: 'POST',
headers: {
'Content-Type': 'application/json; charset=utf-8',
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'GET,POST,OPTIONS',
'appcode': '007',
},
body: XXXX, //请求载荷
})
需要设置 responseType为stream,否则会默认用json解析
此时我们创建一个post实例,需要通过监听,使得每次获取到data就setState,如果监听到end就结束解析
const [output, setOutput] = useState<string>('')
respons.on('data', (data) => {
//通过TextDecoder解析出字符串
const chunkData = new TextDecoder().decode(data);
//触发setState,触发渲染
setOutput(prevState => prevState + chunkData)
})
respons.on('end', () => {
//结束,相当于promise的.then()
})
return <Input value={output} onChange={(e) => setOutput(e.target.value)}>
</Input>
可以在end事件部分继续写请求结束之后的逻辑,比如把loading状态变为false
虽然每次监听到流式都会触发渲染,但是实测渲染速度非常快,限制渲染速度的只有接口传输速度
一般是2秒的时间请求,之后流式过来就可以一直渲染了,用户体验极好
由此,可以实现逐字输出的方法
二、完整解析(无法逐字输出)
如果不想要逐字输出,想拿到所有流式后再统一解析,可以试试这个方法
runApp().then((res) => {
let reader = res.body.getReader();
let decoder = new TextDecoder();
let chunks: any = [];
const pump = () => {
return reader.read().then(({ done, value }) => {
if (done) {
let jsonString = decoder.decode(new Uint8Array(chunks));
let jsonObject = JSON.parse(jsonString);
console.log(jsonObject);
return;
}
chunks.push(value);
return pump();
});
};
return pump();
})
因为使用了.then,所以接口会在所有steam传输完毕后再触发.then后面的函数
使用了getReader()去阅读接口返回的流,但是阅读是通过分段的方式去阅读的(chunks),所以需要写循环遍历函数,分段读每个chunk
该方法不会逐字输出,适合在拿到所有返回后进行统一处理再渲染

















 58
58

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









