







本文的主要目的是生成VOC2007格式的Annotations,ImageSets和JPEGImages数据集,以便用faster rcnn训练。
需要做的前期工作有两个:下载ImageNet数据集下预训练得到的模型参数(用来初始化)和下载VOC2007数据集。
在此基础上开始生成VOC2007格式的Annotations,ImageSets和JPEGImages数据集。
下载ImageNet数据集下预训练得到的模型参数(用来初始化)
可以直接利用faster rcnn自带的脚本下载
cd $FRCN_ROOT
./data/scripts/fetch_imagenet_models.sh也可以在一个百度云上下载,地址:http://pan.baidu.com/s/1hsxx8OW
解压,然后将该文件放在py-faster-rcnn\data下
下载VOC2007数据集
下载VOC2007数据集
提供一个百度云地址:http://pan.baidu.com/s/1mhMKKw4
解压,然后,将该数据集放在py-faster-rcnn\data下,用你的数据集替换VOC2007数据集。Annotations,ImageSets和JPEGImages的格式分别如下:

用自己的数据生成Annotations,ImageSets和JPEGImages,复制到 VOC2007文件下, VOC2007原来的文件夹都加了_ori 而没有直接的替换,即如下图所示:
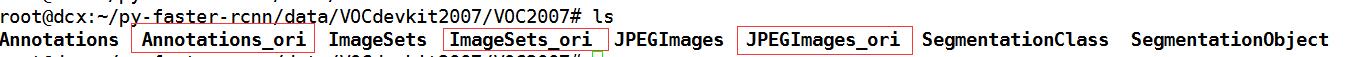
因此我们现在在需要准备的就是生成VOC2007格式的Annotations,ImageSets和JPEGImages
1.图片命名
虽然说图片名对训练没什么影响,但建议还是按VOC2007那样,如“000001.jpg”这种形式。至于图片格式, 我的也是jpg格式的。
批量修改图片名字为VOC2007格式,可以参考Matlab程序(RenamePic.m),代码如下:
%%
clc;
clear;
maindir='H:\medical_data\voctest\JPEGImage\';
name_long=6; %图片名字的长度,如000001.jpg为6,最多9位,可修改
num_begin=1; %图像命名开始的数字如000123.jpg开始的话就是123
subdir = dir(maindir);
%%
% dir得到的为结构体数组每个元素都是如下形式的结构体:
% name -- filename
% date -- modification date
% bytes -- number of bytes allocated to the file
% isdir -- 1 if name is a directory and 0 if not
% datenum -- modification date as a MATLAB serial date number
%%
n=1;
for i = 1:length(subdir)
if ~strcmp(subdir(i).name ,'.') && ~strcmp(subdir(i).name,'..')
img=imread([maindir,subdir(i).name]);
imshow(img);
str=num2str(num_begin,'%09d');
newname=strcat(str,'.jpg');
newname=newname(end-(name_long+3):end);
system(['rename ' [maindir,subdir(i).name] ' ' newname]);
num_begin=num_begin+1;
fprintf('已经处理%d张图片\n',n);
n=n+1;
pause(0.1);%可以把暂停去掉
end
end2.目标信息保存
我的CT肺数据已经了结节轮廓的标注信息,因此我只需要记录左上右下的坐标位置就好,格式如下:
000005.jpg nodule 86 44 129 66
000006.jpg nodule 94 48 142 73
000007.jpg nodule 86 150 129 172
000008.jpg nodule 87 44 130 66
000009.jpg nodule 60 52 90 78
000010.jpg nodule 66 57 100 86
000011.jpg nodule 60 73 90 99前面是图片名,中间是目标类别,最后是目标的包围框坐标(左上角和右下角坐标)。这个保存为txt格式,如out.txt。
3.做xml
做成VOC2007格式的xml,程序可参考matlab程序(VOC2007xml.m),代码如下:
%%
%该代码可以做voc2007数据集中的xml文件,
%txt文件每行格式为:000002.jpg nodule 44 28 132 121
%即每行由图片名、目标类型、包围框坐标组成,空格隔开
%包围框坐标为左上角和右下角
%作者:dcx
%%
clc;
clear;
%注意修改下面四个变量
imgpath='\img1\';%图像存放文件夹
txtpath='\out.txt';%txt文件
xmlpath_new='Annotations/';%修改后的xml保存文件夹
foldername='VOC2007';%xml的folder字段名
fidin=fopen(txtpath,'r');
lastname='begin';
while ~feof(fidin)
tline=fgetl(fidin);
str = regexp(tline, ' ','split');
filepath=[imgpath,str{1}];
if exist(filepath,'file')
img=imread(filepath);
[h,w,d]=size(img);
imshow(img);
rectangle('Position',[str2double(str{3}),str2double(str{4}),str2double(str{5})-str2double(str{3}),str2double(str{6})-str2double(str{4})],'LineWidth',4,'EdgeColor','r');
pause(0.1);
if strcmp(str{1},lastname)%如果文件名相等,只需增加object
object_node=Createnode.createElement('object');
Root.appendChild(object_node);
node=Createnode.createElement('name');
node.appendChild(Createnode.createTextNode(sprintf('%s',str{2})));
object_node.appendChild(node);
node=Createnode.createElement('pose');
node.appendChild(Createnode.createTextNode(sprintf('%s','Unspecified')));
object_node.appendChild(node);
node=Createnode.createElement('truncated');
node.appendChild(Createnode.createTextNode(sprintf('%s','0')));
object_node.appendChild(node);
node=Createnode.createElement('difficult');
node.appendChild(Createnode.createTextNode(sprintf('%s','0')));
object_node.appendChild(node);
bndbox_node=Createnode.createElement('bndbox');
object_node.appendChild(bndbox_node);
node=Createnode.createElement('xmin');
node.appendChild(Createnode.createTextNode(sprintf('%s',num2str(str{3}))));
bndbox_node.appendChild(node);
node=Createnode.createElement('ymin');
node.appendChild(Createnode.createTextNode(sprintf('%s',num2str(str{4}))));
bndbox_node.appendChild(node);
node=Createnode.createElement('xmax');
node.appendChild(Createnode.createTextNode(sprintf('%s',num2str(str{5}))));
bndbox_node.appendChild(node);
node=Createnode.createElement('ymax');
node.appendChild(Createnode.createTextNode(sprintf('%s',num2str(str{6}))));
bndbox_node.appendChild(node);
else %如果文件名不等,则需要新建xml
copyfile(filepath, 'JPEGImages');
%先保存上一次的xml
if exist('Createnode','var')
tempname=lastname;
tempname=strrep(tempname,'.jpg','.xml');
xmlwrite(tempname,Createnode);
end
Createnode=com.mathworks.xml.XMLUtils.createDocument('annotation');
Root=Createnode.getDocumentElement;%根节点
node=Createnode.createElement('folder');
node.appendChild(Createnode.createTextNode(sprintf('%s',foldername)));
Root.appendChild(node);
node=Createnode.createElement('filename');
node.appendChild(Createnode.createTextNode(sprintf('%s',str{1})));
Root.appendChild(node);
source_node=Createnode.createElement('source');
Root.appendChild(source_node);
node=Createnode.createElement('database');
node.appendChild(Createnode.createTextNode(sprintf('My Database')));
source_node.appendChild(node);
node=Createnode.createElement('annotation');
node.appendChild(Createnode.createTextNode(sprintf('VOC2007')));
source_node.appendChild(node);
node=Createnode.createElement('image');
node.appendChild(Createnode.createTextNode(sprintf('flickr')));
source_node.appendChild(node);
node=Createnode.createElement('flickrid');
node.appendChild(Createnode.createTextNode(sprintf('NULL')));
source_node.appendChild(node);
owner_node=Createnode.createElement('owner');
Root.appendChild(owner_node);
node=Createnode.createElement('flickrid');
node.appendChild(Createnode.createTextNode(sprintf('NULL')));
owner_node.appendChild(node);
node=Createnode.createElement('name');
node.appendChild(Createnode.createTextNode(sprintf('dcx')));
owner_node.appendChild(node);
size_node=Createnode.createElement('size');
Root.appendChild(size_node);
node=Createnode.createElement('width');
node.appendChild(Createnode.createTextNode(sprintf('%s',num2str(w))));
size_node.appendChild(node);
node=Createnode.createElement('height');
node.appendChild(Createnode.createTextNode(sprintf('%s',num2str(h))));
size_node.appendChild(node);
node=Createnode.createElement('depth');
node.appendChild(Createnode.createTextNode(sprintf('%s',num2str(d))));
size_node.appendChild(node);
node=Createnode.createElement('segmented');
node.appendChild(Createnode.createTextNode(sprintf('%s','0')));
Root.appendChild(node);
object_node=Createnode.createElement('object');
Root.appendChild(object_node);
node=Createnode.createElement('name');
node.appendChild(Createnode.createTextNode(sprintf('%s',str{2})));
object_node.appendChild(node);
node=Createnode.createElement('pose');
node.appendChild(Createnode.createTextNode(sprintf('%s','Unspecified')));
object_node.appendChild(node);
node=Createnode.createElement('truncated');
node.appendChild(Createnode.createTextNode(sprintf('%s','0')));
object_node.appendChild(node);
node=Createnode.createElement('difficult');
node.appendChild(Createnode.createTextNode(sprintf('%s','0')));
object_node.appendChild(node);
bndbox_node=Createnode.createElement('bndbox');
object_node.appendChild(bndbox_node);
node=Createnode.createElement('xmin');
node.appendChild(Createnode.createTextNode(sprintf('%s',num2str(str{3}))));
bndbox_node.appendChild(node);
node=Createnode.createElement('ymin');
node.appendChild(Createnode.createTextNode(sprintf('%s',num2str(str{4}))));
bndbox_node.appendChild(node);
node=Createnode.createElement('xmax');
node.appendChild(Createnode.createTextNode(sprintf('%s',num2str(str{5}))));
bndbox_node.appendChild(node);
node=Createnode.createElement('ymax');
node.appendChild(Createnode.createTextNode(sprintf('%s',num2str(str{6}))));
bndbox_node.appendChild(node);
lastname=str{1};
end
%处理最后一行
if feof(fidin)
tempname=lastname;
tempname=strrep(tempname,'.jpg','.xml');
xmlwrite(tempname,Createnode);
end
end
end
fclose(fidin);
file=dir(pwd);
for i=1:length(file)
if length(file(i).name)>=4 && strcmp(file(i).name(end-3:end),'.xml')
fold=fopen(file(i).name,'r');
fnew=fopen([xmlpath_new file(i).name],'w');
line=1;
while ~feof(fold)
tline=fgetl(fold);
if line==1
line=2;
continue;
end
expression = ' ';
replace=char(9);
newStr=regexprep(tline,expression,replace);
fprintf(fnew,'%s\n',newStr);
end
fprintf('已处理%s\n',file(i).name);
fclose(fold);
fclose(fnew);
delete(file(i).name);
end
end4.保存xml到Annotations
新建一个文件夹,名字为Annotations,将xml文件全部放到该文件夹里。
5.将训练图片放到JPEGImages
新建一个文件夹,名字为JPEGImages,将所有的训练图片放到该文件夹里。
6.ImageSets\Main里的四个txt文件
新建文件夹,命名为ImageSets,在ImageSets里再新建文件夹,命名为Main。
我们可以通过xml名字(或图片名),生成四个txt文件,即:

txt文件中的内容为:
000035
000037
000041
000043
000044
000045
000046
000049
000050即图片名字(无后缀),test.txt是测试集,train.txt是训练集,val.txt是验证集,trainval.txt是训练和验证集.VOC2007中,trainval大概是整个数据集的50%,test也大概是整个数据集的50%;train大概是trainval的50%,val大概是trainval的50%。可参考matlab程序(VOCSet.m),代码如下:
%%
%该代码根据已生成的xml,制作VOC2007数据集中的trainval.txt;train.txt;test.txt和val.txt
%trainval占总数据集的50%,test占总数据集的50%;train占trainval的50%,val占trainval的50%;
%上面所占百分比可根据自己的数据集修改,如果数据集比较少,test和val可少一些
%%
%注意修改下面四个值
xmlfilepath='.\Annotations';
txtsavepath='.\ImageSets\Main\';
trainval_percent=0.5;%trainval占整个数据集的百分比,剩下部分就是test所占百分比
train_percent=0.5;%train占trainval的百分比,剩下部分就是val所占百分比
%%
xmlfile=dir(xmlfilepath);
numOfxml=length(xmlfile)-2;%减去.和.. 总的数据集大小
trainval=sort(randperm(numOfxml,floor(numOfxml*trainval_percent)));
test=sort(setdiff(1:numOfxml,trainval));
trainvalsize=length(trainval);%trainval的大小
train=sort(trainval(randperm(trainvalsize,floor(trainvalsize*train_percent))));
val=sort(setdiff(trainval,train));
ftrainval=fopen([txtsavepath 'trainval.txt'],'w');
ftest=fopen([txtsavepath 'test.txt'],'w');
ftrain=fopen([txtsavepath 'train.txt'],'w');
fval=fopen([txtsavepath 'val.txt'],'w');
for i=1:numOfxml
if ismember(i,trainval)
fprintf(ftrainval,'%s\n',xmlfile(i+2).name(1:end-4));
if ismember(i,train)
fprintf(ftrain,'%s\n',xmlfile(i+2).name(1:end-4));
else
fprintf(fval,'%s\n',xmlfile(i+2).name(1:end-4));
end
else
fprintf(ftest,'%s\n',xmlfile(i+2).name(1:end-4));
end
end
fclose(ftrainval);
fclose(ftrain);
fclose(fval);
fclose(ftest);这四个txt放在ImageSets\Main中。
替换voc2007数据集中的Annotations、ImageSets和JPEGImages,免去一些训练的修改。
准备好数据集后开始训练,具体训练方法参见我的博客:基于Faster RCNN的医学图像检测(肺结节检测)















 364
364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









