







重点回忆:调参,绘图
1,调参
思路是:
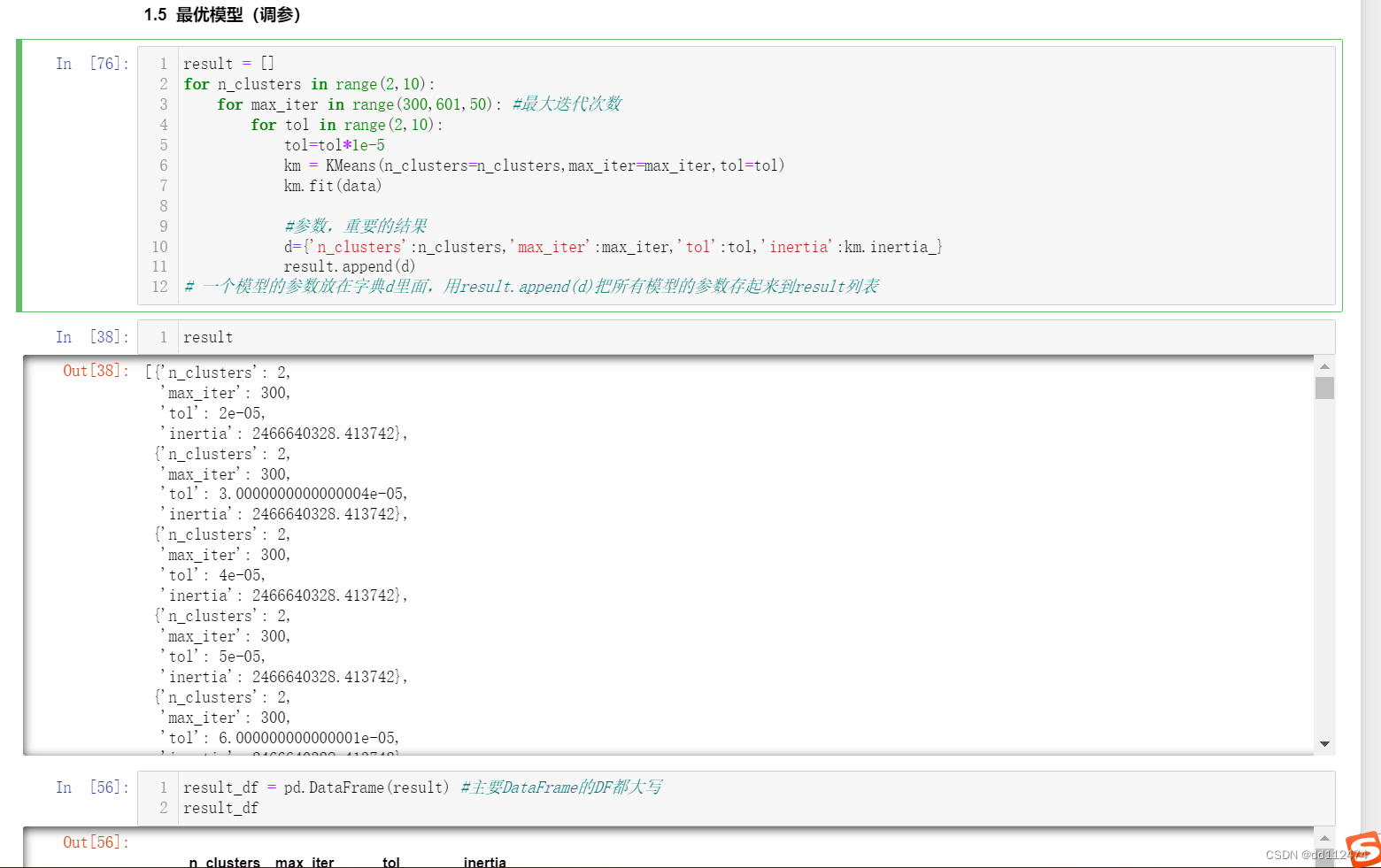
在外边新建一个变量result让它等于一个空列表 result = []
构建循环 for在循环里边构建字典,把结果储存在一个字典里 d = {}
把字典追加到result中,result.append(d)
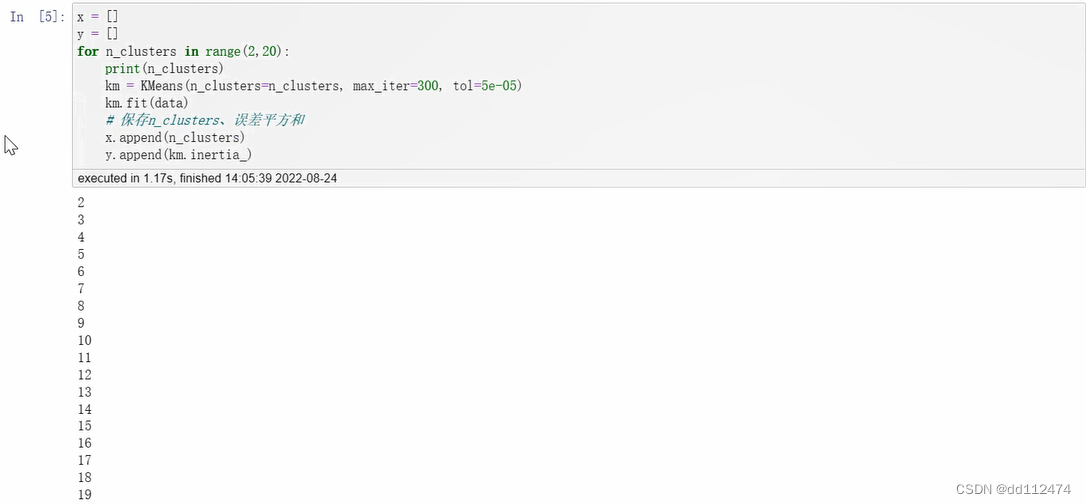
result = []
for n_clusters in range(2,10):
for max_iter in range(300,601,50): #最大迭代次数
for tol in range(2,10):
tol=tol*1e-5
km = KMeans(n_clusters=n_clusters,max_iter=max_iter,tol=tol)
km.fit(data)
#参数,重要的结果(如DBSCAN中n的个数)
d={'n_clusters':n_clusters,'max_iter':max_iter,'tol':tol,'inertia':km.inertia_}
result.append(d)
接下来可以生成DataFrame,或者导出成.csv文件
2,绘图
先用x,y构建储存横纵坐标的列表
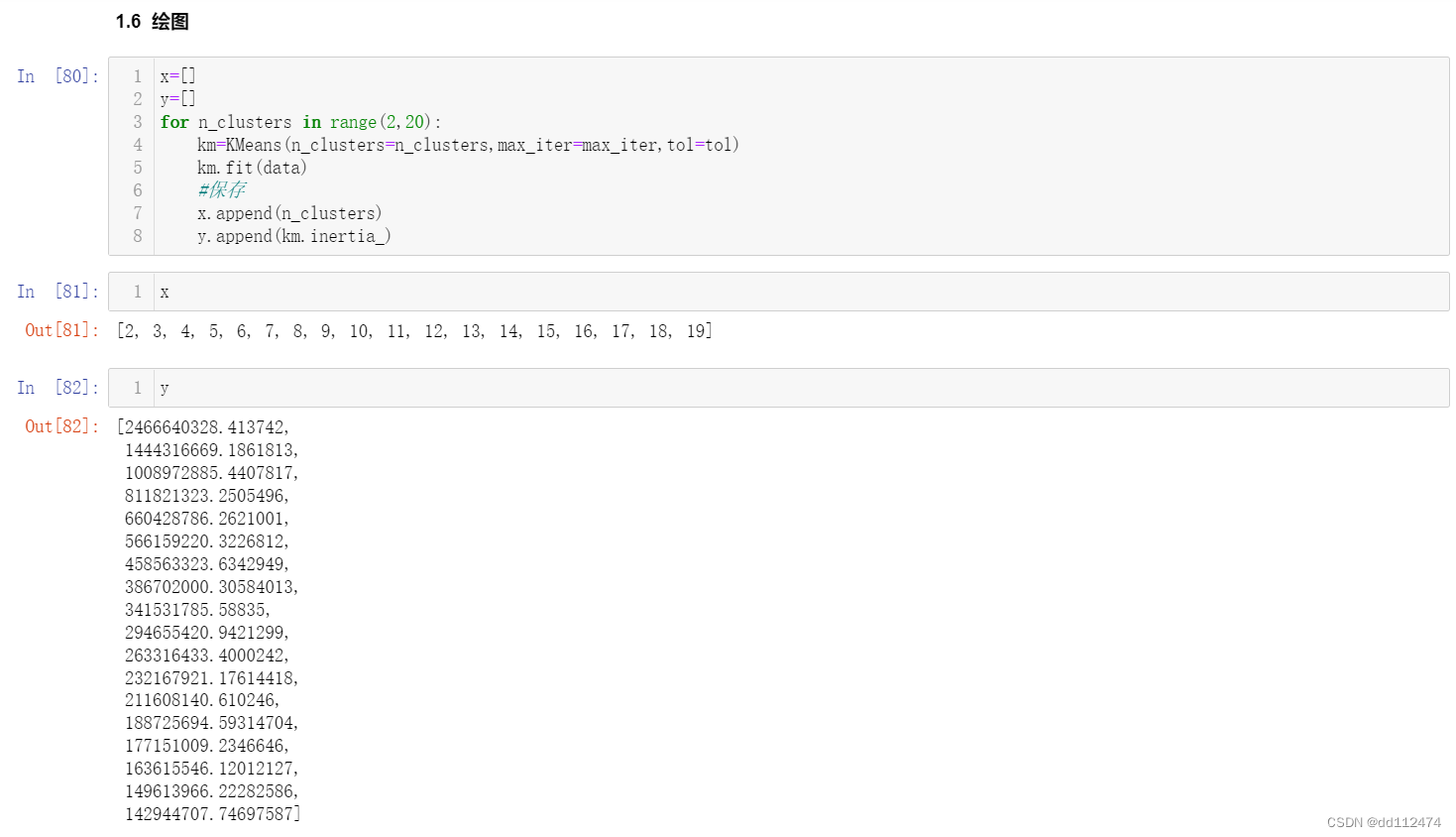
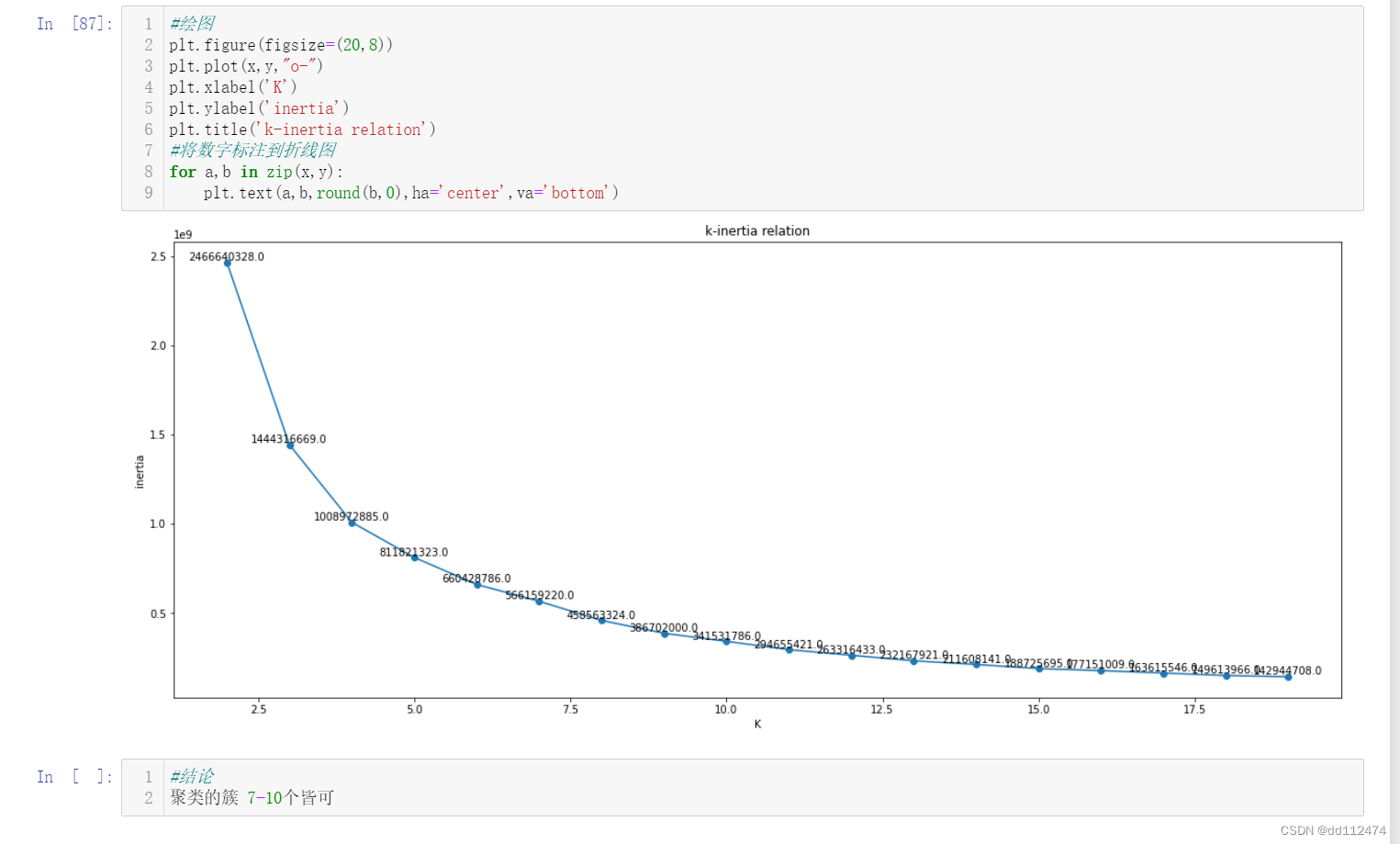
然后绘图
plt.plot(x,y,"o-")
括号里分别是x,y坐标和线段样式
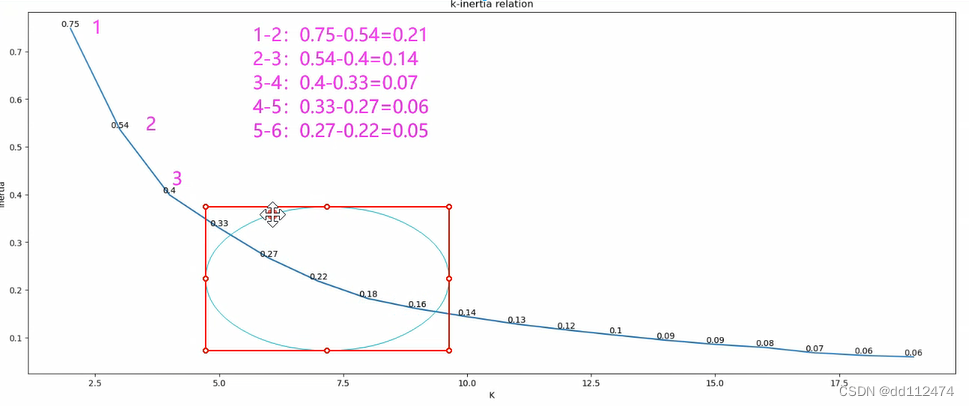
拐点变化作差,计算斜率
发现从4-5变化量已经和上一次3-4的差很接近,变化很小了,所以从4以后这个区域都可以选(一般选4-6)
代码实现:分三个层次的成果,先展示成果,在详细拆解步骤
第1次成果
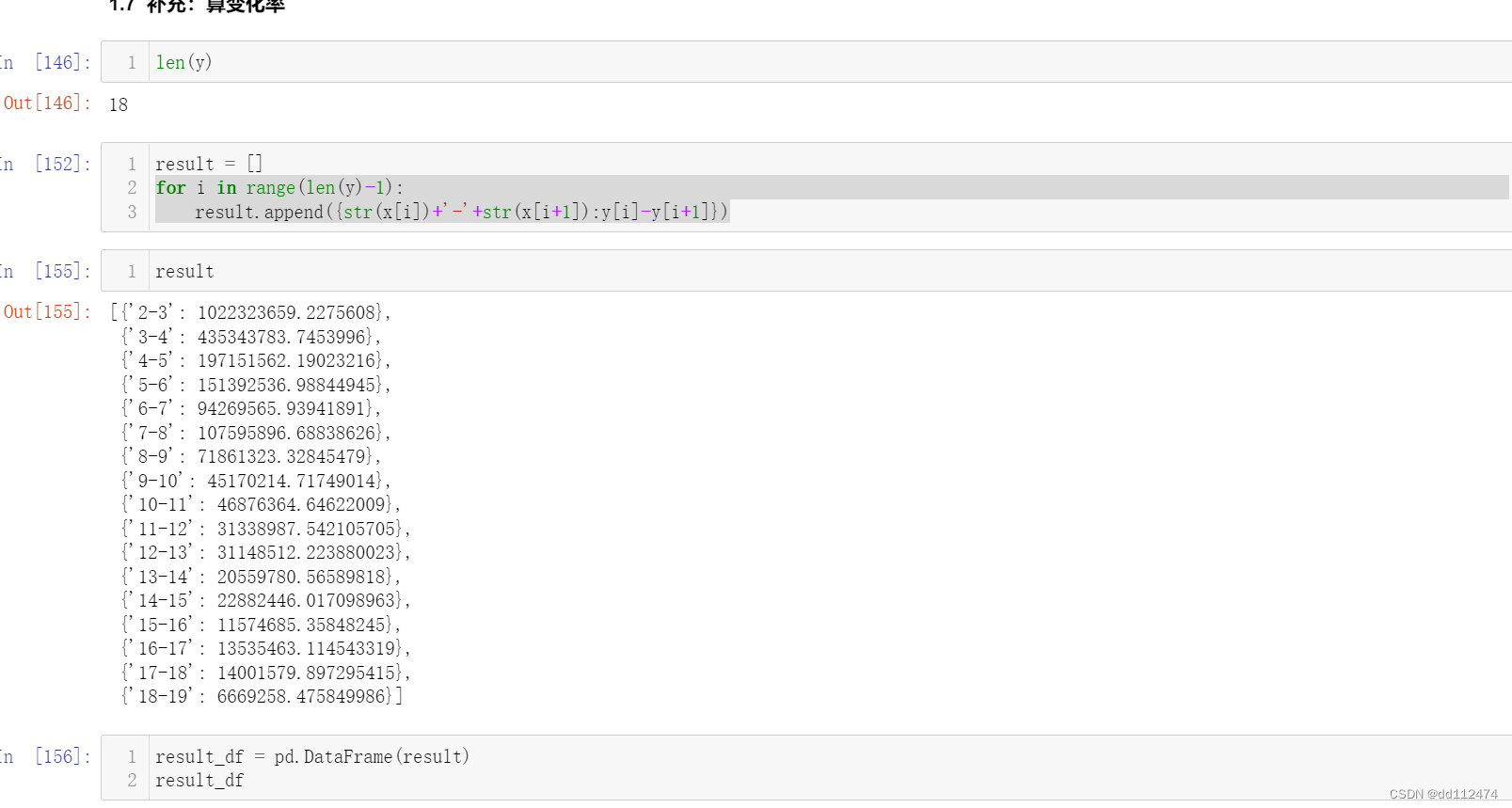
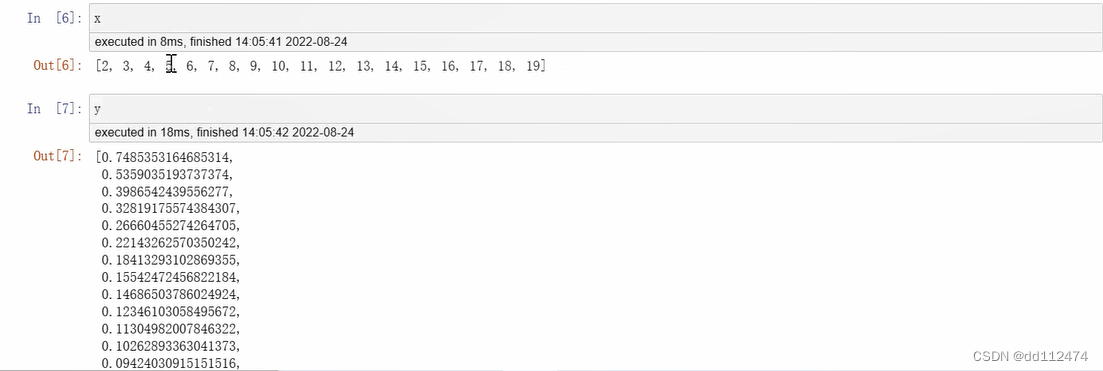
len(y)
result = []
for i in range(len(y)-1):
result.append({str(x[i])+'-'+str(x[i+1]):y[i]-y[i+1]})
result
result_df = pd.DataFrame(result)
result_df
第1次成果拆解
《DBSCAN算法2》剩余36:38开始:
x和y已经得到两个list,只需要遍历到y的个数减一个 len(y)-1
用一个字典储存每一次的key和value
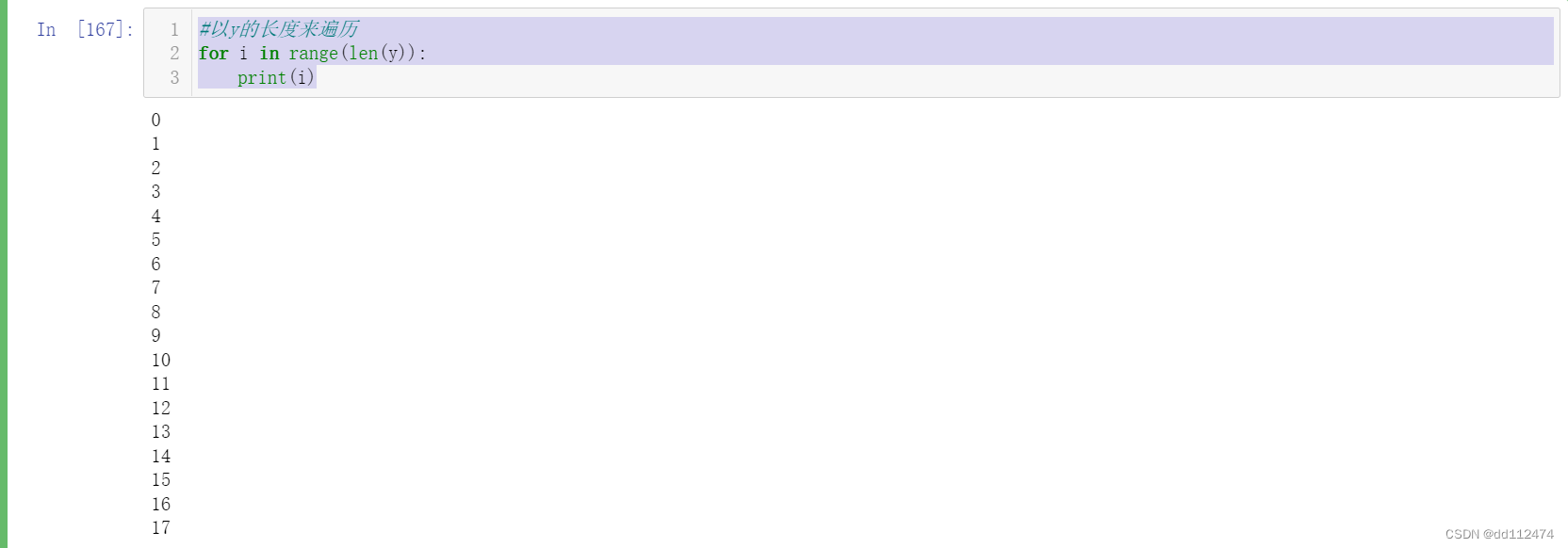
#以y的长度来遍历
for i in range(len(y)):
print(i)
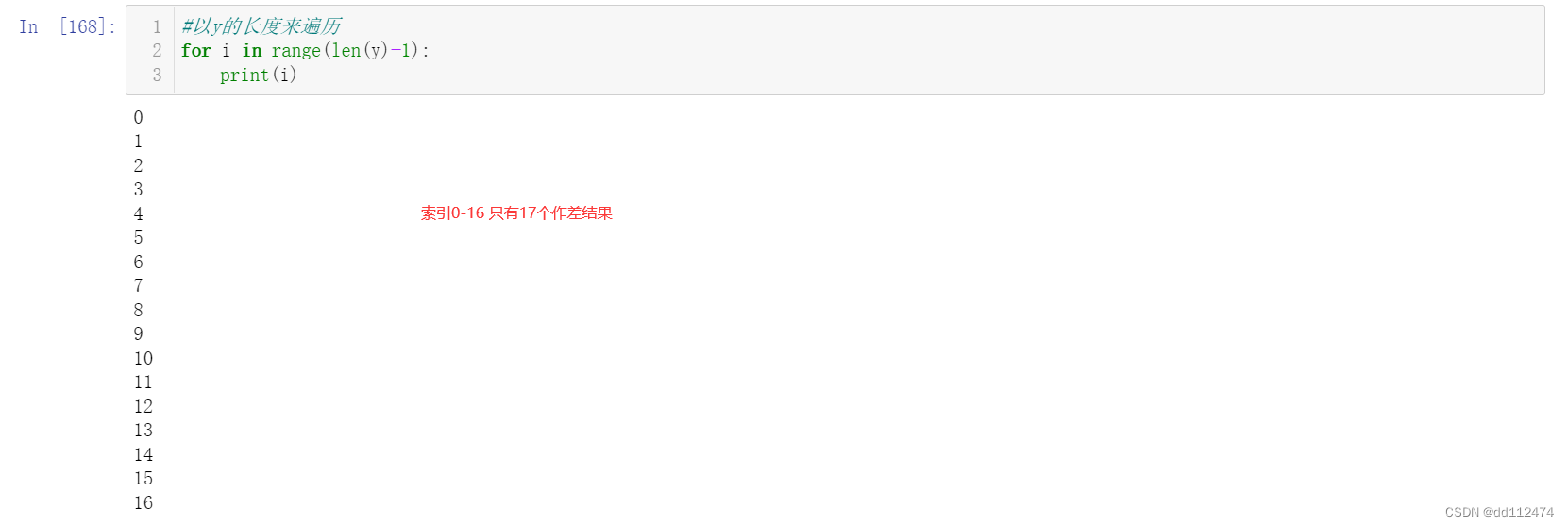
因为作差是 第i+1项 减去 第i项,所以作差遍历的长度为range(len(y)-1),原本18个元素,作差的话就只有17项
构建一个空列表,每次的结果用一个字典追加保存
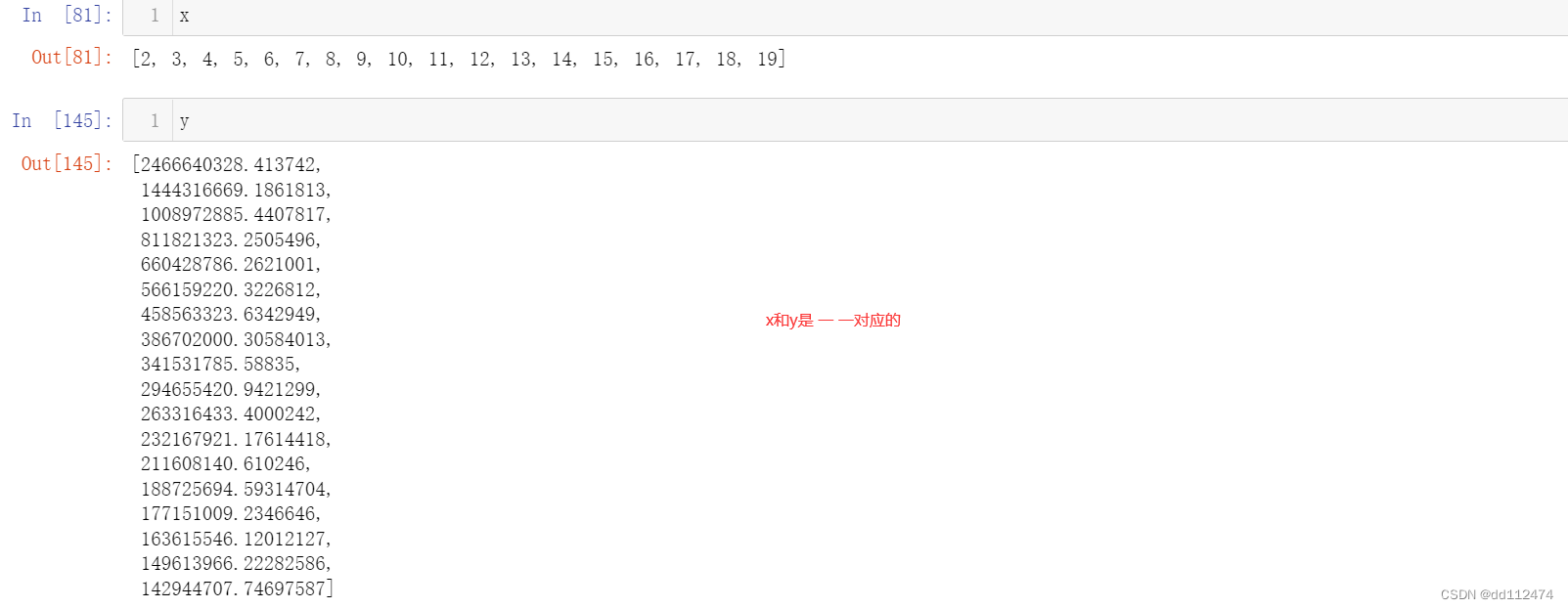
result = []
for i in range(len(y)-1):
result.append({str(x[i])+'-'+str(x[i+1]):y[i+1]-y[i]})
result
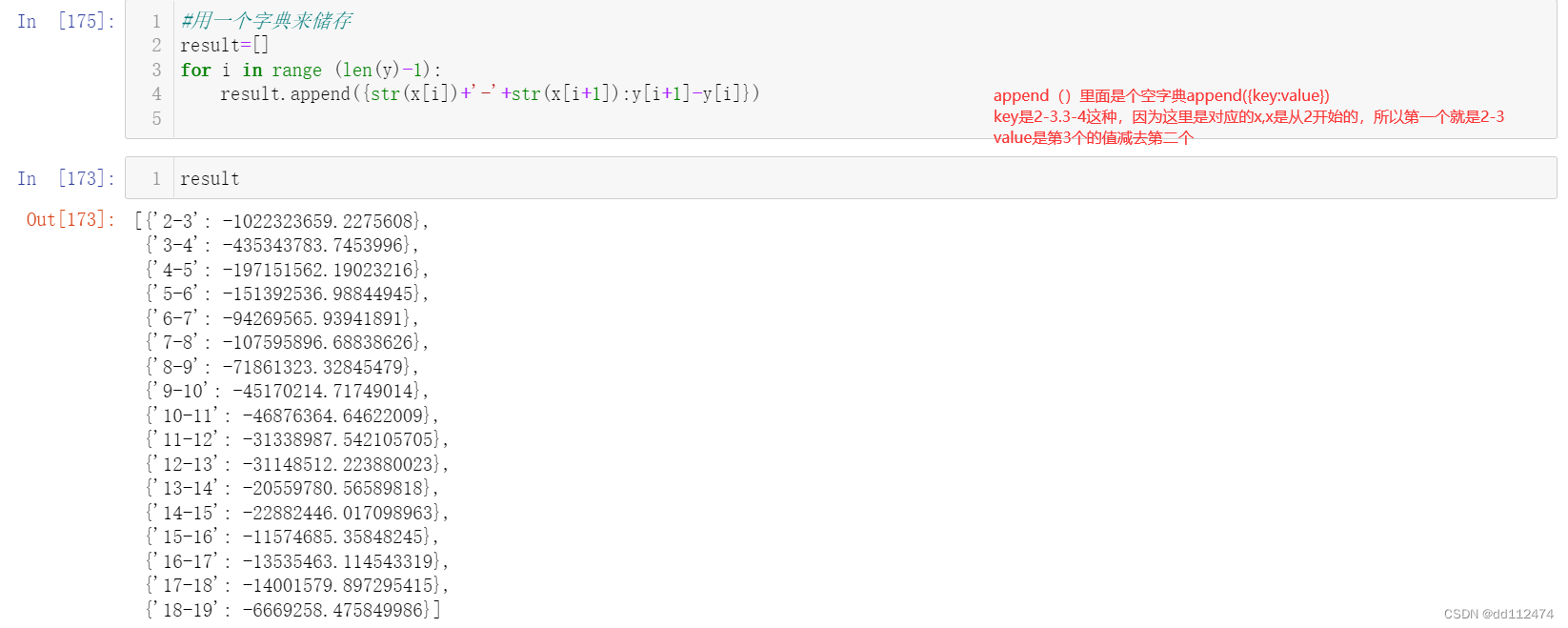
可以看到这里的值是负数,变成正数更方便理解
只需要把字典中的值value变成y[i]-y[i+1]即可(前者减去后者)
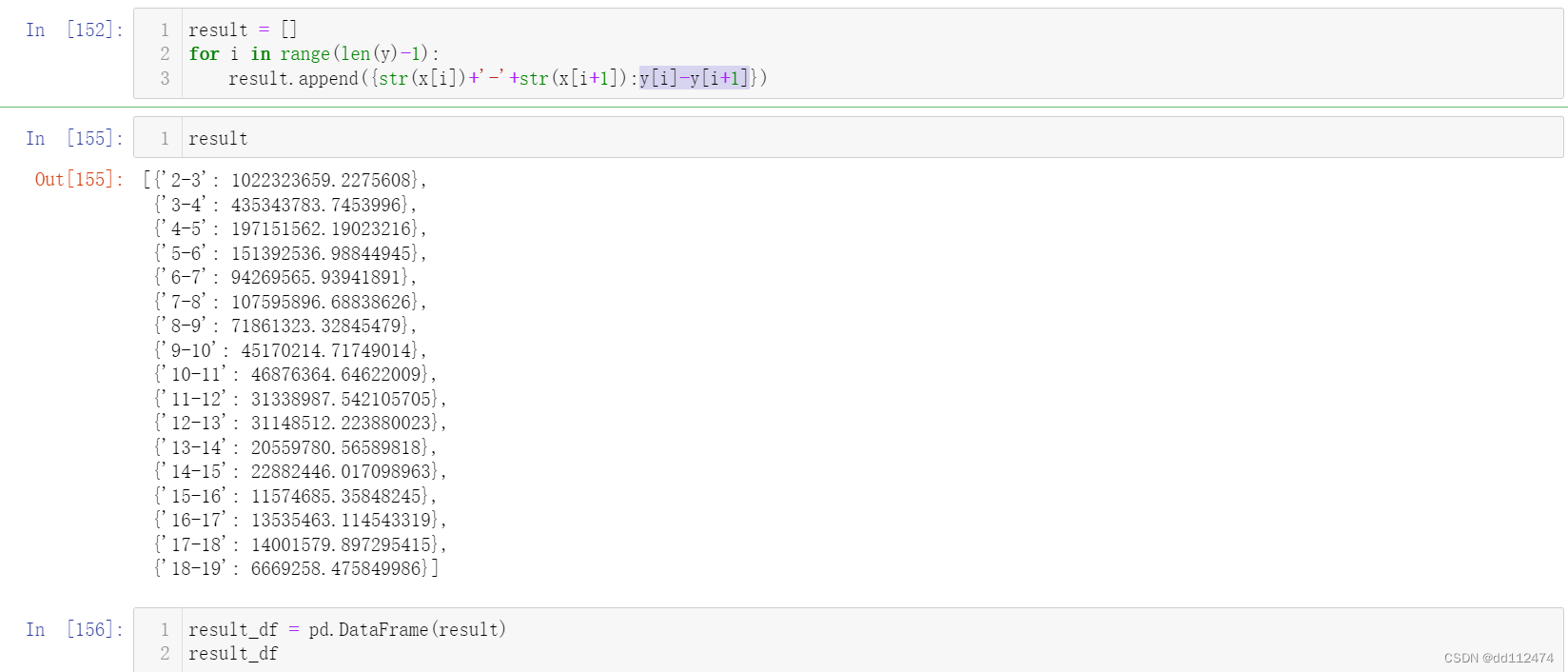
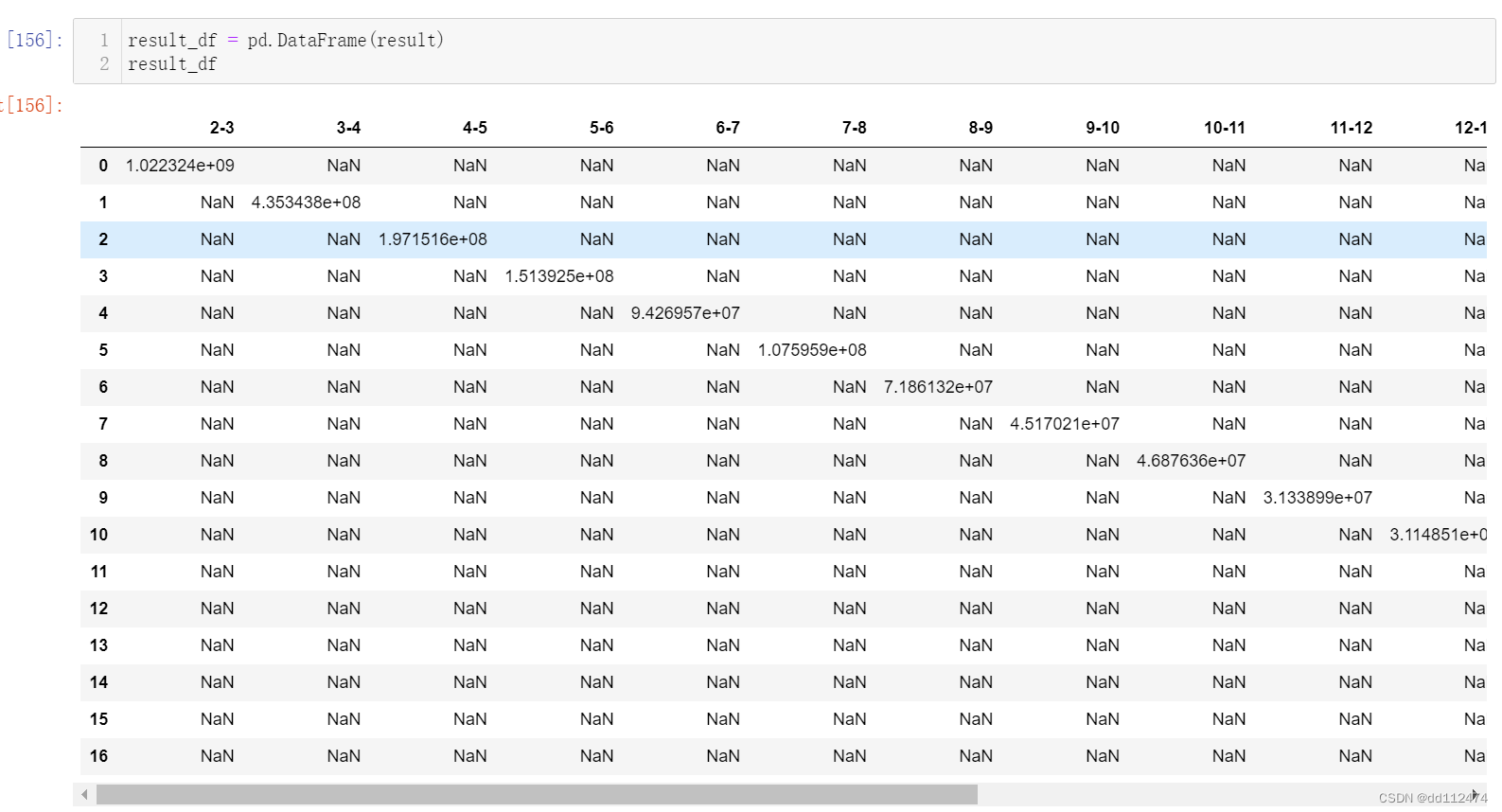
用DataFrame查看
result_df = pd.DataFrame(result)
result_df
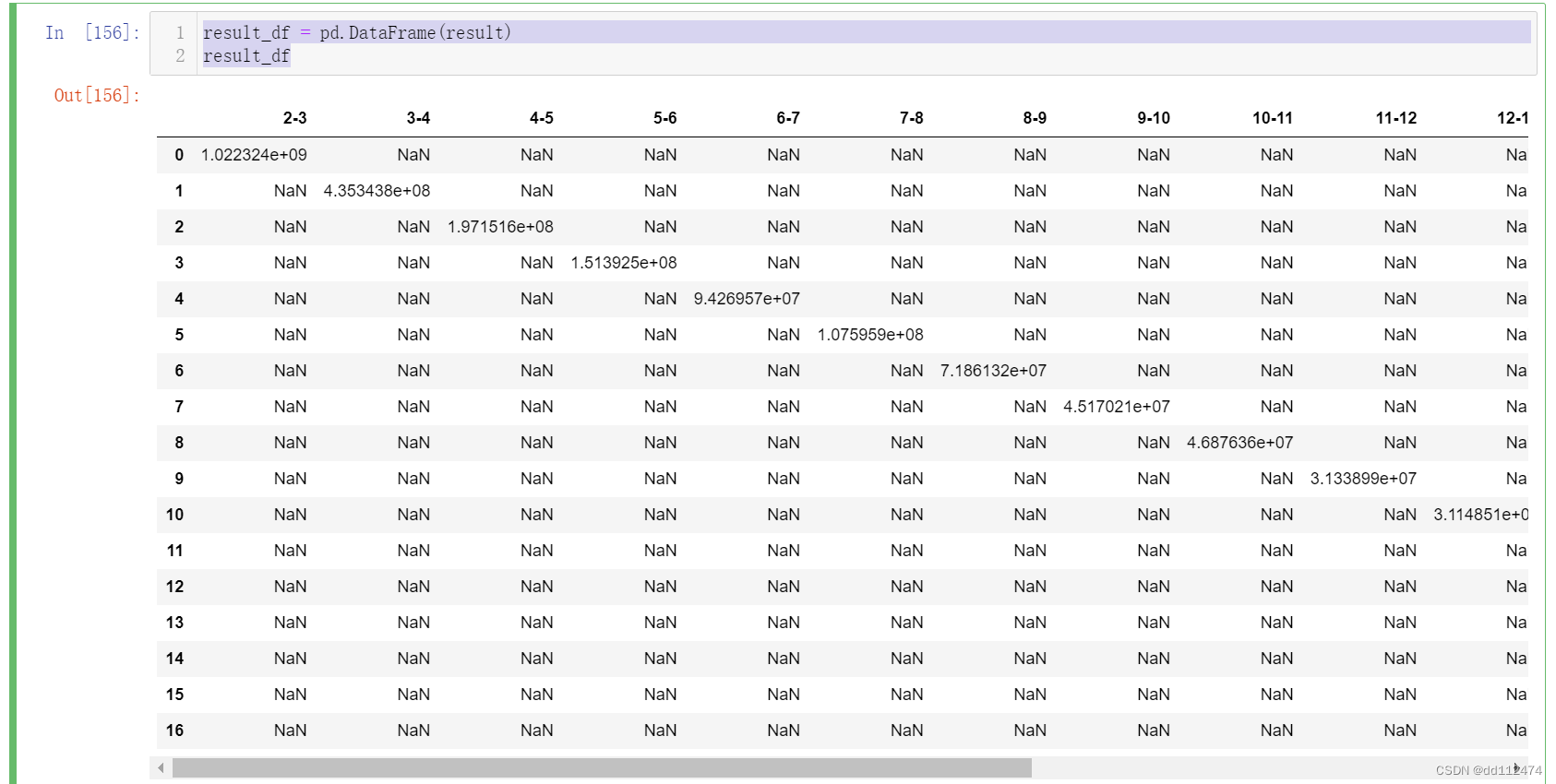
可以发现这个DataFrame由于没有统一的列坐标,所以全部变到对角线上了,下一步我们就单独增设俩列变量,让它变成常见的DataFrame
第2次成果
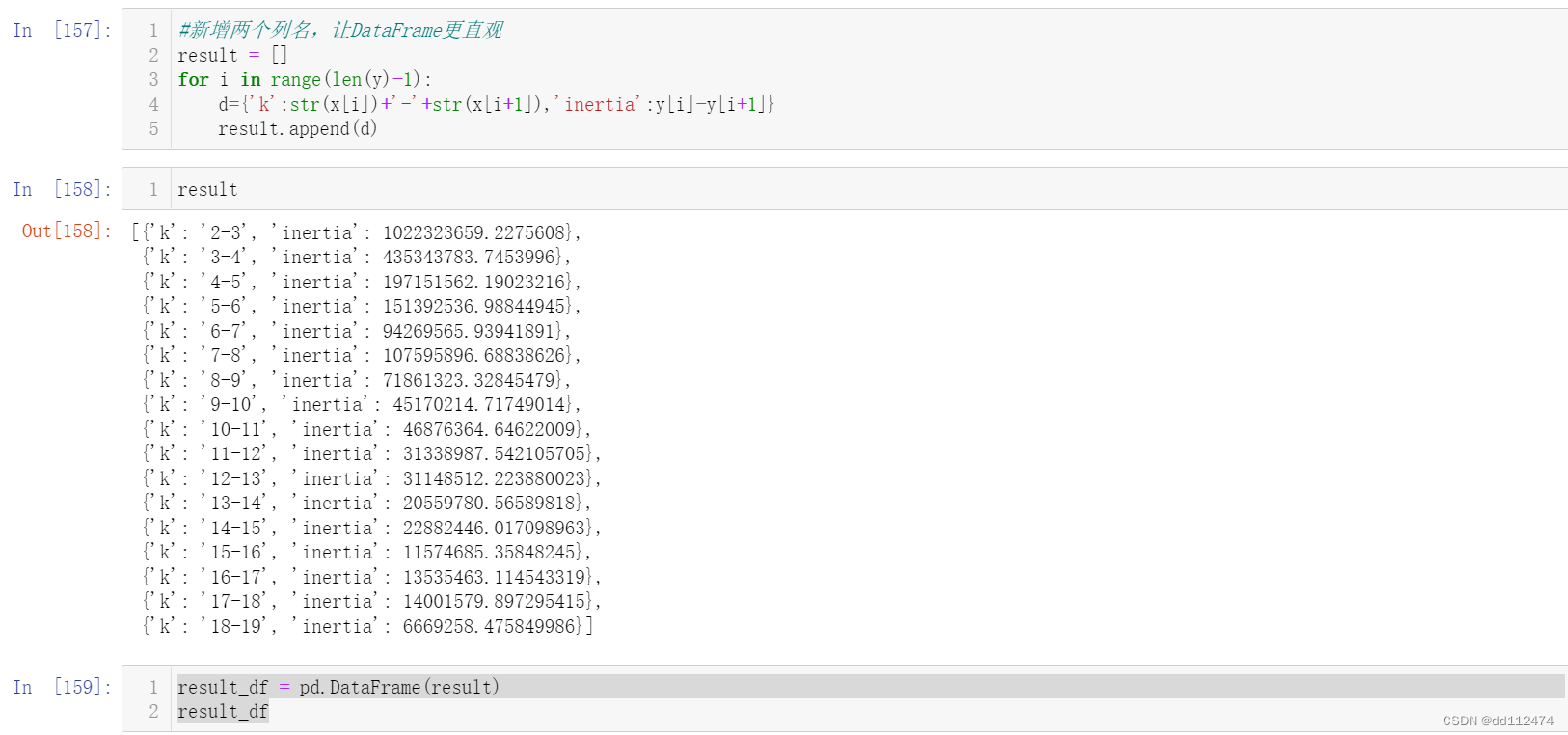

#新增两个列名,让DataFrame更直观
result = []
for i in range(len(y)-1):
d={'k':str(x[i])+'-'+str(x[i+1]),'inertia':y[i]-y[i+1]}
result.append(d)
result
result_df = pd.DataFrame(result)
result_df
第2次成果拆解
先看看Series()是什么效果
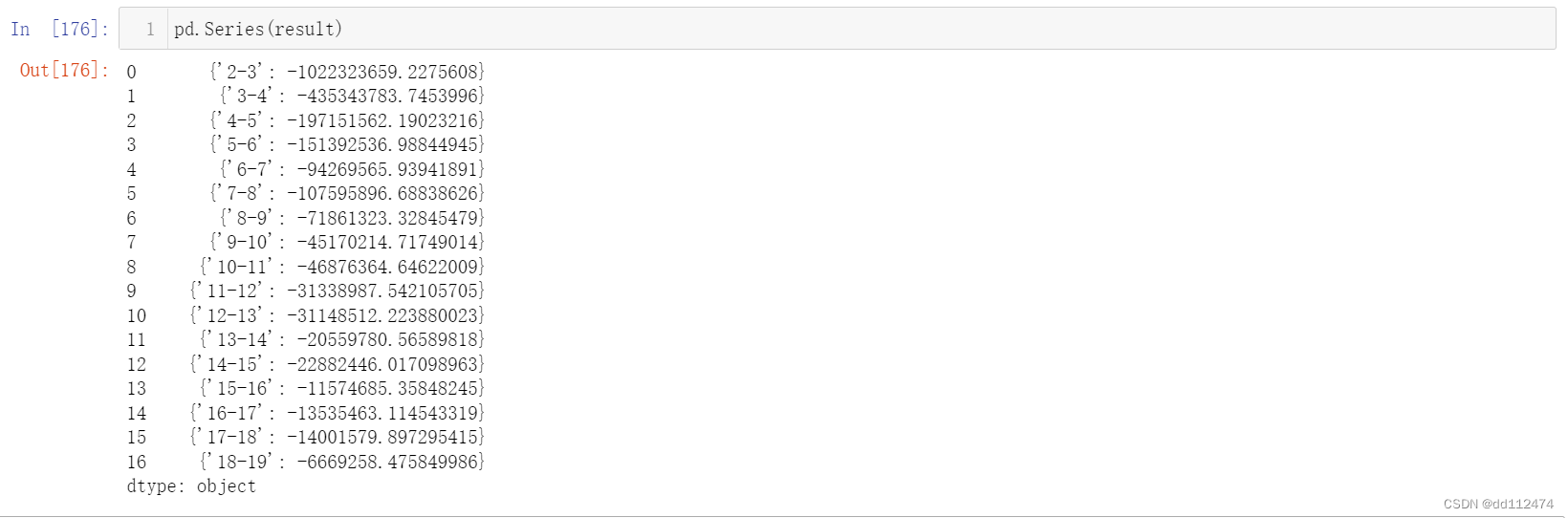
单独把字典d先拎出来,便于理解
result = []
for i in range(len(y)-1):
d = {str(x[i])+'-'+str(x[i+1]):y[i]-y[i+1]}
result.append(d)
只需要把字典里的key和value单独命名一个名字,进行统一即可:
d={'k':str(x[i])+'-'+str(x[i+1]),'inertia':y[i]-y[i+1]}
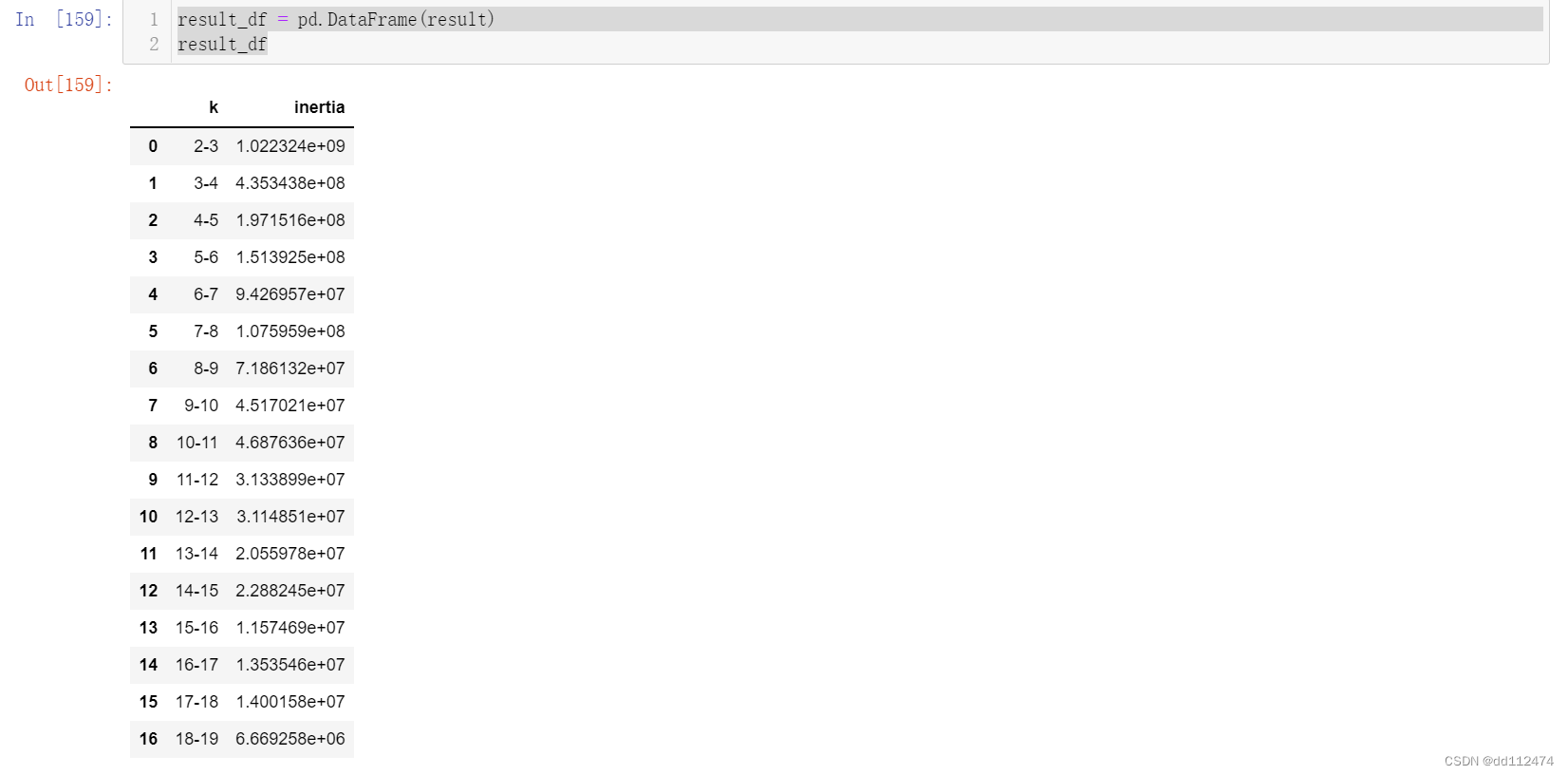
现在已经有了这个结果,还需要我们增加一列比率,我们用bilv表示更加直观的一下子就知道表格哪里变化最明显
现在的代码这么写也可以,单独把k和inertia提出来,对比一下两种写法


第3次成果
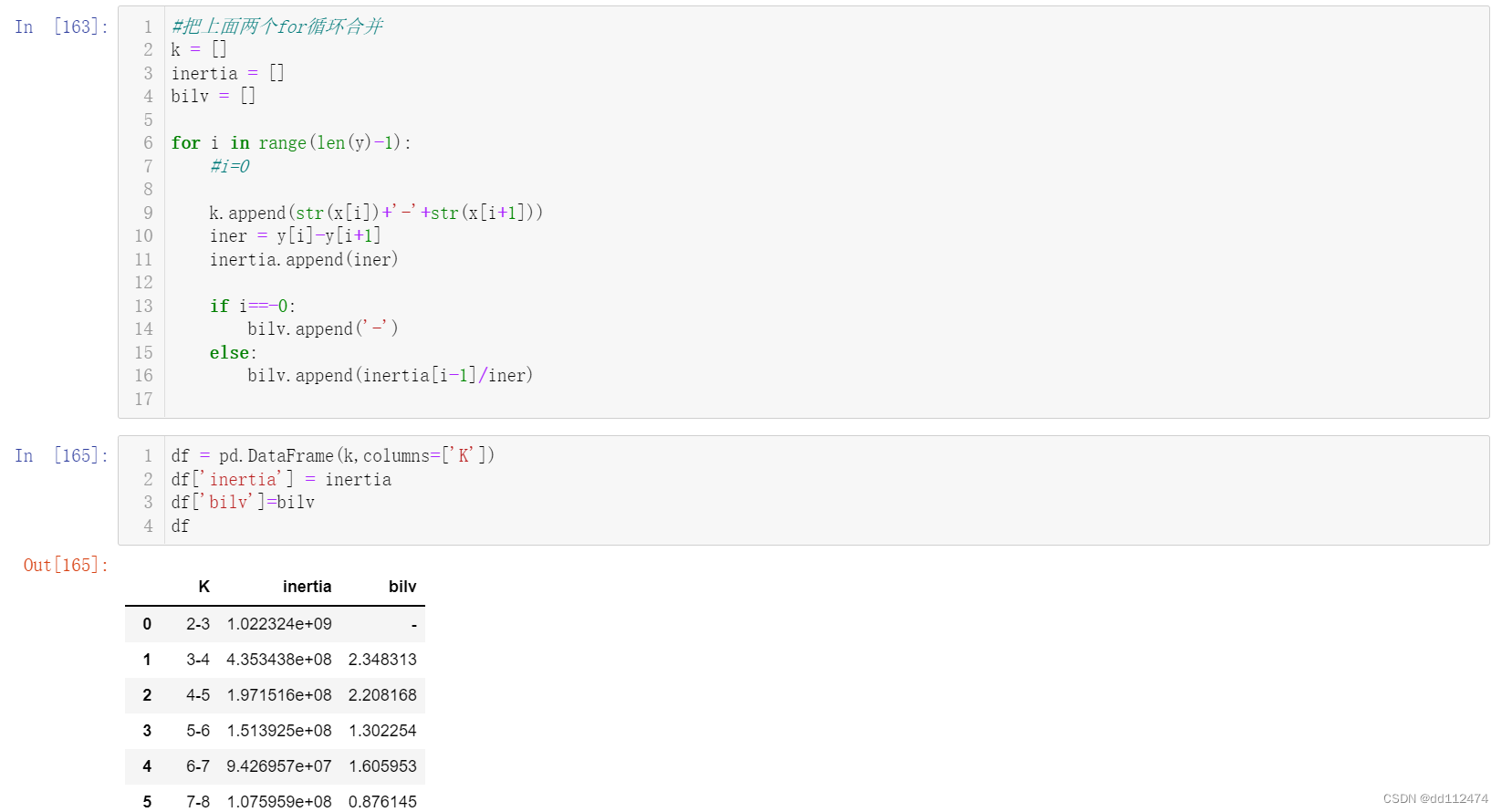
#把上面两个for循环合并
k = []
inertia = []
bilv = []
for i in range(len(y)-1):
#i=0
k.append(str(x[i])+'-'+str(x[i+1]))
iner = y[i]-y[i+1]
inertia.append(iner)
if i==-0:
bilv.append('-')
else:
bilv.append(inertia[i-1]/iner)
df = pd.DataFrame(k,columns=['K'])
df['inertia'] = inertia
df['bilv']=bilv
df
第3次成果拆解
首先有x和y x代表k,y代表inertia
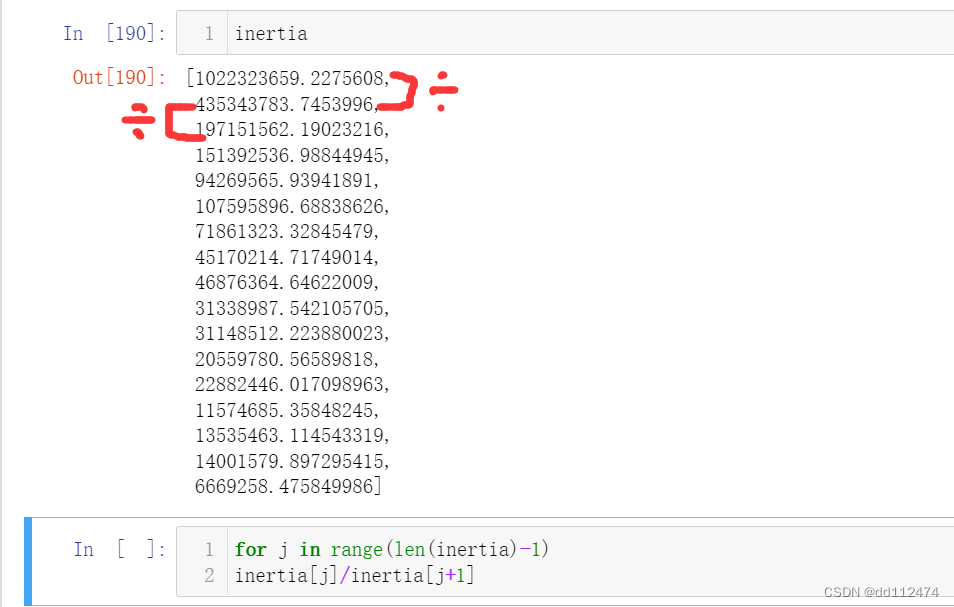
k是聚类个数,inertia是前后两个作差

比率就是前一个÷第二个,总共len(inertia)=17行,运行16次即可
bilv = [inertia[0]] #比率
for j in range(len(inertia)-1):
bilv.append(inertia[j]/inertia[j+1])
bilv
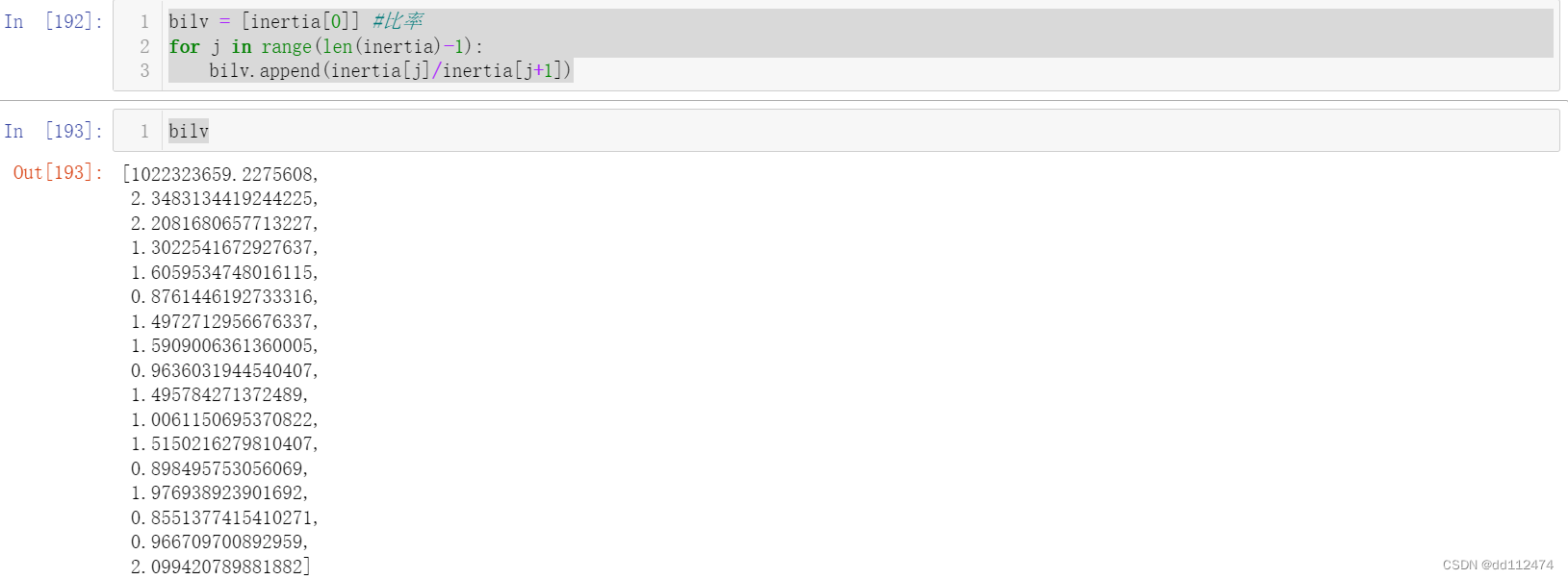
第一个忽略不看,或者写成bilv = ['-'],这样第一个就是-

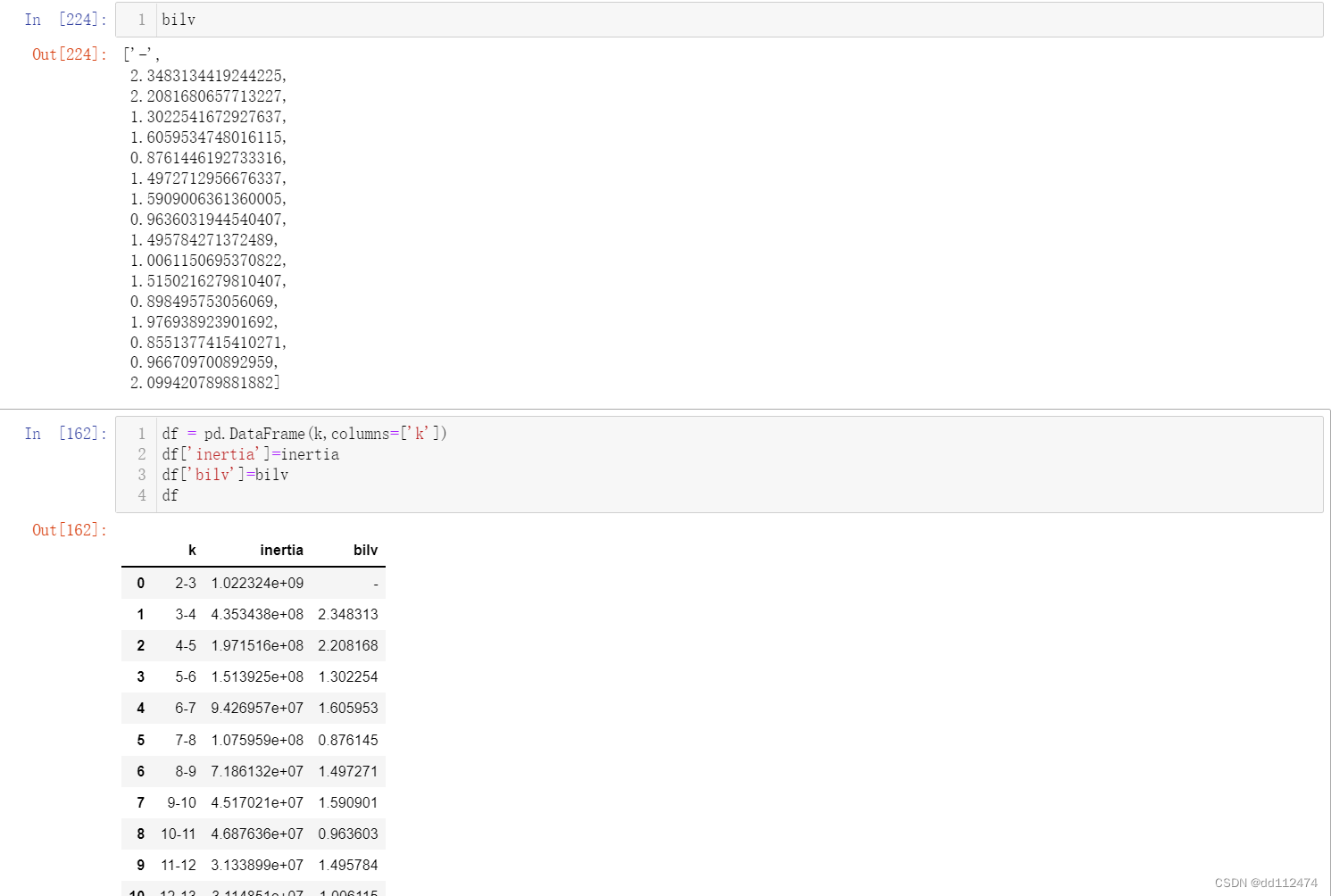
这里我算的有问题,正确的DataFrame:
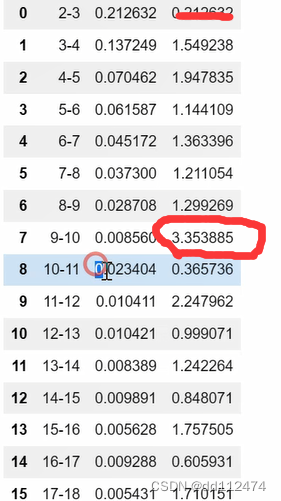
这里的第七个明显变大了,说明前一个比后一个大很多,因此,k取9-10
最后,可以把这两个for循环合二为一(暂时不看这个,太难了)















 359
359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









