







2.1 进行误差分析
Carrying out error analysis
例子 分析开发集误差

在调试猫分类器时,获得90%的准确率,意味着有10%的数据被错分,假设在开发集上10%的数据对应100个样本,若这100个样本中有一些是狗被误分为猫,那么,是否要调整系统使得算法在狗分类上效果更好呢? 此时不能盲目的将算法改进的目标放在提高狗类图片的识别效果上,首先需要对误分样本进行分析,
case1:若100个误分样本中仅有5个是狗类,那么即使算法改进的再好,将狗类全部识别出来那么精度最多提高高90.5%,即性能上限(ceiling on performance)。
case2:若100个误分样本中有50个都是狗类,这样若将狗类全部都正确分类,可以将精度提高到95%,这显然是个不错的努力方向。
简单的对误差进行分析,比如上述的类别人工统计,往往能够花费较少的时间找到更好的改进方向。
例子
误差评估

对误分的数据进行表格统计,并进行相应的标注,可以清楚的分析出,错分数据中每种类型的图片所占的比例,比重越大需要优化的高优先级就越高,不同的比例也能够体现每种优化手段所能带来性能提升的空间。
因此,通过误差分析,有利于明确问题的优先级及算法优化的方向。
2.2 清楚标注错误的数据
Cleaning up Incorrectly labeled data
标签错误的数据是否需要花费时间修正?

训练集上的标注错误:深度学习算法在应对训练集中随机的误差相当鲁棒。如果标签错误的数据离随机误差不远并且训练集足够大,对算法的影响也不会很大,不需要花费过多的时间去修正错误的标签。深度学习算法对系统性误差并没有那么鲁棒,需要加以注意。对误差的性质进行分类也会影像算法的调整策略。
开发集/测试集上的标注错误:
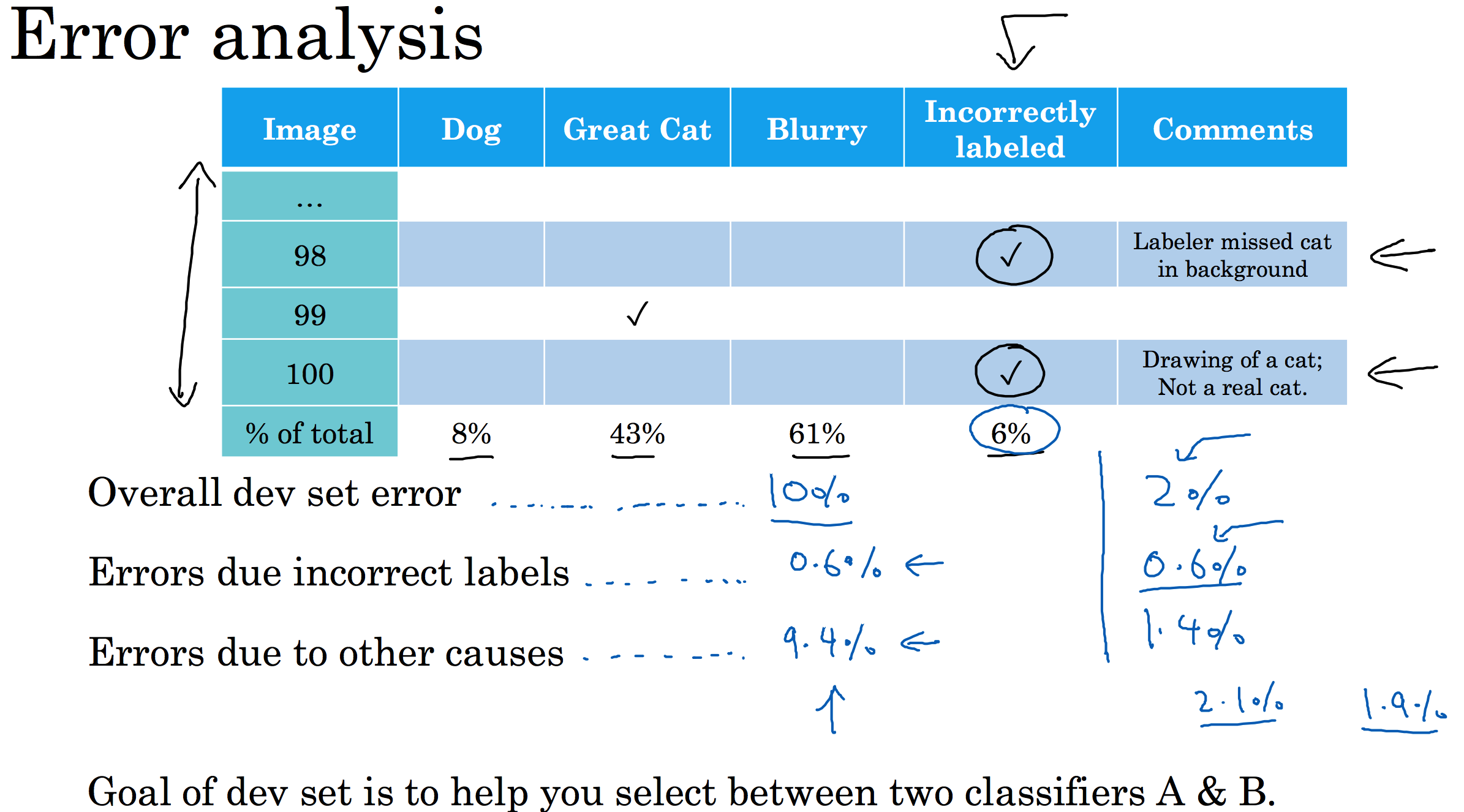
衡量标注错误在开发/测试集上的影响,可以通过误差分析的方式:创建误差分析表格 ——> 添加错标选项 ——> 统计错标样本所占错分的比例 ——> 根据比例计算出错标数据对整体误差的影响 ——> 衡量算法调整策略。
case1: 算法在开发集上的误差为10%,错标样本占据了0.6%,其他原因占据了9.4%。显然这9.4%所带来的影响才是优先考虑的目标,改正错标样本带来的误差虽然也是需要的但是并非首要考虑的方面。
case2:算法在开发集上的误差为2%,错标样本仍占据了0.6%,其他原因占据了1.4%。此时错标数据带来的误差以及达到整体误差的30%,即有大量误差是由错标数据引起的,这种情况下改进错标样本数据会变得更加有意义。
- 开发集和测试集应保证具有相同的分布,对开发集上的操作应该同时应用到测试集上,这样才有利于算法的高效迭代。
- 考虑同时检验算法判断正确和判断错误的样本,仅修正判断出错的样本会使得算法偏差估计变大,但检验判断正确的样本往往会比较耗时。
- 训练集可能/以与开发/测试集的分布稍微不同,深度学习算法也往往有很好的鲁棒性。
建议:
- 构建学习系统时,往往需要更多的人工错误分析,以及人为见解。
- 进行误差分析,亲自对误差样本进行评估,往往会对算法优化的方向、选择策略的方向以及明确任务的优先级有较好的帮助。
2.3 快速搭建你的第一个系统,并进行迭代
Build your first system quickly, then iterate
构建并迭代机器学习系统的步骤:
- 数据集划分(训练/开发/测试),确定性能评价指标。
- 构建一个粗糙的初始系统(quick and dirty implementation)。
- 偏差/方差分析,误差分析,确定改进优化方向,明确任务优先级。
- 快速迭代算法,提升性能。















 2159
2159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









