







本地模式
材料准备
- Linux虚拟机-CentOS7
- hadoop-3.3.1.tar.gz Index of /hadoop/common (apache.org)
- jdk-8u321-linux-x64.tar.gz Java Archive | Oracle
Centos7虚拟机部署
- 准备材料:
- VMware17
- CentOS-7-x86_64-Minimal-2009.iso centos-7-isos-x86_64安装包下载_开源镜像站-阿里云 (aliyun.com)
- 网络配置
- Centos安装配置

安装JDK
-
软件包上传路径:
/root/softwares -
软件包安装路径:
/usr/local -
卸载原有的JDK
rpm -qa | grep jdk # 查询已有的 rpm -e xxxx --nodeps # 将查询到的jdk强制卸载 -
解压安装:
tar -zxvf jdk-8u321-linux-x64.tar.gz -C /usr/local/ -
可能需要:
yum -y install vim* -
环境变量:
vim /etc/profile- 在末尾添加如下:
export JAVA_HOME=/usr/local/jdk1.8.0_321export PATH=$PATH:$JAVA_HOME/bin:wq保存- 生效:
source /etc/profile - 验证:
javac或java -version
安装Hadoop
-
解压安装:
tar -zxvf hadoop-3.3.1.tar.gz -C /usr/local/ -
环境变量:
vim /etc/profile-
在末尾添加:
export HADOOP_HOME=/usr/local/hadoop-3.3.1 -
在
PATH后添加:$HADOOP_HOME/bin:$HADOOP_HOME/sbin -
最终样式:
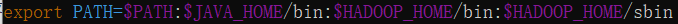
-
生效:
source /etc/profile -
验证:
hadoop version
-
-
cd $HADOOP_HOME/——>ll

案例演示
- WordCount
## 模拟数据
mkdir ~/input
cd input
vim file1 # 在file1中随意地写入一些单词,以空格分隔
for i in {1..1000}; do cat file1 >> file2; done # 循环1000次,每次都将file1里的内容追加到file2中
for i in {1..1000}; do cat file1 >> file2; done # 循环1000次,每次都将file2里的内容追加到file3中
for i in {1..10}; do cat file1 >> file2; done # 循环1000次,每次都将file3里的内容追加到file4中
## 执行运算
cd $HADOOP_HOME/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-3.3.1.jar wordcount ~/input/ ~/output # 注意:output文件夹不能已经存在
## 查看结果
cd ~/output/
cat part-r-00000
- Π(pi)
cd $HADOOP_HOME/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-3.3.1.jar pi 10 10















 1100
1100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









