







先从self-attention说起:






机器翻译,语音辨识
我们先说第一种情况:一对一的情况


一个很大的window(比如cover整个sequence)会导致参数过多,同时也会过拟合




我们现在需要找出一个sequence里和向量a1相关的其它向量,但是我们又不想把他们全部包括在一个window里面,因此我们用到了self-attention机制



注意,这里要计算自己与自己的关联性。
 Soft-max归一化指数函数,不一定用Soft-max,用Relu也是可以的
Soft-max归一化指数函数,不一定用Soft-max,用Relu也是可以的

如果a1和a2关联性很强,那么a'1,2 a'2,1很大,那么b1与b2就会很接近




 不同的q负责不同种类的相关性,这里面q^(i,1)与q^(i,2)负责不同种类的相关性,计算的时候q^(i,1)、k^(i,1)、v^(i,1)是一组, q^(i,2)、k^(i,2)、v^(i,2)是一组
不同的q负责不同种类的相关性,这里面q^(i,1)与q^(i,2)负责不同种类的相关性,计算的时候q^(i,1)、k^(i,1)、v^(i,1)是一组, q^(i,2)、k^(i,2)、v^(i,2)是一组
q有两个那k就有两个那v就有两个


位置的信息,我们之前是没有提供的,这样是不好的,因为有时候在处理问题的时候需要位置的信息,比如POS tagging,词性标注,当我们加上了位置的信息之后,模型通过学习之后,可以学习到动词在句首的可能性比较低。
在文章attention is all you need这篇文章里面,给出了一种方案,不过这种方案是手写的。
不过方案也不是只有这一种,还有其他的方案,甚至位置编码也是可以通过学习出来的


在卷积神经网络中,感受野(receptive field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小。

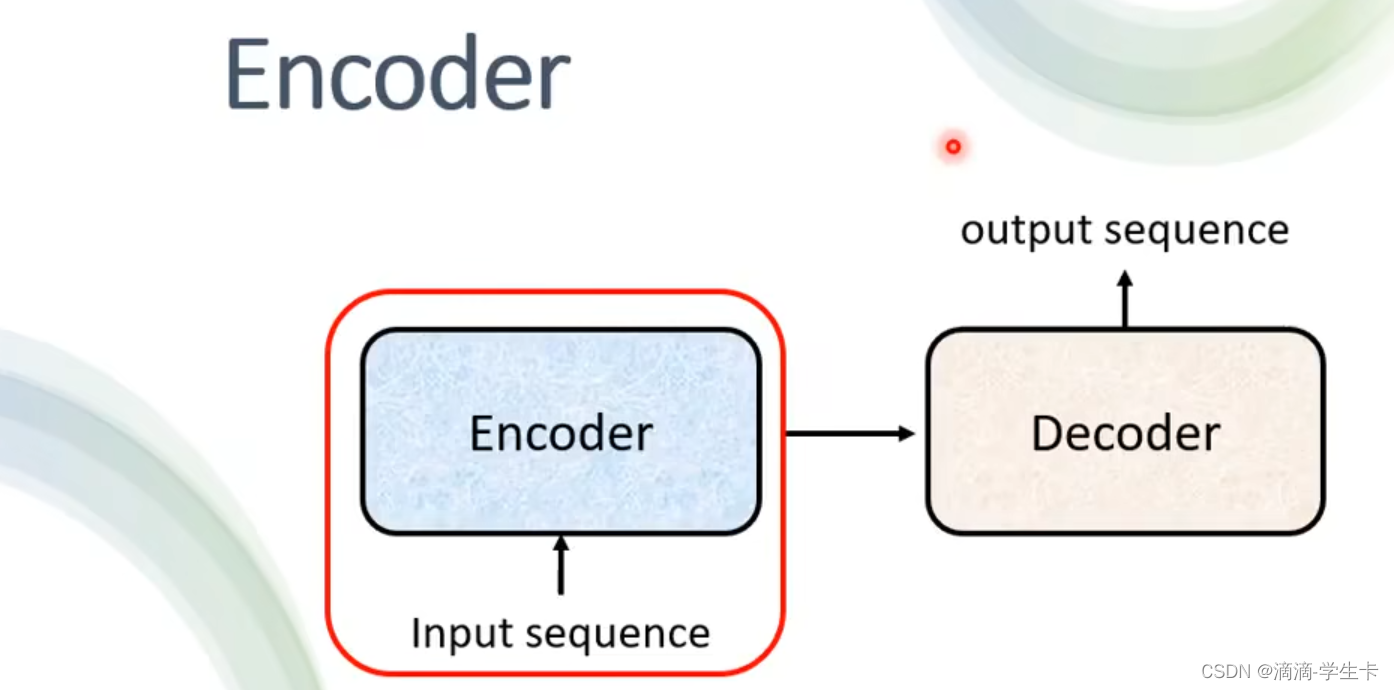

transformer里的encoder用的就是self-attention

encoder是多个block,数量就是Nx,每一个block是下面的组成:



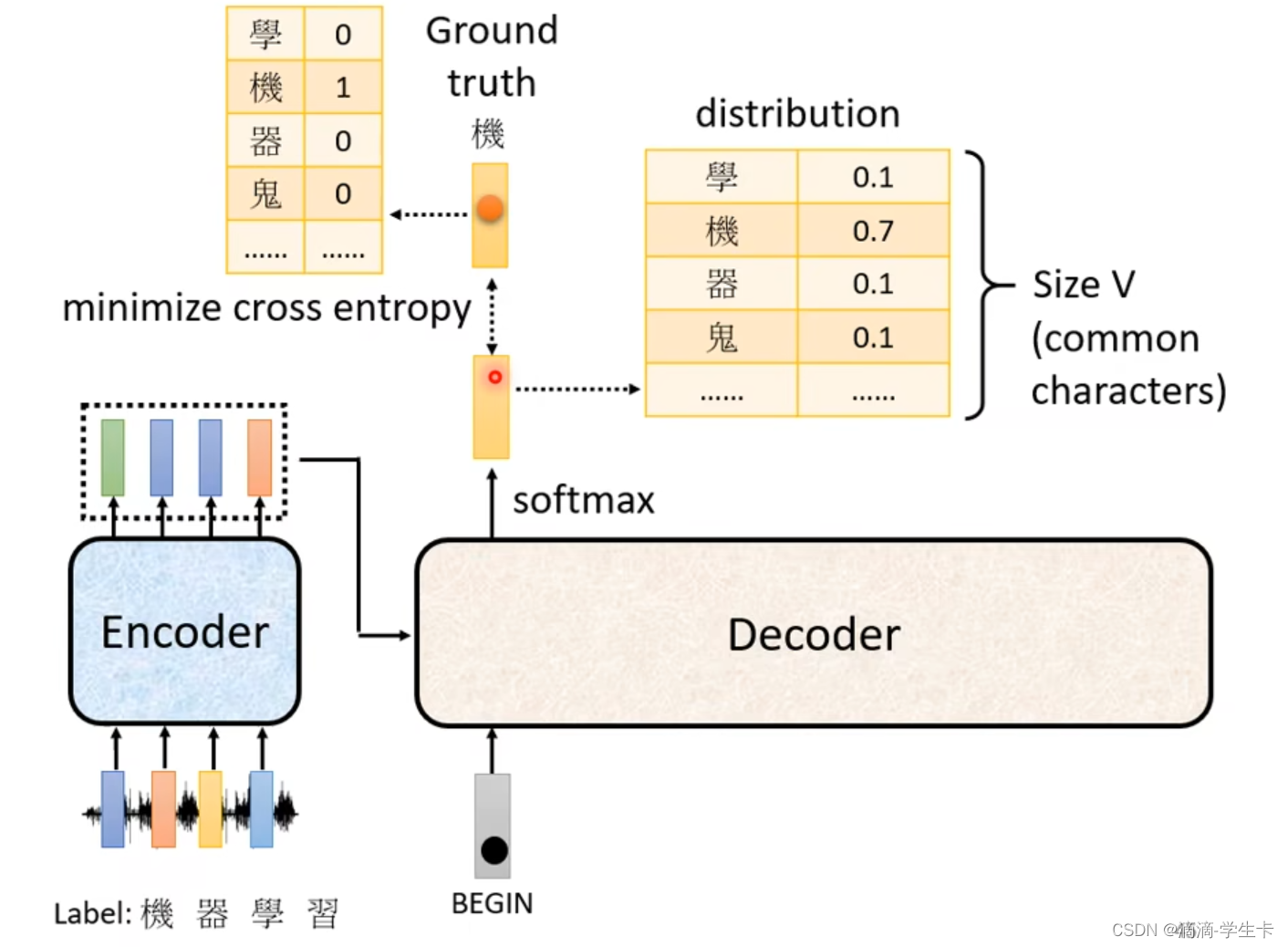
 BEGIN和END都是可以用one-hot表示的
BEGIN和END都是可以用one-hot表示的
Size V如果是中文的识别,那么他的size就是中文方块字的数目




为什么需要这么做?
因为decoder时,是需要一个一个的产生,而encoder时是一排向量全部输入进去,然后一起产生。 所以当需要计算b2时,我们只有a1和a2,而a3和a4是没有的。





以上讲的都是假设模型训练好之后是如何运作的
接下来说模型如何训练















 1380
1380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









