



 本文对比了GPT-3的text-embedding-ada-002模型与其他传统文本嵌入技术(GloVe,Word2vec,MPNet)在Amazon美食评论数据集上的性能。通过对四种嵌入技术生成的嵌入进行机器学习模型训练,评估它们在预测评论评分的准确性。结果显示,GPT-3的嵌入在所有模型中取得了最高精度,显示出其在文本分类任务中的优势。
本文对比了GPT-3的text-embedding-ada-002模型与其他传统文本嵌入技术(GloVe,Word2vec,MPNet)在Amazon美食评论数据集上的性能。通过对四种嵌入技术生成的嵌入进行机器学习模型训练,评估它们在预测评论评分的准确性。结果显示,GPT-3的嵌入在所有模型中取得了最高精度,显示出其在文本分类任务中的优势。
随着NLP(自然语言处理)的最新进展,OpenAI的GPT-3已经成为市场上最强大的语言模型之一。2022年1月25日,OpenAI公布了一个embedding endpoint(Neelakantan et al., 2022)。该神经网络模型将文本和代码转换为向量表示,将它们嵌入到高维空间中。这些模型可以捕获文本的语义相似性,并且在某些用例中似乎实现了最先进的性能。

由于chatgpt的大火,GPT-3又进入到了人们的视野中,本文将通过使用text-embedding-ada-002(GPT-3的一个Embeddings,选择该模型是因为它价格适中且使用简单),与三种传统文本嵌入技术生成的嵌入的性能进行比较;GloVe(Pennington、Socher Manning,2014 年)、Word2vec(Mikolov ,2013 年)和 MPNet(Song ,2020 年)。这些嵌入将用于训练多个机器学习模型,使用Amazon美食评论数据集中的食品评论评分进行分类。每种嵌入技术的性能将通过比较它们的准确性指标来评估。
数据准备
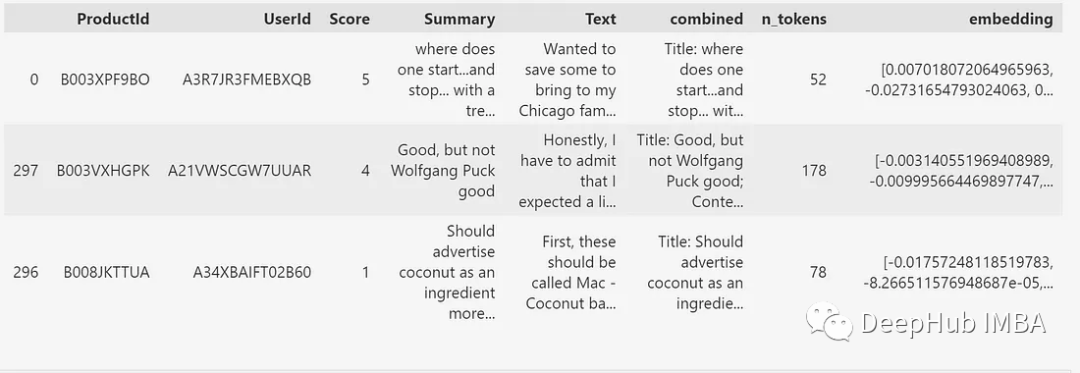
本文中使用的数据集是来自Amazon美食评论数据集的1000个数据集的子集。这个子集包含了使用GPT-3的“text- embedded -ada-002”模型已经生成的嵌入。嵌入是由标题(摘要)和文本的组合生成的。如图1所示,每个评论还具有ProductId、UserId、Score和从组合文本生成的令牌数量。
# Libraries
fromsentence_transformersimportSentenceTransformer
fromsklearn.model_selectionimporttrain_test_split
fromsklearn.linear_modelimportLogisticRegression
fromsklearn.ensembleimportRandomForestClassifier
fromsklearn.metricsimportclassification_report
fromsklearn.treeimportDecisionTreeClassifier
fromsklearn.preprocessingimportRobustScaler
fromsklearn.pipelineimportPipeline
importgensim.downloaderasapi
fromsklearn.svmimportSVC
importpandasaspd
importnumpyasnp
importopenai
importre
# import data
df1=pd.read_csv('https://raw.githubusercontent.com/openai/openai-cookbook/main/examples/data/fine_food_reviews_with_embeddings_1k.csv',
index_col=0)
# view first three rows
df1.head(3)
对于换行符和空格会影响我们将嵌入表示为数组。所以需要一个函数来删除不必要的字符并将嵌入转换为适当的数组格式。GPT-3嵌入变量的名称也将更改为’ gpt_3 ',这样可以区别本文后面生成的其他嵌入。
# clean openai embeddings
defclean_emb(text):
# remove line break
text=re.sub(r'\n', '', text)
# remove square brackets
text=re.sub(r'\[|\]', "", text)
# remove leading and trailing white spaces
text=text.strip()
# convert string into array
text=np.fromstring(text, dtype=float, sep=',')
returntext
# Rename column to gpt_3
df1.rename(columns={'embedding': 'gpt_3'}, inplace=True)
# Apply clean_emb function
df1['gpt_3'] =df1['gpt_3'].apply(lambdax: clean_emb(x))
GPT-3嵌入
数据集包含预先生成的基于gpt -3的嵌入。但是我们为了生成最新的嵌入,还需要一个API密钥来访问模型。该密钥可以通过注册OpenAI API来获得。然后就是创建一个函数,指定要使用的模型(在本例中为text-embedding-ada-002)。
api_key='api key'
# set api key as default api key for openai
openai.api_key=api_key
defget_embedding(text, model="text-embedding-ada-002"):
# replace new lines with spaces
text=text.replace("\n", " ")
# openai.Embedding.create to convert text into embedding array
returnopenai.Embedding.create(input= [text], model=model)['data'][0]['embedding']
因为都是获取API的返回结果,所以这个过程非常简单。
GloVe嵌入
GloVe(用于词表示的全局向量)是一种文本嵌入技术,它根据词在大量文本中的共现统计来构建词的向量表示。GloVe 的想法是,在可比较的情况下出现的词在语义上是相关的,并且可以使用通过共现矩阵统计它们的共现来推断这些词之间的联系。
使用 spaCy 库可以轻松的生成基于 GloVe 的嵌入。这里我们使用“en_core_web_lg”英语管道。该管道对给定的文本输入执行一系列步骤,例如标记化、标记和词形还原,以将其转换为合适的格式。该管道包含 514,000 个向量,对于当前的用例来说已经足够大了。
GloVe是14年发布的,虽然到现在都快10年了,但是在transformers出现之前GloVe可以说是最成功的词嵌入方法,所以这里我们还是要拿他来进行以下对比
importspacy
# load pipeline
nlp=spacy.load("en_core_web_lg")
这里我们也需要进行文本清理。如上图 2 所示,在第一个文本输入中连续出现了一些句号。这种模式必须加以纠正。
df1.combined[0]

我们创建一个函数,用单个句号替换连续的句号,并删除句子末尾的空格。
defreplace_multiple_fullstops(text):
# replace 2 or more consecutive fullstops with 1
text=re.sub(r'\.{2,}', '.', text)
# strip white spaces from ends of sentence
text=text.strip()
returntext
# Apply function
df1['clean_text'] =df1['combined'].apply(lambdax: replace_multiple_fullstops(x))
然后就可以在清理过程之后生成嵌入。
df1['glove'] =df1['clean_text'].apply(lambdatext: nlp(text).vector)
Word2vec嵌入
word2vec技术是基于一个经过大量文本训练的神经网络模型,从其周围的上下文单词中预测目标单词。Word2vec的工作原理是用一个连续向量来表示词汇表中的每个单词,该向量捕获了使用该单词的含义和上下文。这些向量是通过无监督学习过程生成的,神经网络模型尝试预测给定上下的单词。
Gensim库可用于加载在word2vec技术上训练的模型。Gensim库中的“word2vic - Google - News -300”模型是在谷歌News数据集上训练的,该数据集约有1000亿个单词,能够表示数据集中的大部分单词(。
importgensim.downloaderasapi
# Load word2vec-google-news-300 model
wv=api.load("word2vec-google-news-300")
因为Gensim库提供的是模型而不是管道,所以在使用word2vec模型生成向量表示之前,还需要使用spaCy库对文本输入进行标记化、清理和lemm化。
defwv_preprocess_and_vectorize(text):
# Process the input text using a natural language processing library
doc=nlp(text)
# Initialize a list to store the filtered tokens
filtered_tokens= []
# Loop through each token in the doc
fortokenindoc:
# If the token is a stop word or punctuation, skip it
iftoken.is_stoportoken.is_punct:
continue
# Otherwise, add the lemma of the token to the filtered_tokens list
filtered_tokens.append(token.lemma_)
# If there are no filtered tokens, return np.nan
ifnotfiltered_tokens:
returnnp.nan
else:
# Otherwise, return the mean vector representation of the filtered tokens
returnwv.get_mean_vector(filtered_tokens)
# Apply function
df1['word2vec'] =df1['clean_text'].apply(lambdatext: wv_preprocess_and_vectorize(text))
MPNet嵌入(BERT)
MPNet(Masked and Permuted Language Model Pre-training)是一种用于NLP的基于transformer的语言模型预训练技术。MPNet提供了BERT模型的变体。BERT在预训练期间屏蔽一部分输入令牌,并训练模型根据未屏蔽令牌的上下文预测已屏蔽令牌。这个过程被称为掩码语言建模,它对于捕获文本语料库中单词的含义和上下文是有效的。除了屏蔽语言建模之外,MPNet还采用了一种随机排列输入标记顺序的排列机制。这种排列有助于模型学习输入序列中单词之间的全局上下文和关系。
我们这里使用hug Face的句子转换模型“all-mpnet-base-v2”来获取基于mpnet的嵌入。该模型建立在MPNet基础模型的基础上,并对10亿句对数据集进行微调。
model_sent=SentenceTransformer('all-mpnet-base-v2')
df1['mpnet'] =df1['clean_text'].apply(lambdatext: model_sent.encode(text))
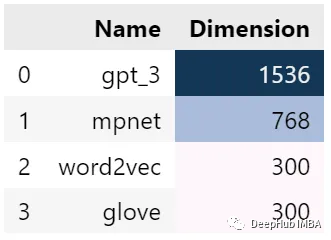
维度比较
下图3显示了每种嵌入的不同维度。GPT-3的最大维度为1536。然后是MPNet、Word2vec和GloVe,分别为768、300和300维。
# assign data of lists.
data= {'Name': ['gpt_3', 'mpnet', 'word2vec', 'glove'],
'Dimension': [len(df1.gpt_3[0]), len(df1.mpnet[0]),
len(df1.word2vec[0]), len(df1.glove[0])]}
# Create DataFrame
df_emb_len=pd.DataFrame(data)
# Set background style
df_emb_len.style.background_gradient()
评估使用的模型
为了评估文本嵌入的性能,我们使用了四个分类器;随机森林、支持向量机、逻辑回归和决策树对Score变量进行预测。数据集将被分成75:25的训练与测试集来评估准确性。由于嵌入是二维的,因此在训练之前将使用numpy函数将它们转换为单个三维数组。
# Define a list of embedding methods to evaluate
embedding_var= ['gpt_3', 'mpnet', 'word2vec', 'glove']
# Define a list of classifier models to use
classifiers= [('rf', RandomForestClassifier(random_state=76)),
('svm', SVC(random_state=76)),
('lr', LogisticRegression(random_state=76, max_iter=400)),
('dt', DecisionTreeClassifier(random_state=76))]
# Define a dictionary to store accuracy results for each classifier
accuracy_lists= {
'rf': [],
'svm': [],
'lr': [],
'dt': []
}
# Loop through each embedding method
forembinembedding_var:
# Split the data into training and testing sets using the 'train_test_split' function
X_train, X_test, y_train, y_test=train_test_split(
df1[emb].values,
df1.Score,
test_size=0.25,
random_state=76
)
# Stack the training and testing sets into 3D arrays
X_train_stacked=np.stack(X_train)
X_test_stacked=np.stack(X_test)
# Loop through each classifier model
forclassifier_name, classifierinclassifiers:
# Create a pipeline that scales the data and fits the classifier
pipe=Pipeline([('scaler', RobustScaler()), (classifier_name, classifier)])
pipe.fit(X_train_stacked, y_train)
# Use the pipeline to make predictions on the test data
y_pred=pipe.predict(X_test_stacked)
# Evaluate the accuracy of the predictions
report=classification_report(y_test, y_pred ,output_dict=True)
acc=report['accuracy']
# Store the accuracy results for each classifier
accuracy_lists[classifier_name].append(acc)
结果
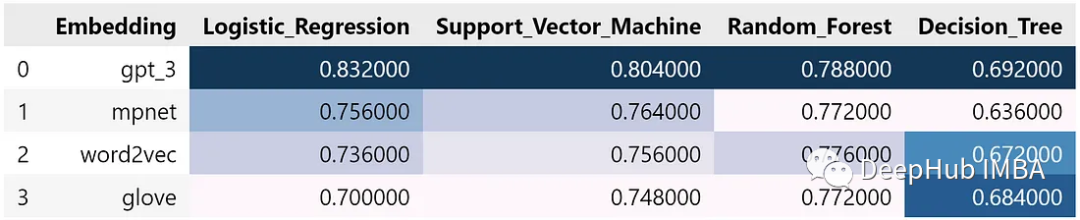
下图4所示,模型呈现了一些有趣的结果。GPT-3嵌入在所有模型中获得了最高的精度。MPNet嵌入在使用逻辑回归和支持向量机时表现次之,但在随机森林算法中被word2vec嵌入超越,在决策树算法中表现最差。关于维数对模型性能的影响,还不能得出明确的结论,但是从结果中可以明显看出,GPT-3嵌入始终优于所有其他嵌入,显示了其在文本分类方面的优势。
# Add a new key 'embeddings' to the dictionary 'accuracy_lists' and assign the list 'embedding_var' to it
accuracy_lists['embeddings'] =embedding_var
# Create a list of tuples using the values from the dictionaries
df_zip=list(zip(accuracy_lists['embeddings'], accuracy_lists['lr'], accuracy_lists['svm'], accuracy_lists['rf'], accuracy_lists['dt']))
# Create a DataFrame 'df_accuracy' from the list 'df_zip' and specify the column names
df_accuracy=pd.DataFrame(df_zip, columns= ['Embedding','Logistic_Regression','Support_Vector_Machine', 'Random_Forest','Decision_Tree'])
# Add a background gradient to the DataFrame for visual representation
df_accuracy.style.background_gradient()
所以还是那句话"别问,问就是GPT3"😏
如果你想自行测试,本文的代码在这里:
https://avoid.overfit.cn/post/58e8c9b6ed3d44a0ba777f89d193f76e
作者:Derrick Owusu Ofori

















 1945
1945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









