







向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
文章之前,我们先来明确检测类任务都在干些什么:
需求:
对图像中的特定种类目标做出分类,并求出目标在图像中所处的位置即最终需要的信息:
object-classes_name
object-position
在一般的检测任务中类别信息通常由索引代替,例如1-> apple,2 - > cat,3 - > dog,… > 而位置一般可以由两组坐标代替:> 矩形的左上角,右下角坐标(x1,y1,x2,y2)
Faster R-CNN作为两阶段检测网络发展中最重要的一个网络,基本可以视为检测任务的里程碑性成果。
延伸扩展的MaskRCNN,CascadeRCNN都成为了2019年这个时间点上除了各家AI大厂私有网络范围外,支撑很多业务得以开展的基础。所以,Pytorch为基础来从头复现FasterRCNN网络是非常有必要的,其中包含了太多的招数和理论中不会包括的先验知识。
甚至,以Faster RCNN为基础去复现其他的检测网络 所需要的精力和时间都会大大降低
我们的目标:用最简洁,最贴合原文得写法复现Resnet - Faster R-CNN
注:> > 本文中的代码为结构性示例的代码片段,不能够复制粘贴直接运行
架构
VGG16-19因为参数的急剧膨胀和深层结构搭建导致参数量暴涨,网络在反向传播过程中要不断地传播梯度,而当网络层数加深时,梯度在逐层传播过程中会逐渐衰减,导致无法对前面网络层的权重进行有效的调整。
因此vgg19就出现了它的局限性。
而在之后提出的残差网络中,加入了短连接为梯度带来了一个直接向前面层的传播通道,缓解了梯度的减小问题,同时,将整个网络的深度加到了100层+,甚至后来的DenseNet出现了实用的200层+网络。并且大量使用了1 * 1卷积来降低参数量因此本文将尝试ResNet 101 +FasterRCNN,以及衔接DenseNet和FasterRCNN的可能性。
从以上图中我们可以看出Faster R-CNN除了作为特征提取部分的主干网络,剩下的最关键的也就是以下部分
RPN`
RPN LossFunction
ROI Pooling
Faster-R-CNN Loss Function
也就是说我们的复现工作要着重从这些部分开始。现在看到的最优秀的复现版本应该是Jianwei Yang page
本文的代码较多的综合了多种写法,以及pytorch标准结构的写法
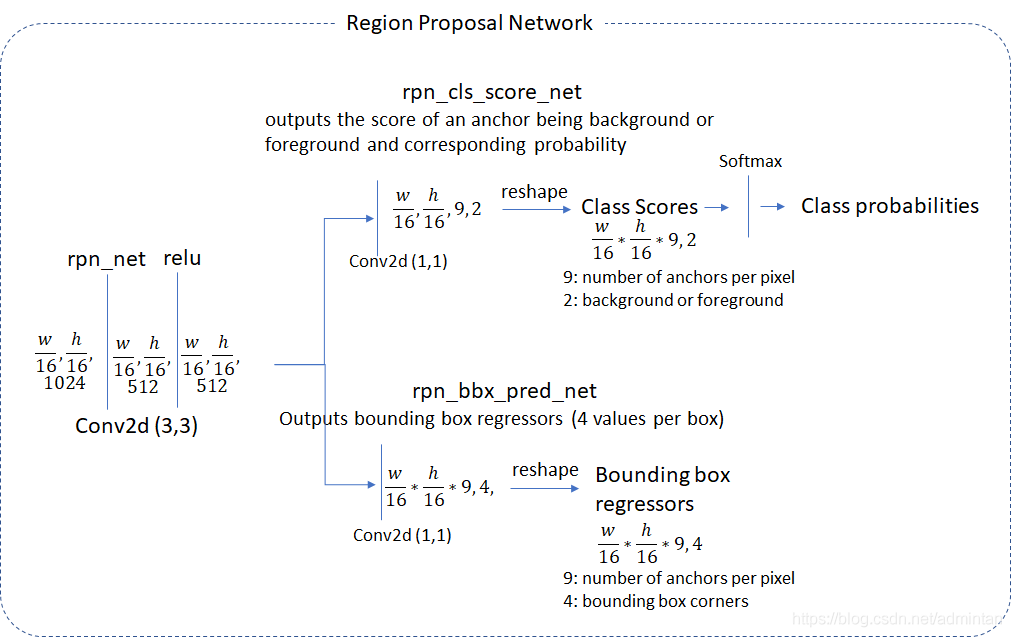
0.整体流程
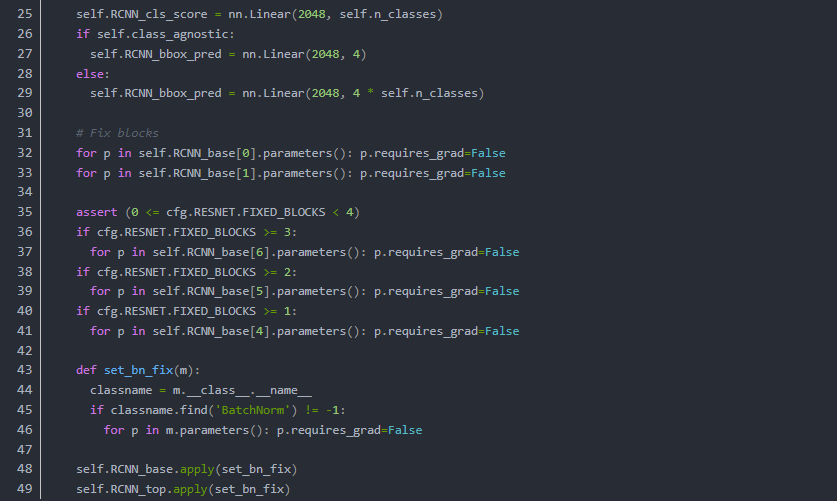
先来看看代码(只是大概的看一下就行):
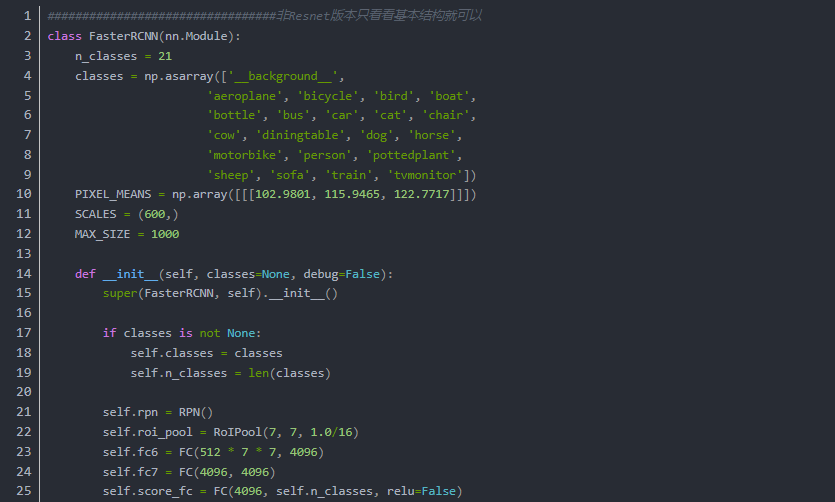
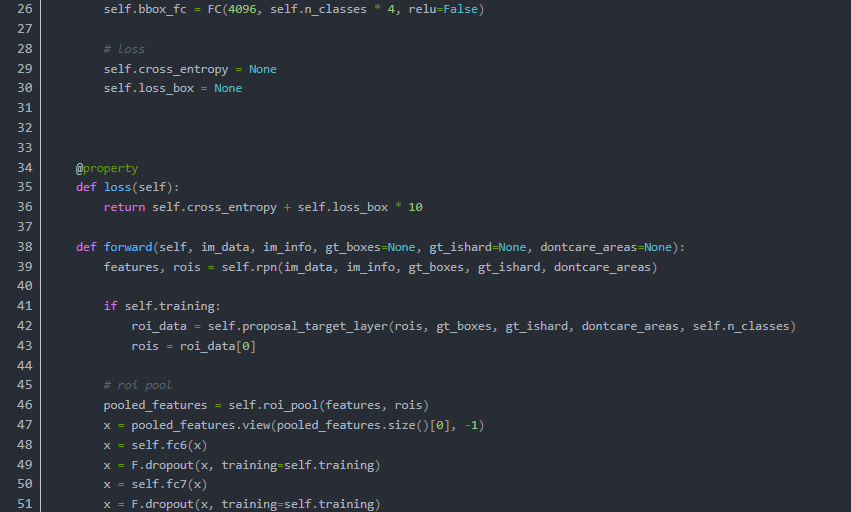
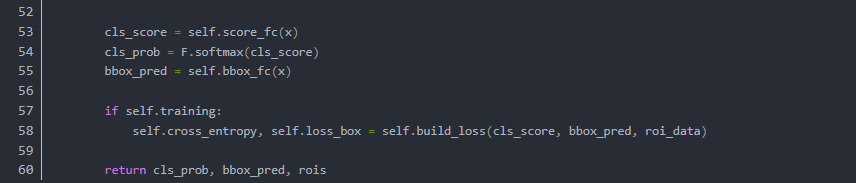
这段代码并不是完整定义,只显示了主要流程,辅助性,功能性的方法全部被省略。
结构也被大大简化
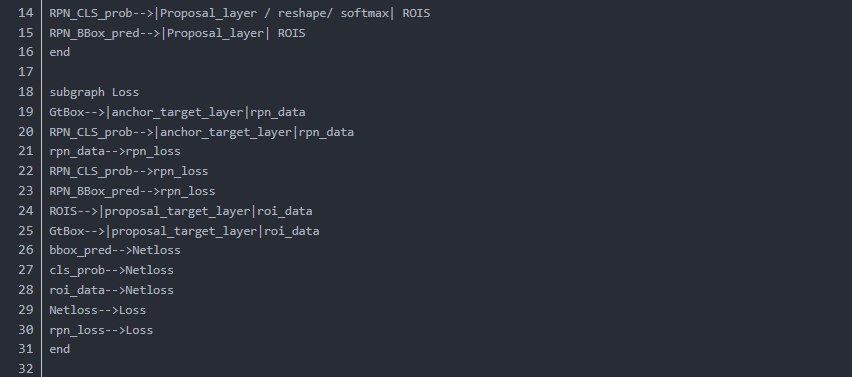
当我们以数据为线索则会产生以下的流程
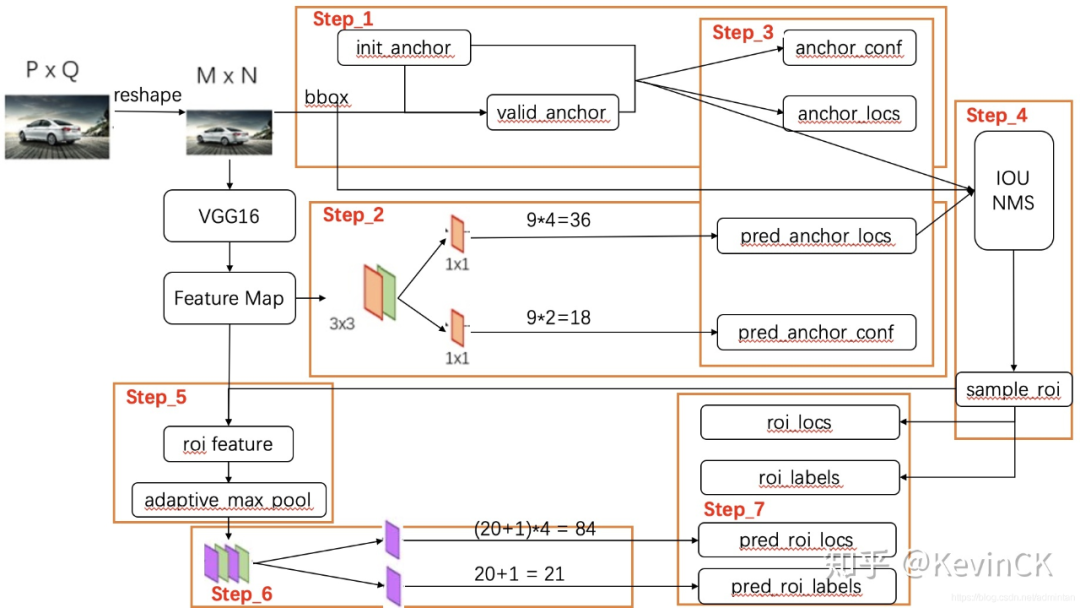
我们在主干网络中可以清晰地看到,向前按照什么样的顺序执行了整个流程(just take a look)
值得注意的是,在以上执行流程中,有些过程需要相应的辅助函数来进行
比如loss的构建,框生成等等,都需要完备的函数库来辅助进行。
以上流程图 ,以及本文的叙述顺序与线索,都是以数据为依托的,明确各个部分数据之间的计算
输入输出信息是非常重要的
初始训练数据包含了:
1.DataLoader
数据加载部分十分自然地,要输入我们的数据集,我们这篇文章使用按最常用的

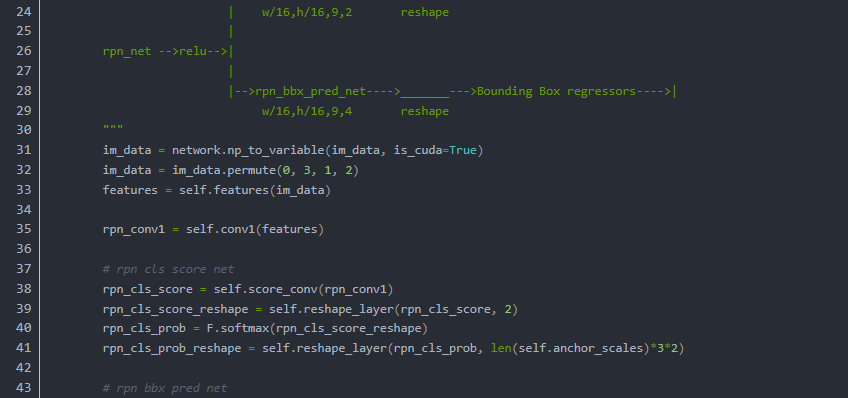
全部部分当然不能展现 但是我们会在开源项目中 演示Voclike数据集,以及自定义数据集如何方便的被加载->开源-快速训练工具(未完成)
在本文中为了关注主旨我们只介绍自定义数据集和VocLike数据集的加载过程
Data2Dataset
数据的原始形式,当然是以图片为主
我们以一张图为例.
使用labelme标注之后

保存之后软件就会自动生成json例如:
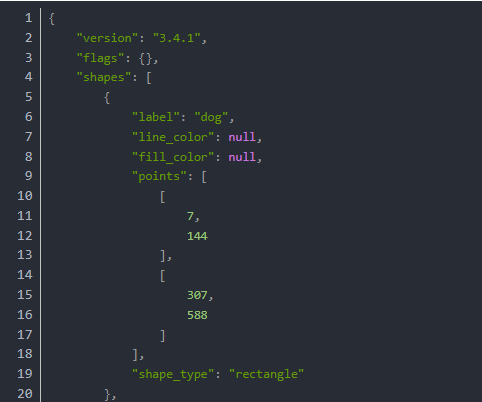
还有labelimg xml标准的数据样本
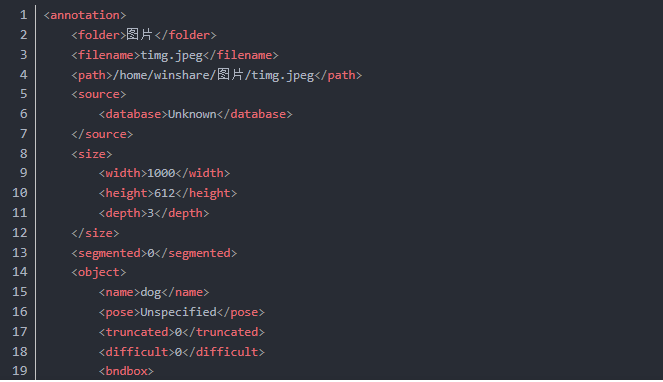
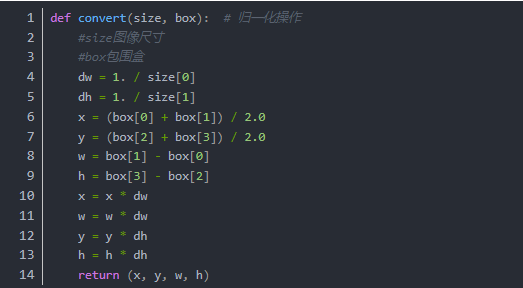
以及yolo标准的bbox

yolo的box值最终会由下面的方法转换为标准的框数据(xywh)
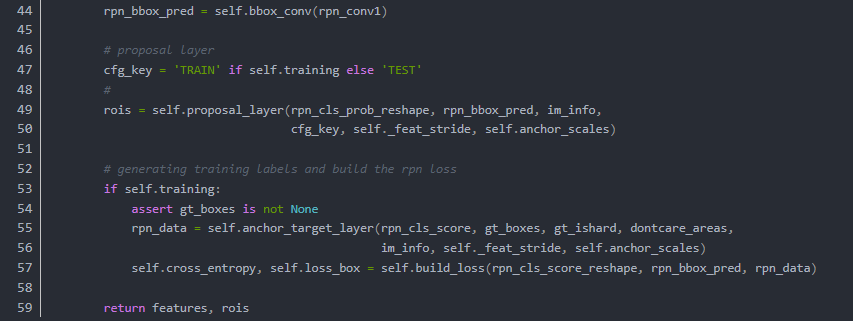
Dataset2Dataloader
很多对Faster RCNN复现的版本中,标准的数据加载流程没有被固定化,所以数据被以各种datalayer ,roidb等等方法包装,Pytorch0.4之后,实质上已经出现了最标准化的数据输入形式
即:

因此我们设getdata()为从一个数据列表的json对象中返回我们需要的指定信息
image
bboxlist
classlist
scale
这其中bboxlist指的是一张图像中所有目标标注框构成的列表,classlist指的是类名,并保证两个列表索引对齐
有了这些设计目标,我们就可以开始构建代码了
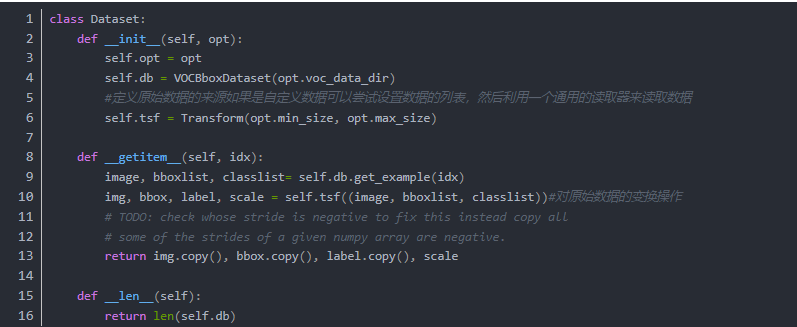
其中变换操作,是为了使得数据转换为张量,以及对数据的平移旋转等数据增强手段。
实质上,Pytorch提供了一系列的Transform下面的代码实际上有很多部分可以省略或者替代
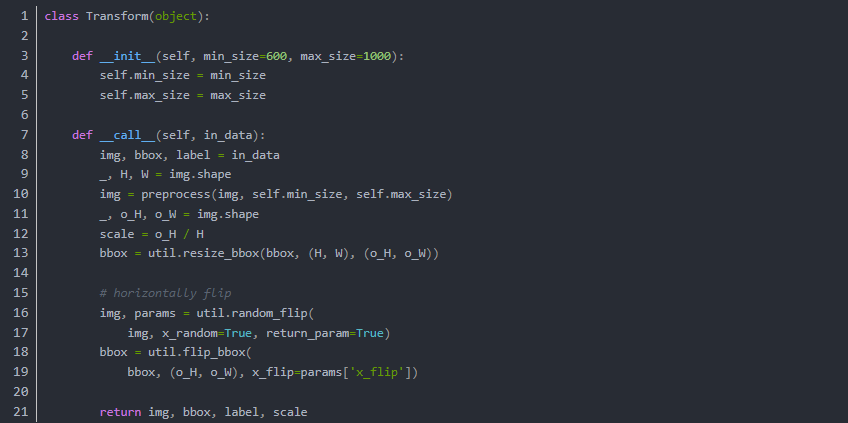
实质上影像的处理依靠torchvision.transforms的写法更加符合一般性pytorch的标准
这里不在多的探讨.
经过Dataset处理和包装之后,其实通过获取方法得到的数据已经可以进入网络训练了,但是实质上还需要最后一层包装。

在pytorch的体系中,数据加载的最终目的使用Dataloader处理dataset对象,以方便的控制Batch,Shuffle等等操作。
建议的简介原始数据被转换为list或者以序号为索引的字典,因为训练流程的大IO量 所以一些索引比较慢的格式会深刻的影响训练速度。
值得注意的一点:在以上的DataLoader中Worker是负责数据加载的多进程数量。torch.multiprocessing是一个本地 multiprocessing 模块的包装. 它注册了自定义的reducers, 并使用共享内存为不同的进程在同一份数据上提供共享的视图. 一旦 tensor/storage 被移动到共享内存 , 将其发送到任何进程不会造成拷贝开销.
此 API 100% 兼容原生模块 - 所以足以将 import multiprocessing 改成 import torch.multiprocessing 使得所有的 tensors 通过队列发送或者使用其它共享机制, 移动到共享内存.
Python 3 支持进程之间共享 CUDA 张量,我们可以使用 spawn 或forkserver 启动此类方法。Python 2 中的 multiprocessing 多进程处理只能使用 fork 创建子进程,并且CUDA运行时不支持多进程处理。
以下代码显示了worker的实际工作样貌
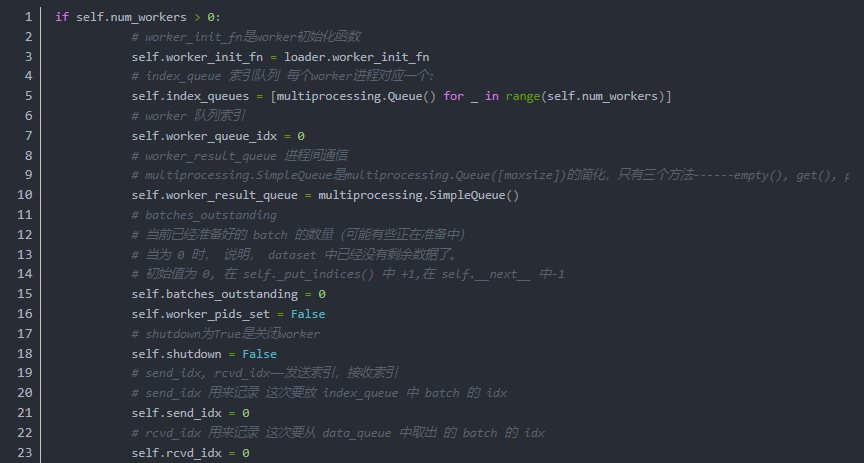
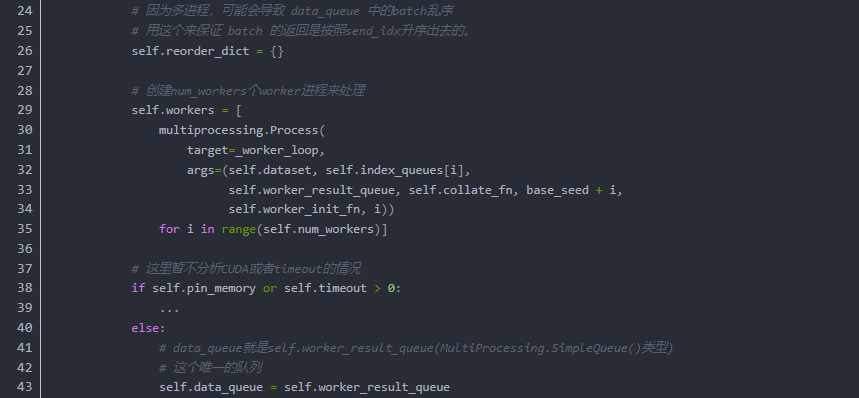
通过数层的封装,我们完成了对训练数据的高速加载,变换,BatchSIze,Shuffle等训练流程所需的操作的构建。
最终在训练流程中通过迭代器就可以获取数据输入网络流程。
最终通过:

这时候的数据就可以直接输入网络了,我们也顺利的进入到了下一个阶段。
2.BackBone - Resnet/VGG
作为两阶段网络的骨干网络,其深度,和性能优劣都深刻的影响着整个网络的性能,其前向推断的速度和准确度都至关重要,VGG作为最原始的骨干网络,各方面的表现都已经落后于新提出的网络。所以我们从Resnet的结构说起
原始VGG网络和Resnet34的对比
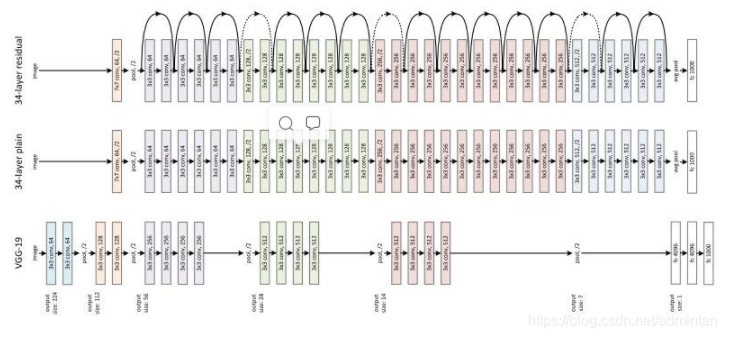
相比VGG的各种问题来说 Resnet提出了新的残差块来对不必要的卷积流程进行跳过,于是网络的加深,高级特征的提取变得更加容易,在此之后,几乎所有的骨干网络更新都是从块结构的优化着手。例如DenseNet就对块结构做出了更多连接模式的探索
简单起见我们从最基础的BackBone-Resnet开始
1,BasicBlock
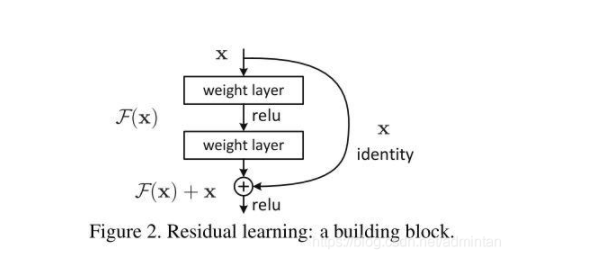
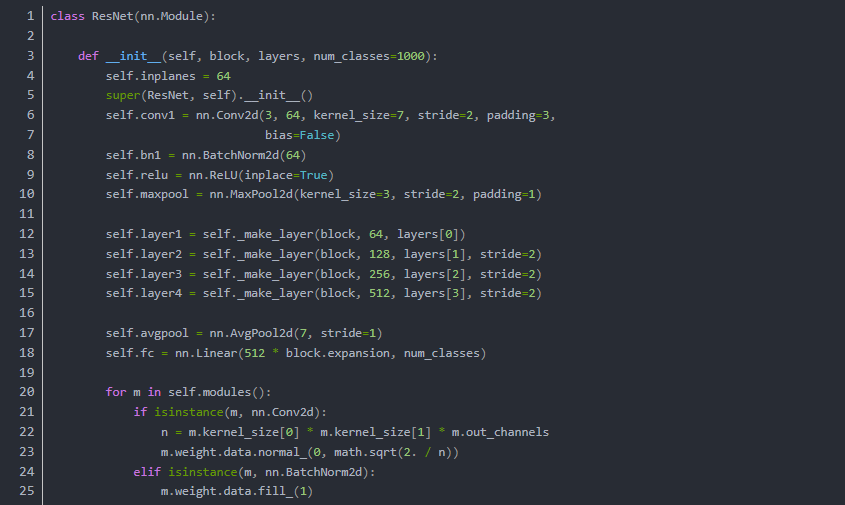
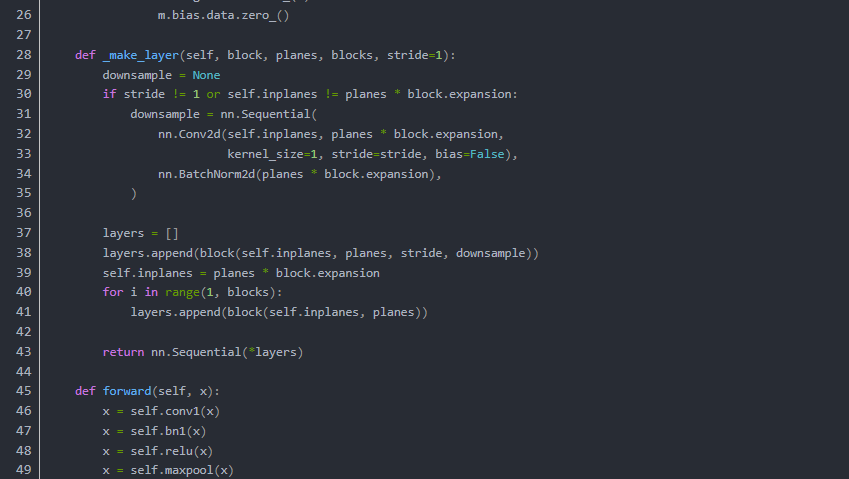
在代码阶段的表现就是ResNet网络的构建代码中包含了跳层结构
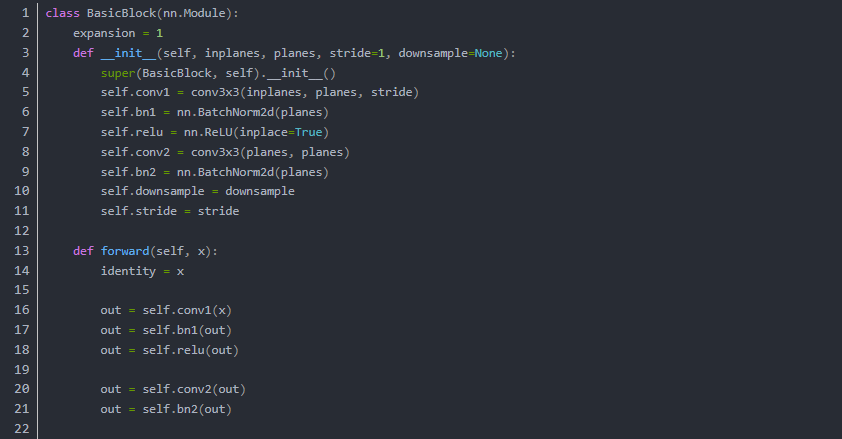



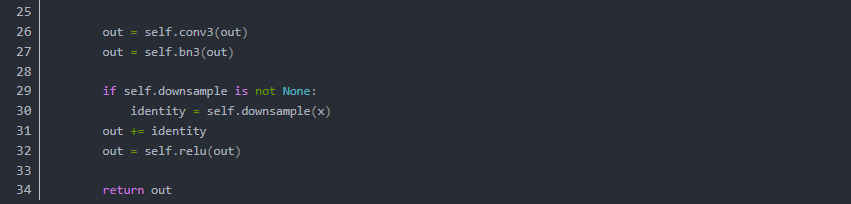
我们在以上网络中看到 跳层的控制结构由 downsample() 控制,也就是说残差块会判断下采样是否为空,如果训练流程执行的不是下采样,那么就进行正常的卷积流程。但是如果训练流程决定执行下采样,就说明残差块中的卷积结果需要加上下采样生成的恒等(identity)。我们从原理上看一下它为什么有效,首先我们来定义残差单元:


表示loss在L层的梯度,小括号里面的是残差梯度,其加法结构相比传统的乘法结构有一个直接的好处就是,可以发现当Loss在很小的时候也因为1的存在不会出现残差梯度的消失,既该层不会像传统网络一样,因为乘法结构导致梯度消失。具体的讨论可以在下面的文章中找到
Identity Mappings in Deep Residual Networks
因为我们只需BackBone作为提取特征的工具, 最终将图片提取为一个合乎其他部分输入的featuremap就可以
我们来看一下,最终的骨干网络怎么构成:
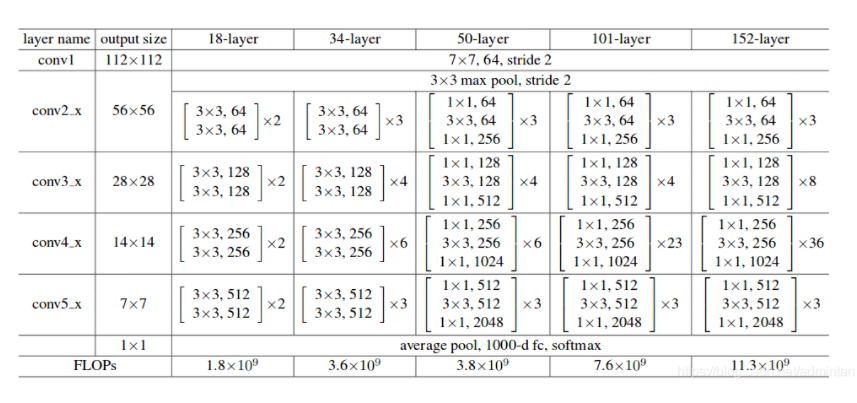

由此生成的标准Resnet肯定是不能为我们直接使用的,因为RPN接口所需要的是FeatureMap不是最后全连接的结果,因此,我们需要Layer3的输出,而不是fc的输出。那么问题来了:
Resnet怎么嫁接到RPN网络呢?
这就要从RPN需要输入的尺寸,和Layer输出的尺寸说起。我们根据图可以看到Resnet101 layer3的输出是1*1,1024
适配工作AnyFeature to RPN
我们以Resnet101为例 来展示一个典型的Resnet 网络作为Faster RCNN的BackBone是怎么一种操作
在原版中,VGG作为BackBone 我们看到的写法是
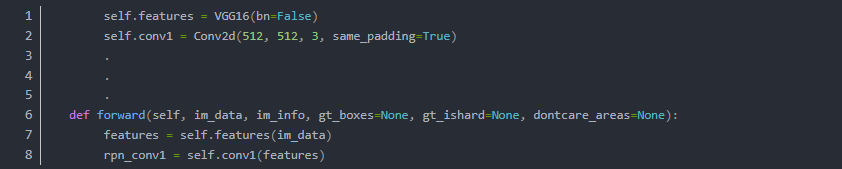
也就是说只要我们把最终把BackBone产生的feature尺寸和Conv1输入的尺寸匹配好就可以了
当我们定义一个Resnet for RPN的类的时候可以参考下面的流程
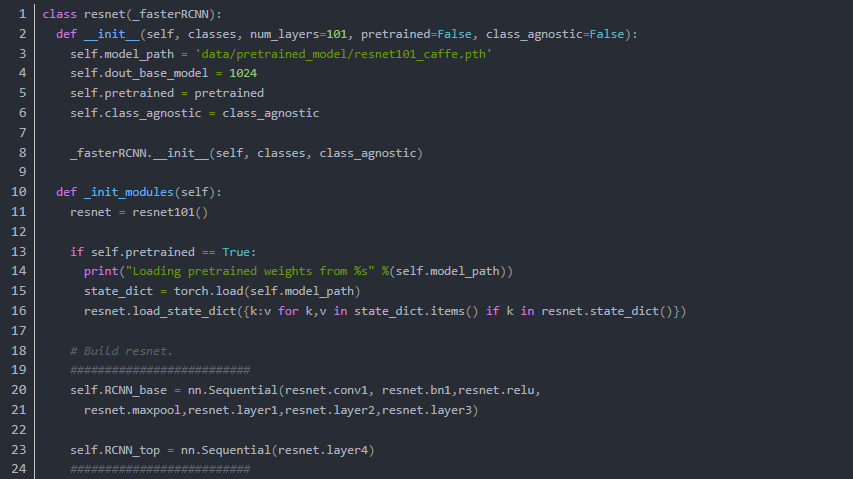
可以看到常见的做法就是把这BackBone分成两部分,以ResNet101为例,这里把构造过程分成了两部分:
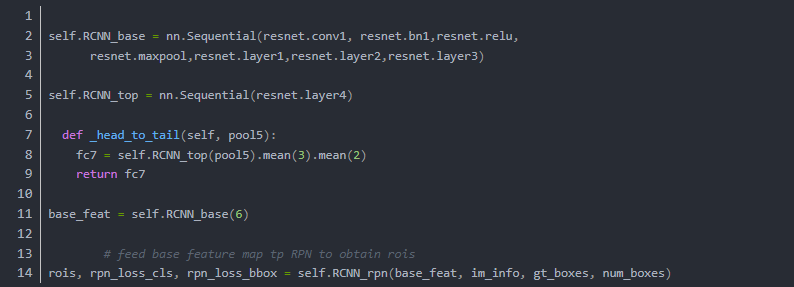
既从最开始到Layer3为一部分,layer4为一部分,在之后的操作中RCNN_Base作为通用的feature输入RPN,而经过ROI Pooling(Align)后的feature进入最后的layer4
RPN
先看原文怎么描述:
RPN以一个任意尺寸的图像作为输入,输出一组矩形region proposal,每个拥有一个该对象的分数。
最终目标是与 FastR-CNN的检测网络共享计算,我们假设两个网络共享一组共同的转换层。
在原始的设计中BackBone被视为RPN的一部分
在我们的实验中,我们研究了Zeiler和Fergus模型(ZF),它具有5个可共享的卷积层和Simonyan和Zisserman模型(VGG),它具有13个可共享的卷积层。
为了生成region proposal,我们对最后一个输出的可分享的卷积层上建立一个小的网络用来滑窗
这个网络完全连接到一个输入卷积特征图的 n*n 空间窗口上。
每个滑窗都被映射到一个更低维的向量中(ZF-256维,VGG512维)
正向量被输入到两个并行的全连接层中
框回归分支
类回归分支
在这篇文章中我们令n=3,实际的感受野在输入图像上非常大,(171 在ZF上 228 在VGG上)。
这个结构天然的以nn卷积层实现并后接两个11的卷积层,ReLUs 被应用在n*n卷积层的输出上。

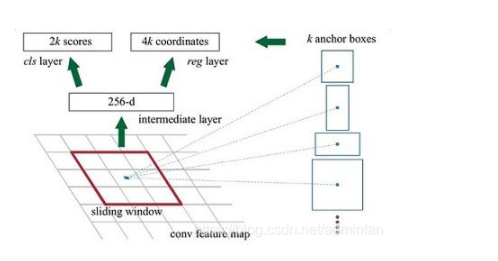
从原文的途中我们可以体会一下整个流程。输入一张image 输出一组regions proposal
当然其中有些流程需要再解释
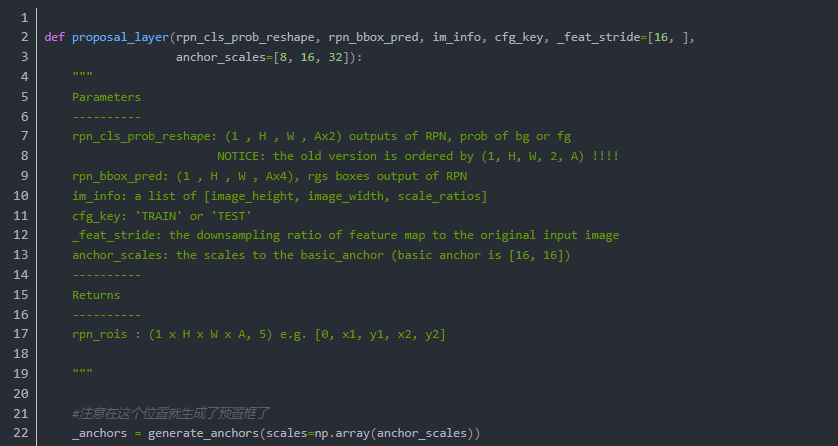
Anchor&Proposal layer
执行流程:
for each (H, W) location i
在i位置生成A个anchor box
把预测的包围盒变量应用于每个位置的每个锚点
使用预测盒剪切图片
去掉宽和长小于阈值的包围盒
从高到低对所有proposal,score 序列排序
选择top N 应用 非极大值抑制 使用0.7做阈值
按照Batch返回TopN
既:
0.输入之前RPN两条支路中所生成的
rpn_cls_prob_reshape,
(1 , H , W , Ax2)
rpn_bbox_pred,
(1 , H , W , Ax4)
以及原始图像的信息
[image_height, image_width, scale_ratios]
1.基于feature map 尺寸,按照指定的长宽大小组合生成所有pixel位置的 anchor(shift_base anchors)
2.对这些anchor做剪枝(clip,transfrom,filter,NMS),TopN备选
3.把剪枝后的anchor包装为proposal
Generate Anchors
在上一步的proposal layer中我们会发现,anchor的生成过程处于region proposal流程的最前端,那generate到底干了些什么呢?首先从BackBone输入影像,到输出featuremap 由于在取卷积的过程中的一些非padding的操作使得数据层尺寸越来越小,典型的800^2经过VGG下采样后尺寸为
50^2,这个阶段我们先用简单的代码来研究这其中的原理
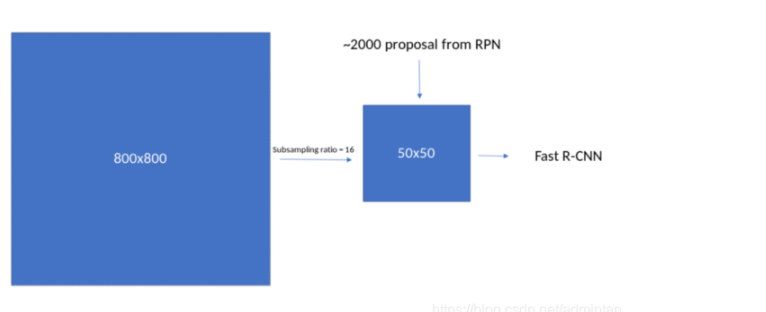
我们使用
锚点缩放参数8,16,32
长宽比0.5,1,2
下采样倍数为16
现在每个featuremap上的像素都映射了原图1616像素的区域,如上图所示
1.我们首先需要生成在这个1616像素的顶端生成锚点框,然后沿着xy轴去生成所有锚点框
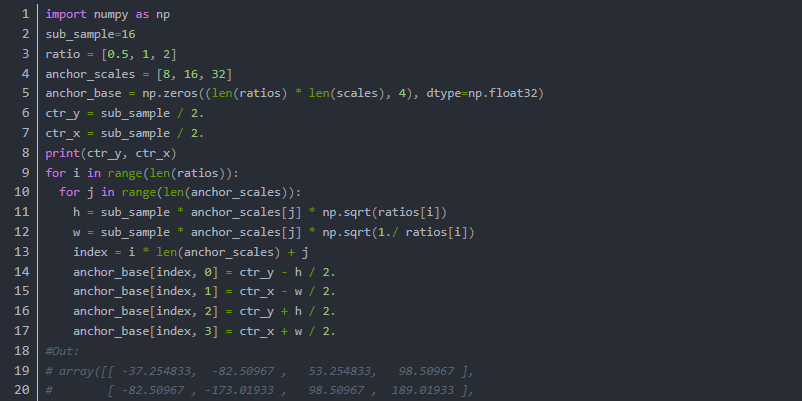
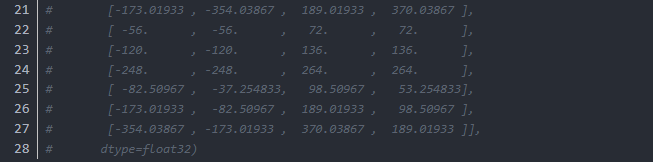
以上的输出为featuremap上第一个像素位置的anchor,我们必须依照这个流程生成所有像素位置上的anchor:
2.在feature map上的每个像素位置,我们需要生成9个锚点框,既每个框由(‘y1’, ‘x1’, ‘y2’, ‘x2’)构成因此总共有95050=22500个框,因此最后,一张图的anchor数据尺寸应该是(22500,4)
3.在22500个框中最后有相当部分的框实质上超出了图像的边界,因此我们根据最直接的边界计算就能筛除,最终22500个框剩下17500个有效框(17500,4)
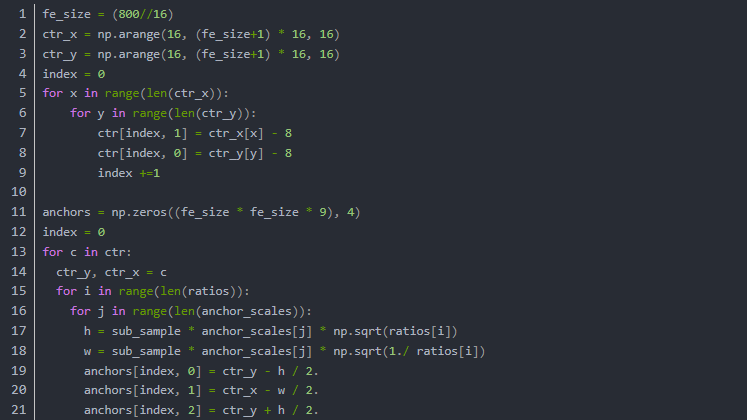
现在我们已经从原理上把所有框都生成了。为了工程调用起见我们用下面的方法包装
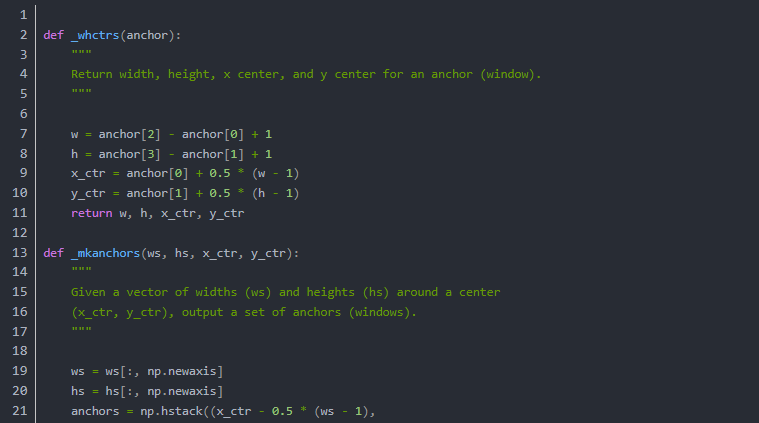
在实际工程执行的过程中,for循环的操作很慢.因此其实是都以base anchor做shift操作 这部分工作在Region Proposal Layer中可以看到,经过shift产生的所有框就是我们通过简化代码所输出的[22500, 4]得anchors
NMS(Non-Max Suppression)
NMS算法一般是为了去掉模型预测后的多余框,其一般设有一个nms_threshold=0.5,具体的实现思路如下:
选取这类box中scores最大的哪一个,记为box_best,并保留它
计算box_best与其余的box的IOU
如果其IOU>0.5了,那么就舍弃这个box(由于可能这两个box表示同一目标,所以保留分数高的哪一个)
从最后剩余的boxes中,再找出最大scores的哪一个,如此循环往复
我们先用最常规的代码去实现nms:
先假设有6个输出的矩形框(即proposal_clip_box),根据分类器类别分类概率做排序,从小到大分别属于车辆的概率(scores)分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度(IOU)超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
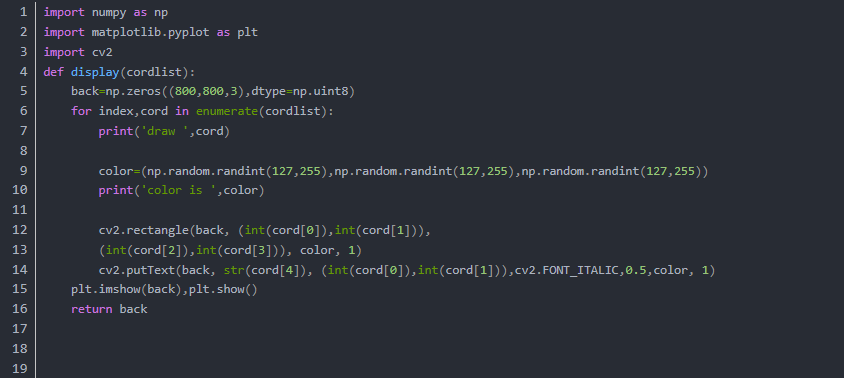
显示NMS输入
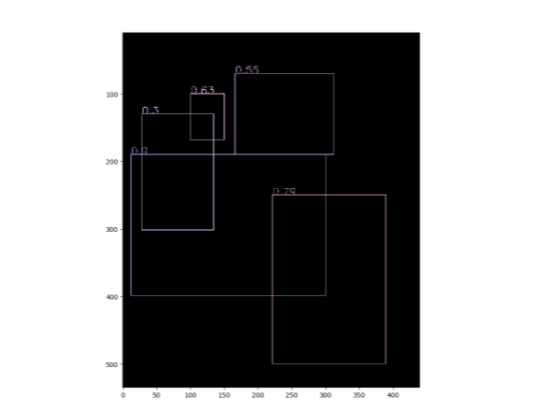
显示NMS输出
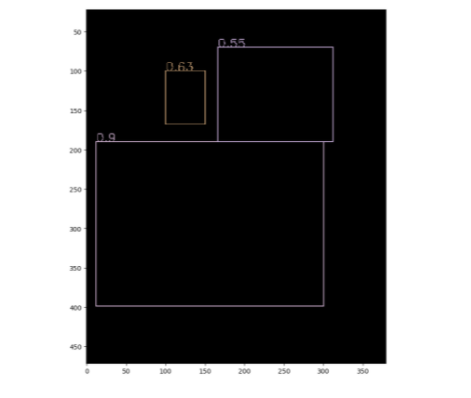
有了原理上的了解,我们把整个流程利用torch重构一下
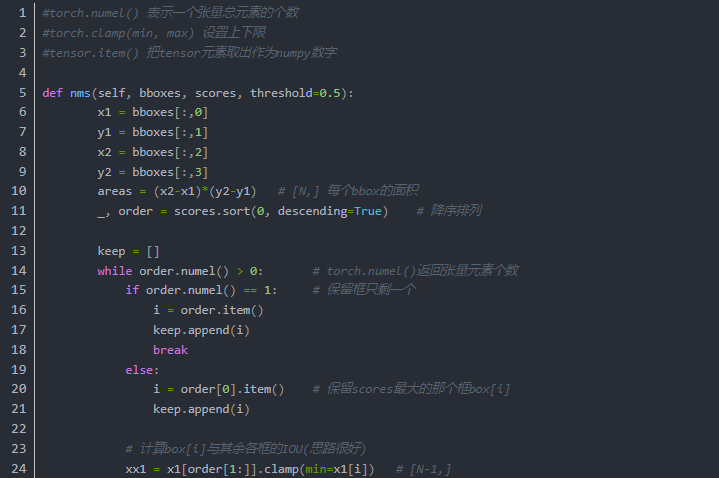
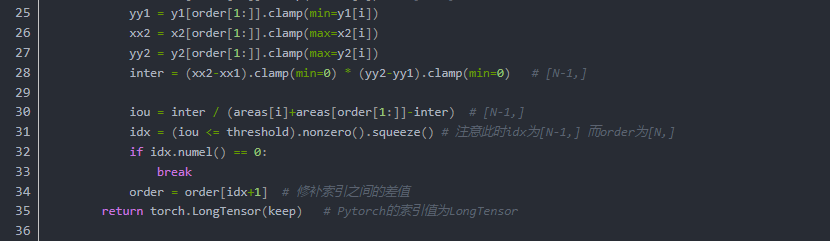
经过NMS处理的Proposal,选择TopN个之后
即可被按照Batch返回,结束了整个Region Proposal Layer的过程
Layer返回的Region Proposal以及之前的feature来说 我们已经拿到了RPN网络需要返回的所有信息。可以开始下一步了。
RPN Loss Function
RPN设计完成之后我们来看看Loss函数
RPN Loss计算之前我们先看,原文对于anchor标定的描述
For training RPNs, we assign a binary class label (of being an object or not) to each anchor.
We assign a positive label to two kinds of anchors:
(i) the anchor/ anchors with the highest Intersection-over-Union (IOU) overlap with a ground-truth box, or
(ii) an anchor that has an IOU overlap higher than 0.7 with any ground-truth box.
训练RPN网络时,对于每个锚点我们定义了一个二分类标签(是该物体或不是)。
以下两种情况我们视锚点为了一个正样本标签时:

Note that a single ground-truth box may assign positive labels to multiple anchors.
Usually the second condition is sufficient to determine the positive samples;
单个正样本的标注框或许被被多个锚点所共享。通常,第二个情况足够可以完成正样本采样。
but we still adopt the first condition for the reason that in some rare cases the
second condition may find no positive sample.
但是我们仍然需要第一种情况,以避免某些少见的情况下,第二种情况下或许会没有正样本采样
We assign a negative label to a non-positive anchor if its IOU ratio is lower than 0.3 for all ground-truth boxes. Anchors that are neither positive nor negative do not contribute to the training objective.
我们给一个非正样本锚点定义负样本标签的时候。如果IOU对所有的标注矩形小于0.3。该锚点将会变成无意义的锚点被过滤掉不会参与训练。
在上一节的定义过程中我们会发现
With these definitions, we minimize an objective function following the multi-task loss in Fast R-CNN
有了这些定义,我们最小化了Fast R-CNN中的多任务损失目标函数。
Our loss function for an image is defined as:
定义为:

通过该图 我们能从表述和图示里,看出RPN总体loss分为

则在RPN类中可定义为

通过以上的loss构造完成了两部分rpn_cross_entropy, rpn_loss_box这两个部分共同构成了RPN_Loss
当能够正常反向传播之后我们应当能够认识到,训练流程里RPN的阶段就彻底结束了。
RPN生成的feature & region proposals
ROI-Pooling
为什么需要ROI Pooling??
它和我们遇到的MaxPooling,MeanPooling,Sptial Pyramaid Pooling有什么不同?
目标检测2 stage typical architecture 通常可以分为两个阶段:
(1)region proposal:给定一张输入image找出objects可能存在的所有位置。这一阶段的输出应该是一系列object可能位置的bounding box。(regions or ROIs)
(2)final classification:确定上一阶段的每个region proposal是否属于目标类别或者背景。
也就是proposal到refine的整体流程
ROI Pooling的目的就是使用MaxPooling针对不定尺寸的输入,产生指定尺寸的feature map。
这个architecture存在的一些问题是:
1,产生大量的region proposals 会导致性能问题,实时性能会大大降低
2,在处理速度方面是suboptimal。
3,无法做到端到端的训练
由于这个步骤没有得到大多数神经网络库的支持,所以需要实现足够快的ROI Pooling操作,这就需要使用C来执行,在GPU条件下需要CUDA来执行
ROI pooling具体操作如下:
(1)根据输入image,将ROI映射到feature map对应位置;
(2)将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同);
(3)对每个sections进行max pooling操作;
这样我们就可以从不同大小的方框得到固定大小的相应 的feature maps。值得一提的是,输出的feature maps的大小不取决于ROI和卷积feature maps大小。ROI pooling 最大的好处就在于极大地提高了处理速度。
如下图所示:
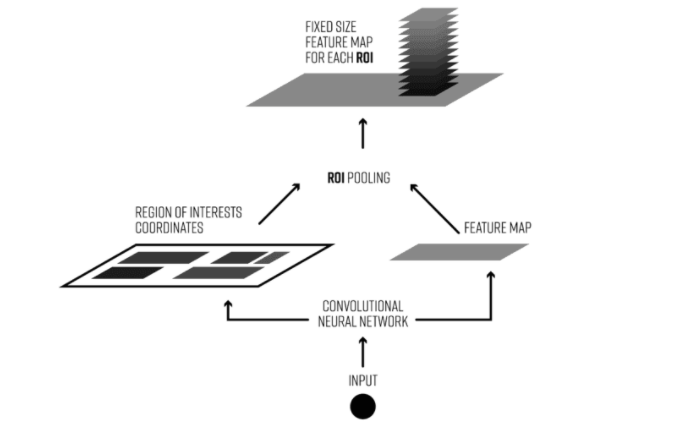
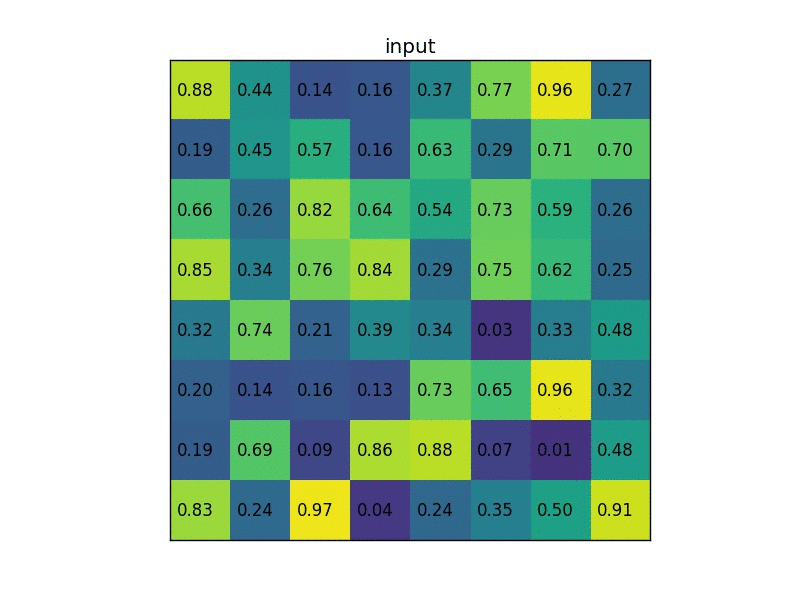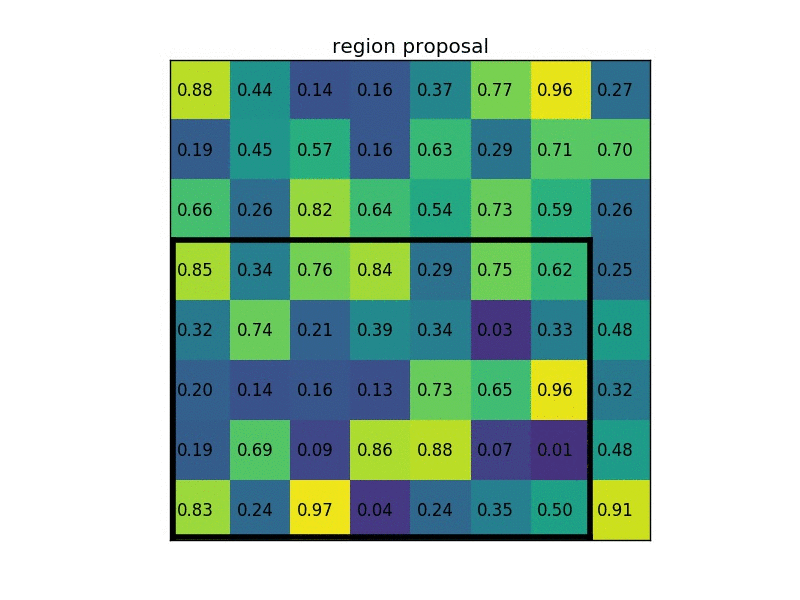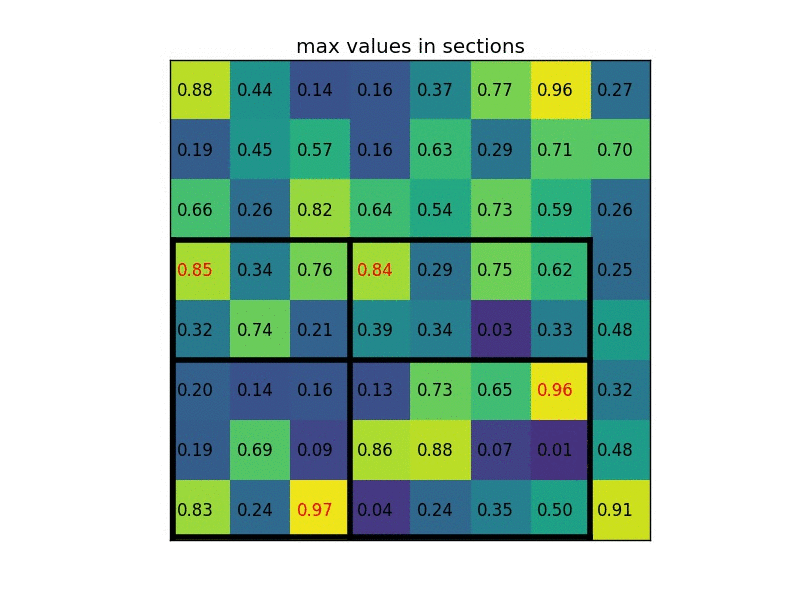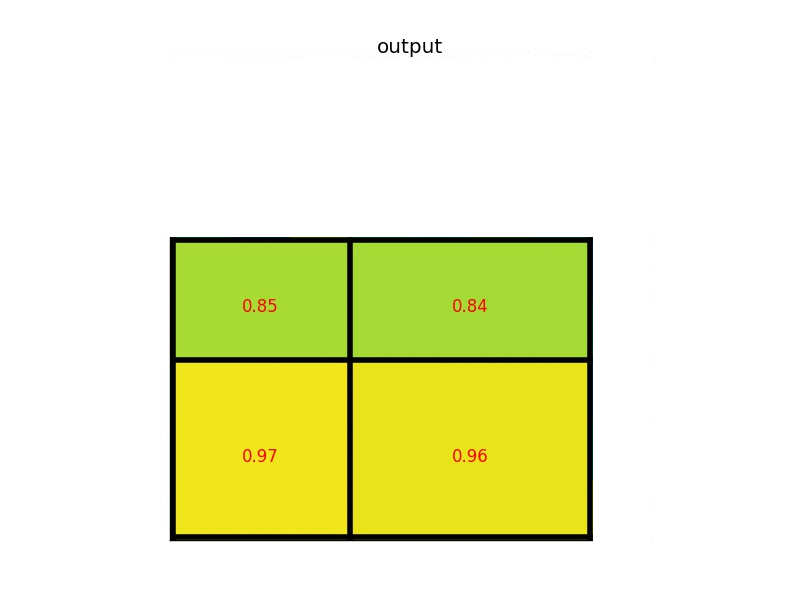
以下为一个 ROI pooling 的例子
考虑一个8×8大小的feature map,一个ROI,以及输出大小为2×2.
(1)输入的固定大小的 feature map
(2)region proposal 投影之后位置(左上角,右下角坐标):(0,3),(7,8)。
(3)将其划分为(2×2)个sections(因为输出大小为2×2),我们可以得到:
(4)对每个section做max pooling,可以得到:
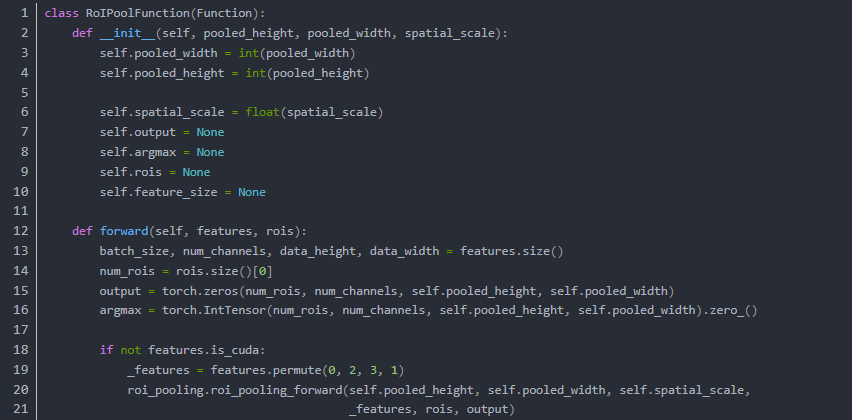
可以看到ROI Pooling的 Python 部分其实没有什么计算的部分,其计算部分都被隐藏在了CUDA-C以及C中,以保证其高效。
我们对比一下C和CUDA的代码(forward)
CUDA:
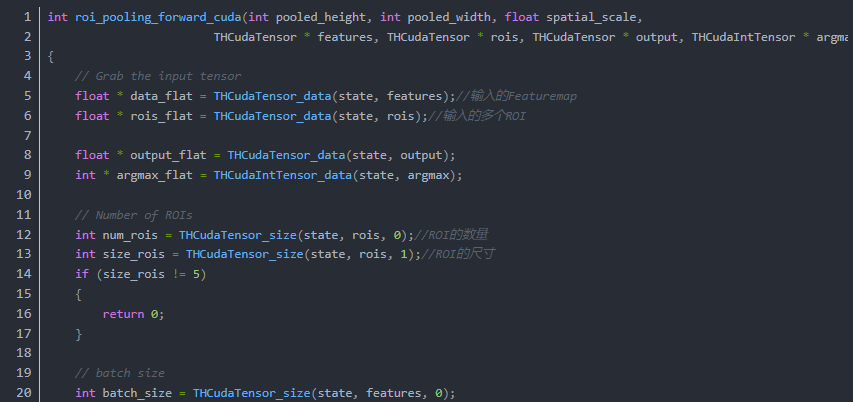
在这段代码中所有数据被整合进了ROIPoolForwardLauncher中,然后执行了
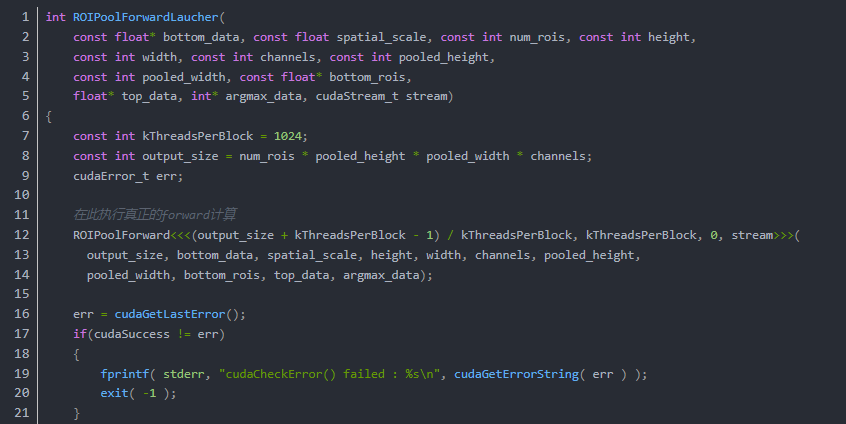
真正的ROI Pooling Forward Kernal 计算:
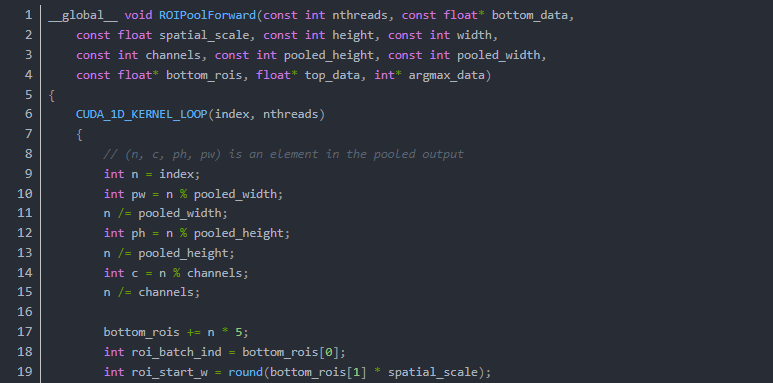
有了CUDA的加速RoiPooling的执行过程就变得快了很多,所以突破了端到端的ROI-Pooling的效率问题。Faster RCNN的效率才破除了最后一个障碍
但是实质上,以上过程里展现的信息,在工程上是没有必要的,为任何一个API编写CUDA扩展的难度都是非常大的甚至1%
Regression
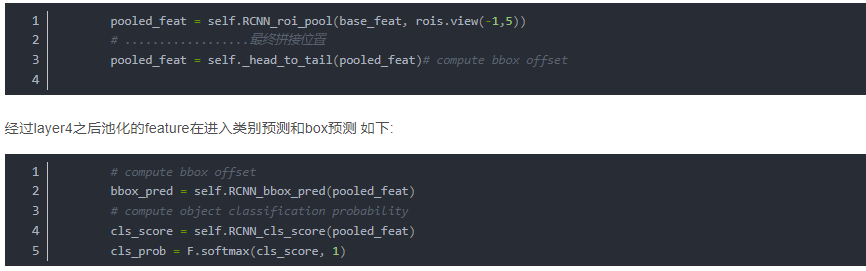
在最之前的Faster R-CNN的代码中我们看到了在ROI Pooling之后的过程如下(省略了不必要的部分)
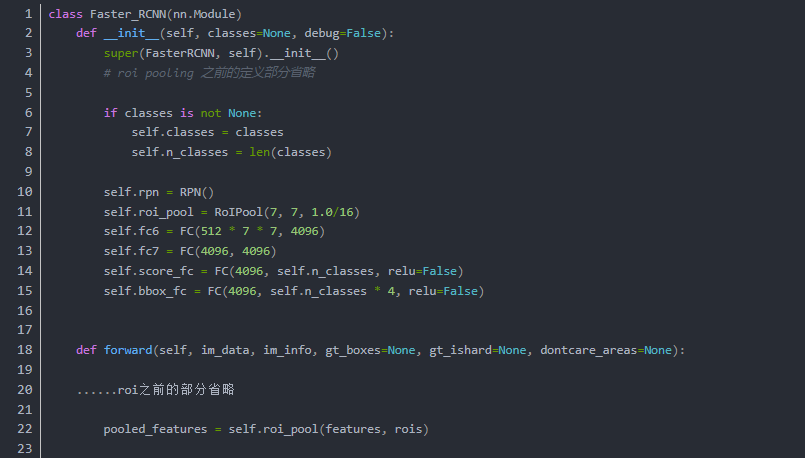
到达了这一步,最终我们实现了整个网络从输入图片数据,到输出预测框以及类别信息的整个流程
Faster RCNN Loss
我们有了两个网络,即Faster RCNN以及RPN,他们也有两个输出 (回归部分以及分类部分),而Faster RCNN的Loss可以定义为:
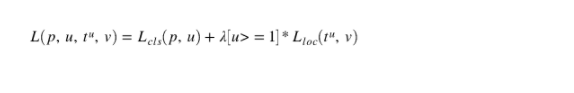
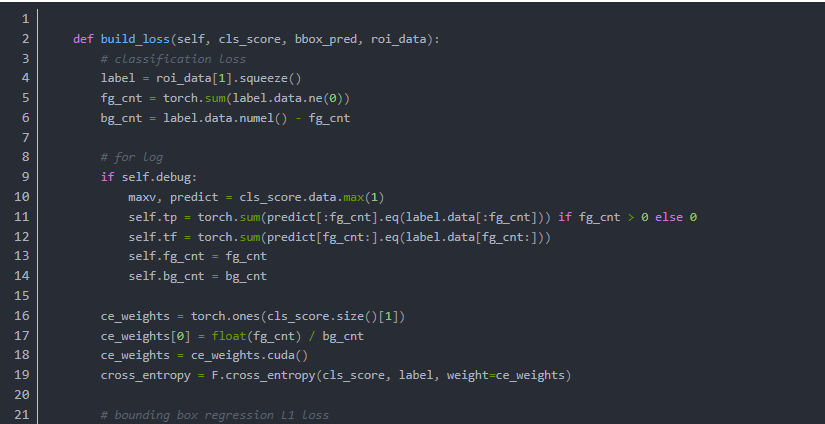
原文地址
https://blog.csdn.net/admintan/article/details/91366551
完整代码地址
https://github.com/jwyang/faster-rcnn.pytorch
机器学习算法AI大数据技术
搜索公众号添加: datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx















 1108
1108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









