






内存屏障
编译乱序
异步场景中,经常使用多线程一起处理任务并且通过一个共享变量进行状态的共享,如下,function2在请求data数据时通过status判断数据是否就绪,function1准备数据完成后修改status。
bool status = false;
char data[50] = "Hello";
void function1() {
strcpy(data, "World");
status = true;
}
void function2() {
while (status) {
printf("%s\n", data);
}
}
编译会对代码进行优化,编译出更加高效的代码,其中可能会将代码的顺序打乱(能确保单线程情况下功能不会受影响),上述代码中,对于funcction1来说编译器认为data和status是没有依赖关系,依赖关系在function2中体现,只有程序员知道依赖关系,所以编译器可能会打乱顺序成如下
void function1() {
status = true;
strcpy(data, "World");
}
当执行status = true;后function2立马进入循环对data进行访问,此时function1并没有对data进行赋值,printf将打印一个非预期的data。
所以编译器通常会提供编译器屏障(又叫优化屏障)。Linux内核提供了函数barrier(),用于让编译器保证其之前的内存访问先于其之后的内存访问完成。避免指令重排。通常不同语言的volatile关键字也有类似的效果。
ps: 单个CPU也有执行乱序的情况但是不会出现问题,一条指令的执行过程可分解为若干阶段,像流水线一样按顺序执行所以叫指令流水,包括取指(IF)、译码/读寄存器(ID)、执行/计算地址(EX)、访存(MEN)、写回(WB)等。当一个指令在取指(IF)阶段时,其他阶段的处理单元都是空闲的,所以为了进一步利用CPU资源,两条无关的指令CPU可能会同时派发到不同的执行单元执行,比如指令1在ID阶段,指令2在IF阶段执行,相当于多个指令并行执行。但在单个CPU上,指令能通过指令队列顺序获取并执行,结果利用队列顺序返回寄存器堆,这使得程序执行时所有的内存访问操作看起来像是按程序代码编写的顺序执行的。所以不会出问题。
Cache和cache一致性协议
CPU需要将一个变量(假设地址是A)加1,一般分为以下3个步骤:
-
CPU 从主存中读取地址A的数据到内部通用寄存器 x1(arm通用寄存器x0,x1,…x30,wzr)(load)。
-
通用寄存器 x1 加1。
-
CPU 将通用寄存器 x1 的值写入主存(store)。
CPU register的访问速度一般小于1ns,主存的访问速度一般是65ns左右,在上述计算中CPU需要白白等待load/store100ns,导致CPU算力没有被充分使用。而且将主内存速度提高到register一样的访问速度的成本是昂贵不可接受的。因为程序运行具有局部性,即刚刚访问的内存之后会再次访问的概率很大,所以使用缓存(Cache)的思路提高内存的访问速度。通常会设计多级缓存,L1、L2、L3,访问速度依次递减,同时容量依次递增。在多核CPU中,通常L1是每个核独占的,L2是每个相同NUMA节点下共享的,L3是所有核共享的。
有了Cache后访问load/store时先访问cache,cache上没有再去将主存内容加载到cache中再访问。
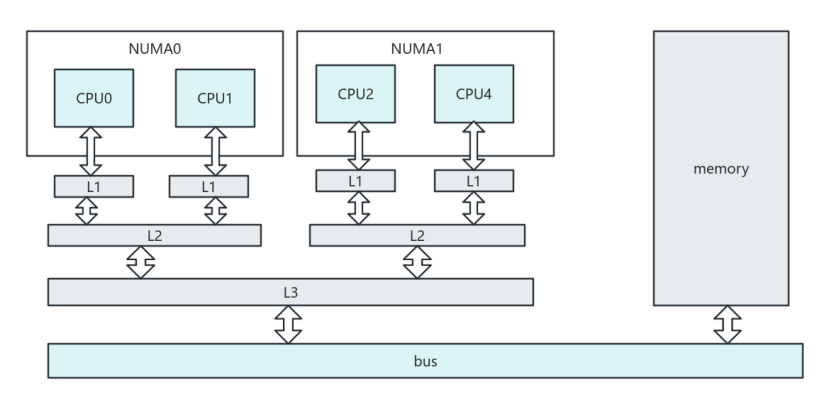
ps: 类似分页管理机制,cache也是分块管理,每次访问只能固定大小的内存块,称为cache line size,一般cache line的大小是4-128 Byts。另外容量小的cache映射到容量大的主内存方法,有全相联映射、直接映射、组相联映射等多种。这些都是软件无感知的。
有了cache,一份数据分别在cache和主内存中都有一份,cache和主存两份数据如何保证一致性同时又能得到很高的性能?出现多种一致性协议
对于单核CPU,只有一个cache,通常当CPU读数据时,如果cache命中就直接返回,不命中就返回从主内存中读取到cache中之后再读cache返回。有两种更新策略,写直通即每次写都直接刷新到主内存,回写即每次只写cache上,当cache被换出时回写到主内存中。
多核CPU,每个核都有单独的cache,相对于单核CPU还需要考虑多个核的私有cache的一致性问题,主要有2种策略:基于总线监听的一致性策略 和 基于目录的一致性策略
基于总线监听的一致性策略,也叫总线嗅探(Bus Snooping),原理简述如下:
1、当有一个核修改了Cache中的值,会通过总线把这个事件广播给其他所有核;
2、每个核都会去监听总线中的数据广播,并检测自己是否有相同数据的副本在本核的Cache中;如果有副本,就执行相应操作来确保多核的缓存一致性
基于目录的一致性策略会维护一个表格,叫做目录(directory-based),保存在哪些核上有副本及其对应的状态等信息;当CPU执行写操作时,不会再向所有核的Cache进行广播,而是是通过此目录来跟踪所有缓存中数据副本的状态,仅将写信息发送到指定的数据副本中;这样相比总线嗅探节省大量总线流量。
它又分为SI,MSI,MESI策略
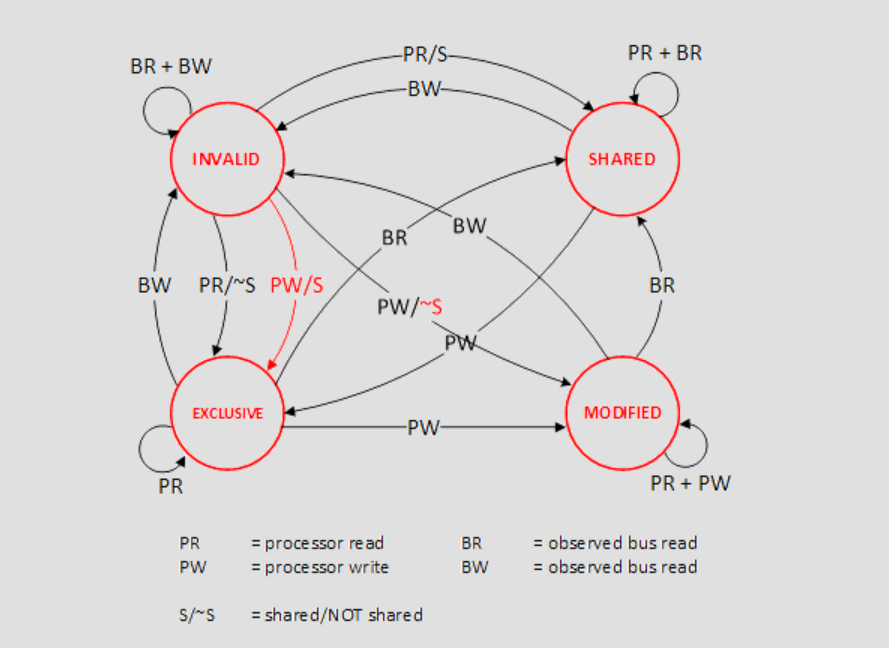
MESI 协议将数据表示成四个状态,分别是:
Modified,已修改,数据已经被更新过,但是还没有写到内存里
Exclusive,独占,数据只存储在一个 CPU 核心的 Cache 里,而其他 CPU 核心的 Cache 没有该数据
Shared,共享,数据在多个 CPU 核心的 Cache 里都有
Invalidated,已失效,数据已经失效了,不可以读取该状态的数据
对不同状态的数据进行load/store会触发状态转移,同时触发对应同步机制等
https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESIHelp.htm
如果严格按照MESI协议,某核在写入Invalid状态cache时,需要向其他核广播RFO获得独占权,其它核收到消息后,使他们对应的缓存副本失效,并返回 Invalid acknowledgement 消息,直到这个核收到消息才能修改缓存,期间当前核只能空等待,性能变差。所以通过 Store Buffer写缓冲区和 Invalidate Queue失效队列机制来进一步优化性能。
Store Buffer机制是当前核需要修改cache时将相关信息写入Store Buffer中,之后这个核就可以直接返回继续做其他工作无需等待正真写入成功。Store Buffer自动向其他核广播RFO获得独占权,等收到 ACK 后再自动写入cache中。性能提高了但是会引入延迟问题
Invalidate Queue机制则是当一个核收到上述RFO请求时,可能正在执行其他事情,不能打断,如果一直等会耽误RFO请求,所以就先将相关信息保存到Invalidate Queue后直接回复 ACK,之后有空再将做cache状态变更,性能提高了但是引入延迟问题,当Invalidate Queue未处理时可能读到一个旧数据。
如上诉问题,如果编译乱序和指令执行乱序都不存在,依然可能存在不一致问题,比如线程1执行了function1写了data,线程2执行function2依然没读到最新的值,同样可能会出现printf将打印一个非预期的data问题。
内存屏障
上述问题通常可以通过引入内存屏障解决,如下有了内存屏障可以保证变量对多个线程可见。
void function1() {
status = true;
smp_mb(); //内存屏障
strcpy(data, "World");
}
内存屏障通常可以细分为写屏障、读屏障和全屏障,对于MESI协议的一致性问题,写屏障,保证 store buffer的数据写到cache中,读屏障,保证invalidate queue的请求都已经被处理。通常不同语言的volatile关键字也有内存屏障的效果。















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









