






2009 英特尔® 线程挑战赛—背包问题
问题描述
在你为旅行准备行李时,重要的是你要注意不要在行李箱里放过多的东西,否则你可能会为因行李过重而付出额外的代价。这可能是来自航空公司的额外行李费用,或由于携带背包引起的肌肉酸痛。而且,当你装包时,控制总重量并不是你的唯一标准,你需要为你的旅行放入更有价值的物品。比如当你到澳大利亚度假时,如果你在包里塞满了羽毛,这不会有任何意义。背包问题的目的是要找到物品的最优选择,从而使这些物品的总价值最大,同时使总重量控制在限制范围内。
问题:写一个线程代码来找到能够形成最大总价值的物品清单,同时这些物品的总重量能够满足一个背包(容器)的限定容量。每个物品将有一个相关属性,包括容量(用重量表示)和价值(价格)。背包容量和要使用的物品清单会包含在命令行指定的输入文件内。装入的物品清单,装入的物品数量,总重量以及最终总价值将打印到一个输出文件:packinglist.out。
输入格式:第一行的文本文件将包含三个数:一个实数和两个整数。实数表示背包的容量,第一个整数表示每个可用物品的最大数目,这就是说,即使每个物品会在文件中列出一次,可能会有多个相同物品用来装包。第二个整数表示文件中物品的数目。随后的每一行由三项数据组成:表示物品名的唯一的13个字符长的字符串;表示物品重量的一个实数;以及表示物品价值的一个实数。在输入中不存在重量和价值相同的两个物品。
输出格式:使用易懂的一些格式。列出装入包中的每个物品以及这些物品的数量。同时需要包括所有装入包中物品的总重量和总价值。
第一个输入文件样例:
15.0 4 5
XXL blue Ox 2.0 2.00
gray mouse 1.0 2.00
big green box 12.0 4.00
yellow daisy 4.0 10.00
salmon mousse 1.0 1.00
第一个输出文件样例:
The items to fit into the 15.0 knapsack are:
3 yellow daisy
3 gray mouse
Total capacity used: 15.00
Total value: 36.00
第二个输入文件样例:
15.0 1 6
XXL blue Ox 2.0 2.00
gray mouse 1.0 2.00
big green box 12.0 4.00
yellow daisy 4.0 10.00
salmon mousse 1.0 1.00
9780596521530 1.54 44.99
第二个输出文件样例:
The items to fit into the 15.0 knapsack are:
1 gray mouse
1 9780596521530
1 yellow daisy
1 salmon mousse
1 XXL blue Ox
Total capacity used: 9.54
Total value: 59.99
计时:总执行时间将用于计分。如果没有找到最优方案,将会减分。
串行算法
本题属于多重背包问题,多重背包可以转化为01背包进行求解。将物品分组1, 2, 4, 8..... 2^(k - 1), nCount - 2^(k + 1) + 1。由这些组可以组合成[0-nCount]的任意值。将减少转化后的物品数量。
01背包问题可以用动态规划和分支限界两种算法进行求解,当背包较大时动态规划并不适用,而且内存访问过于频繁,分支限界算法利用分支可能组合的最大价值与当前已经找到的最大价值的比较结果进行剪枝,如果物品的价值和重量比值都差异很小的时候分支限界算法可能会有较长的执行时间。
并行算法
动态规划是数据高度依赖的算法,所以并行相当的困难,根据测试的结果看线程同步的开销甚至让并行算法比串行算法还要慢。
分支限界算法的并行也存在类似的问题,最终采取了多个线程分别计算不同的分支从而达到并行加速的目的。
优化工具
根据测试结果最终选定压缩版本的WM算法提交,以下为ZWM算法的优化结果。
Hotspots检测
使用Intel Amplifier的Hotspots检测功能查找热点函数,结果如下:
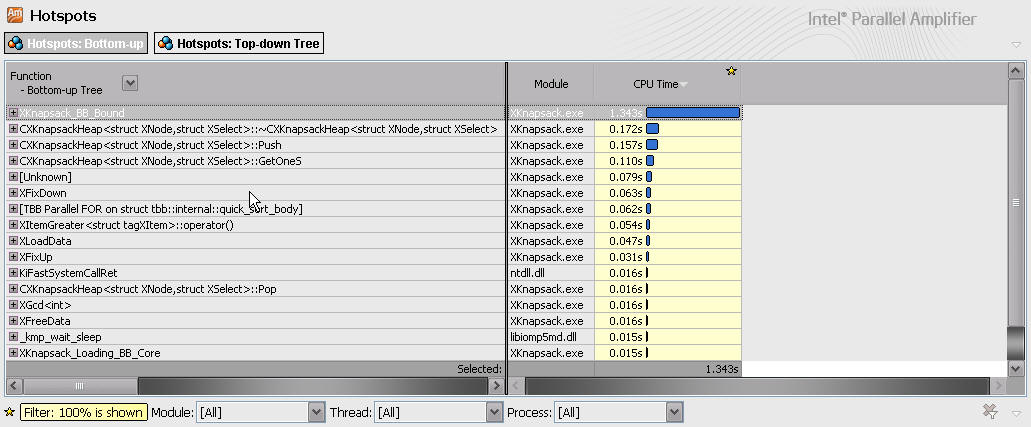
检测结果显示主要的时间开销为XKnapsack_BB_Bound价值上限估算函数,通过检测结果优化了该函数,原采用同一物品以堆为单位进行估算,优化后按物品为单位进行估算,运行效率得到了一倍的提高。
Concurrency检测
使用Intel Amplifier的Concurrency检测功能查找可进行并行优化的代码,结果如下:
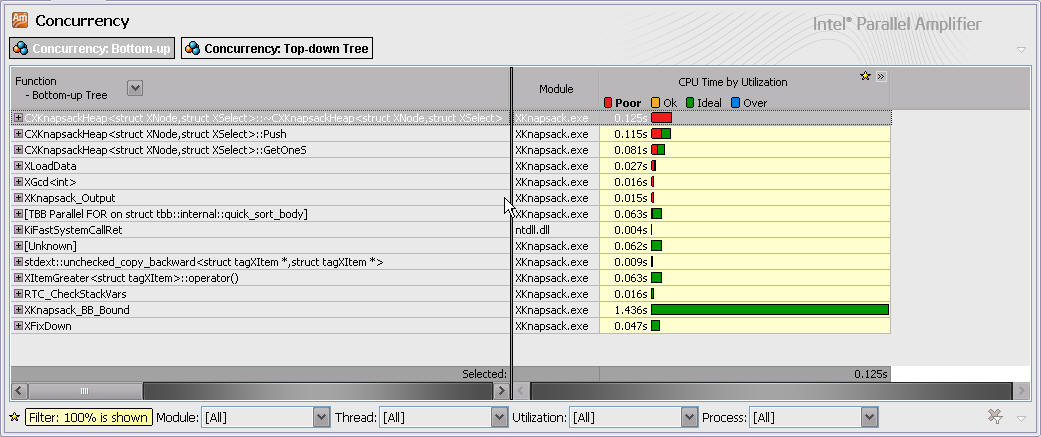 检测结果显示XKnapsack_BB_Bound价值上限估算函数具有良好的并行度。
检测结果显示XKnapsack_BB_Bound价值上限估算函数具有良好的并行度。
Locks and Waits检测
使用Intel Amplifier的Locks and Waits检测功能查找锁和同步等待消耗,结果如下:
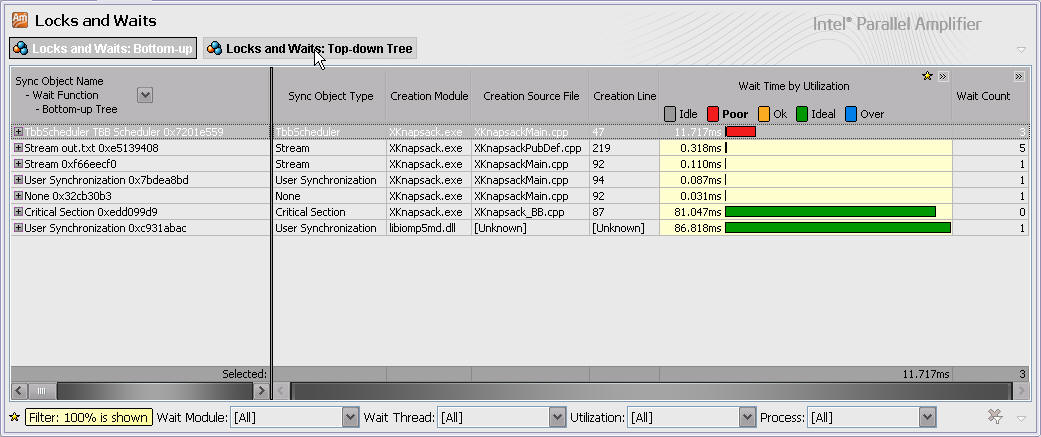 检测结果显示算法几乎不存在同步和锁消耗。
检测结果显示算法几乎不存在同步和锁消耗。
其他优化
1. 使用内存映射加载数据。
2. 使用二叉堆获取价值上限最大的节点。
3. 使用内存缓冲,减少内存分配占用的时间。
性能测试
操作系统: 32bit的测试在32位XP下完成。
CPU: Intel(R) Core(TM)2 CPU 5270 @ 1.40GHz
内存: 1G
时间单位: 秒 最短DNA序列长度:32字节
| 背包容量 | 物品数量 | 物品种类 | 串行 | 并行 | 加速比 |
| 75.00 | 99 | 10028 | 0.017726 | 0.020503 | 0.86 |
| 1000000.00 | 100 | 100000 | 0.31599 | 0.330507 | 0.96 |
编译说明
Windows平台:
使用VS2008和Intel Parallel Studio
1. 用VS2008打开本项目.
2. 选择Win32平台Release编译.
3. 进入Bin目录执行文件为XKnapsack.exe.
Linux平台:
使用ICC和TBB
1. 上传压缩包种的Src和Linux两个目录到服务器上.
2. 进入XKnapsack/Linux目录 执行make
3. 进入XKnapsack/Bin目录 执行文件为XKnapsack.
其他:
主办方请使用Win32平台Release版本测试,谢谢!
优化结论
高数据依赖的算法并行非常困难,如何在数据量很小的时候能够并行计算,使并行计算减少的时间远远大于同步的开销?我需要更多的时间去探索。
致谢
感谢Clay Breshears在论坛上所做的解答,感谢Mu,Pryce为本文章发表到ISN所做的工作,感谢Xia, JeffX P为此解决方案进行的认真细致的翻译。















 1426
1426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









