







前言
OpenCV从版本2.4开始,加入了一个类FaceRecognizer,使用它可以方便的地进行人脸识别(源代码,在opencv_contrib库的opencv_contrib/modules/face/src下)。
目前支持三种算法:
1. Eigen Faces特征脸:EigenFaceRecognizer
2. Fisher Faces:FisherFaceRecognizer
3. Local Binary Pattern Histograms(局部二值直方图):LBPHFaceRecognizer
Eigen Faces特征脸
特征脸EigenFace相当于把人脸从像素空间变换到另一个空间,在另一个空间中做相似性的计算。这么说,其实图像识别的基本思想都是一样的,首先选择一个合适的子空间,将所有的图像变换到这个子空间上,然后再在这个子空间上衡量相似性或者进行分类学习。变换到另一个空间,同一个类别的图像会聚到一起,不同类别的图像会距离比较远,或者在原像素空间中不同类别的图像在分布上很难用个简单的线或者面把他们切分开,然后如果变换到另一个空间,就可以很好的把他们分开了。有时候,线性(分类器)就可以很容易的把他们分开了。
EigenFace选择的空间变换方法是PCA,也就是大名鼎鼎的主成分分析。它广泛的被用于预处理中以消去样本特征维度之间的相关性。EigenFace方法利用PCA得到人脸分布的主要成分,具体实现是对训练集中所有人脸图像的协方差矩阵进行本征值分解,得对对应的本征向量,这些本征向量(特征向量)就是“特征脸”。每个特征向量或者特征脸相当于捕捉或者描述人脸之间的一种变化或者特性。这就意味着每个人脸都可以表示为这些特征脸的线性组合。经过PCA后空间就是以每一个特征脸或者特征向量为基,在这个空间(或者坐标轴)下,每个人脸就是一个点,这个点的坐标就是这个人脸在每个特征基下的投影坐标。
下面就直接给出基于特征脸的人脸识别实现过程:
步骤一:获取包含M张人脸图像的集合S。在我们的例子里有25张人脸图像,如下图所示哦。每张图像可以转换成一个N维的向量(是的,没错,一个像素一个像素的排成一行就好了,至于是横着还是竖着获取原图像的像素,随你自己,只要前后统一就可以),然后把这M个向量放到一个集合S里,如下式所示。
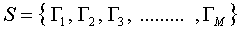

步骤二:在获取到人脸向量集合S后,计算得到平均图像Ψ ,至于怎么计算平均图像,公式在下面。就是把集合S里面的向量遍历一遍进行累加,然后取平均值。得到的这个Ψ 其实还挺有意思的,Ψ 其实也是一个N维向量,如果再把它还原回图像的形式的话,可以得到如下的“平均脸”。
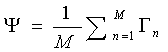

步骤三:计算每张图像和平均图像的差值Φ ,就是用S集合里的每个元素减去步骤二中的平均值。
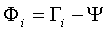
步骤四:找到M个正交的单位向量un ,这些单位向量其实是用来描述Φ (步骤三中的差值)分布的。un 里面的第k(k=1,2,3…M)个向量uk 是通过下式计算的,
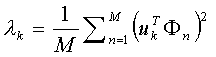
当这个λk(原文里取了个名字叫特征值)取最小的值时,uk 基本就确定了。补充一下,刚才也说了,这M个向量是相互正交而且是单位长度的,所以啦,uk 还要满足下式:
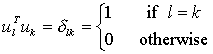
上面的等式使得uk 为单位正交向量。计算上面的uk 其实就是计算如下协方差矩阵的特征向量:
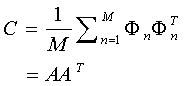
其中
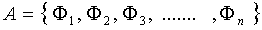
对于一个NxN(比如100x100)维的图像来说,上述直接计算其特征向量计算量实在是太大了(协方差矩阵可以达到10000x10000),所以有了如下的简单计算。
步骤四另解:如果训练图像的数量小于图像的维数比如(M
OpenCV源码
eigen_faces.cpp
void Eigenfaces::train(InputArrayOfArrays _src, InputArray _local_labels)

void Eigenfaces::predict(InputArray _src, Ptr collector)

显然10个特征向量(备注:1个特征向量可以变形成一个特征脸,这里特征向量和特征脸概念有些近似)是不够的,50个特征向量可以有效的编码出重要的人脸特征。在AT&T数据库中,当使用300个特征向量时,可以获取一个比较好的和重构结果。有定理可以给出出重构需要选择多少特征脸才合适,但它严重依赖于输入数据。
Fisher Faces
Fisherface所基于的LDA(Linear Discriminant Analysis,线性判别分析)理论和特征脸里用到的PCA有相似之处,都是对原有数据进行整体降维映射到低维空间的方法,LDA和PCA都是从数据整体入手而不同于LBP提取局部纹理特征。
数据集是二类情况
通常情况下,待匹配人脸要和人脸库内的多张人脸匹配,所以这是一个多分类的情况。出于简单考虑,可以先介绍二类的情况然后拓展到多类。假设有二维平面上的两个点集x(x是包含横纵坐标的二维向量),它们的分布如下图(1)(分别以蓝点和红点表示数据):
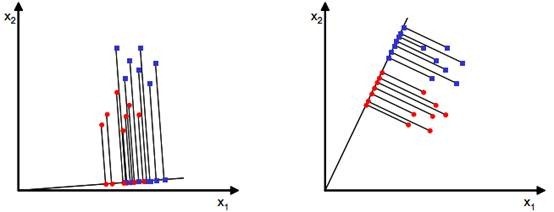
原有数据是散布在平面上的二维数据,如果想用一维的量(比如到圆点的距离)来合理的表示而且区分开这些数据,该怎么办呢?一种有效的方法是找到一个合适的向量w(和数据相同维数),将数据投影到w上(会得到一个标量,直观的理解就是投影点到坐标原点的距离),根据投影点来表示和区分原有数据。以数学公式给出投影点到到原点的距离:y=wTx。图(1)给出了两种w方案,w以从原点出发的直线来表示,直线上的点是原数据的投影点。直观判断右侧的w更好些,其上的投影点能够合理的区分原有的两个数据集。但是计算机不知道这些,所以必须要有确定的方法来计算这个w。
首先计算每类数据的均值(中心点):
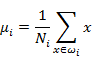
这里的i是数据的分类个数,Ni代表某个分类下的数据点数,比如u1代表红点的中心,u2代表蓝点的中心。
数据点投影到w上的中心为:
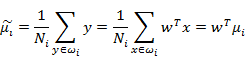
如何判断向量w最佳呢,可以从两方面考虑:1、不同的分类得到的投影点要尽量分开;2、同一个分类投影后得到的点要尽量聚合。从这两方面考虑,可以定义如下公式:
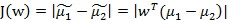
J(w)代表不同分类投影中心的距离,它的值越大越好。
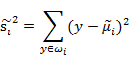
上式称之为散列值(scatter matrixs),代表同一个分类投影后的散列值,也就是投影点的聚合度,它的值越小代表投影点越聚合。
结合两个公式,第一个公式做分子另一个做分母:
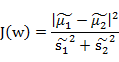
上式是w的函数,值越大w降维性能越好,所以下面的问题就是求解使上式取最大值的w。
把散列函数展开:
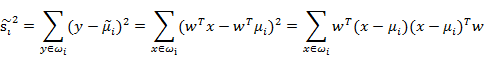
可以发现除w和w^T外,剩余部分可以定义为:

其实这就是原数据的散列矩阵了,对不对。对于固定的数据集来说,它的散列矩阵也是确定的。
另外定义:
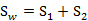
Sw称为Within-class scatter matrix。
回到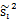
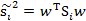
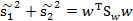
展开J(w)的分子并定义SB,SB称为Between-class scatter。
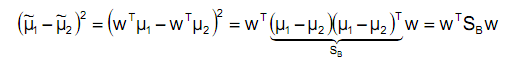
这样就得到了J(w)的最终表示:
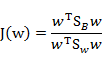
上式求极大值可以利用拉格朗日乘数法,不过需要限定一下分母的值,否则分子分母都变,怎么确定最好的w呢。可以令,利用拉格朗日乘数法得到:
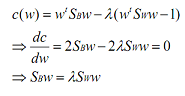
其中w是矩阵,所以求导时可以把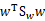
上式两边同乘以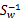
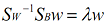
可以发现w其实就是矩阵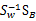
通过上式求解w还是有些困难的,而且w会有多个解,考虑下式:
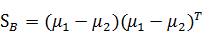
将其带入下式:
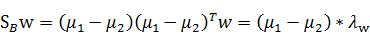
其中λw是以w为变量的数值,因为(u1-u2)^T和w是相同维数的,前者是行向量后者列向量。继续带入以前的公式:

由于w扩大缩小任何倍不影响结果,所以可以约去两遍的未知常数λ和λw(存疑):
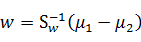
到这里,w就能够比较简单的求解了。
2、数据集是多类的情况
这部分是本博文的核心。假设有C个人的人脸图像,每个人可以有多张图像,所以按人来分,可以将图像分为C类,这节就是要解决如何判别这C个类的问题。判别之前需要先处理下图像,将每张图像按照逐行逐列的形式获取像素组成一个向量,和第一节类似设该向量为x,设向量维数为n,设x为列向量(n行1列)。
和第一节简单的二维数据分类不同,这里的n有可能成千上万,比如100x100的图像得到的向量为10000维,所以第一节里将x投影到一个向量的方法可能不适用了,比如下图:
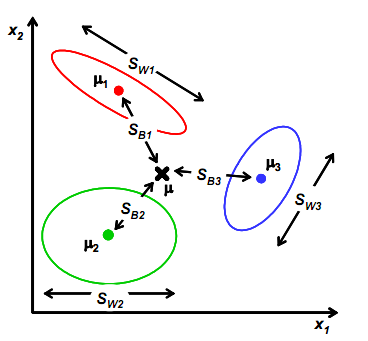
图(2)
平面内找不到一个合适的向量,能够将所有的数据投影到这个向量而且不同类间合理的分开。所以我们需要增加投影向量w的个数(当然每个向量维数和数据是相同的,不然怎么投影呢),设w为:
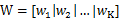
w1、w2等是n维的列向量,所以w是个n行k列的矩阵,这里的k其实可以按照需要随意选取,只要能合理表征原数据就好。x在w上的投影可以表示为:
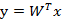
所以这里的y是k维的列向量。
像上一节一样,我们将从投影后的类间散列度和类内散列度来考虑最优的w,考虑图(2)中二维数据分为三个类别的情况。与第一节类似,μi依然代表类别i的中心,而Sw定义如下:
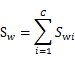
其中:
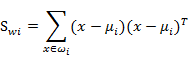
代表类别i的类内散列度,它是一个nxn的矩阵。
所有x的中心μ定义为:
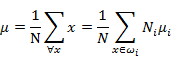
类间散列度定义和上一节有较大不同:
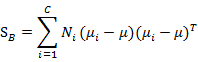
代表的是每个类别到μ距离的加和,注意Ni代表类别i内x的个数,也就是某个人的人脸图像个数。
上面的讨论都是投影之间的各种数据,而J(w)的计算实际是依靠投影之后数据分布的,所以有:
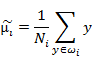
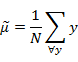
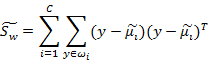
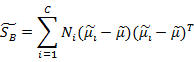
分别代表投影后的类别i的中心,所有数据的中心,类内散列矩阵,类间散列矩阵。与上节类似J(w)可以定义为:
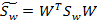
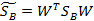
回想我们上节的公式J(w),分子是两类中心距,分母是每个类自己的散列度。现在投影方向是多维了(好几条直线),分子需要做一些改变,我们不是求两两样本中心距之和(这个对描述类别间的分散程度没有用),而是求每类中心相对于全样本中心的散列度之和。得到:
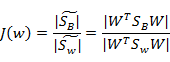
最后化为:
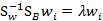
还是求解矩阵的特征向量,然后根据需求取前k个特征值最大的特征向量。
另外还需注意:
由于SB中的(μi-μ)秩为1,所以SB的至多为C(矩阵的秩小于等于各个相加矩阵的和)。又因为知道了前C-1个μi后,最后一个μc可以用前面的μi来线性表示,因此SB的秩至多为C-1,所以矩阵的特征向量个数至多为C-1。因为C是数据集的类别,所以假设有N个人的照片,那么至多可以取到N-1个特征向量来表征原数据。(存疑)
如果你读过前面的一篇文章PCA理论分析,会知道PCA里求得的特征向量都是正交的,但是这里的并不是对称的,所以求得的K个特征向量不一定正交,这是LDA和PCA最大的不同。
如前所述,如果在一个人脸集合上求得k个特征向量,还原为人脸图像的话就像下面这样:

得到了k个特征向量,如何匹配某人脸和数据库内人脸是否相似呢,方法是将这个人脸在k个特征向量上做投影,得到k维的列向量或者行向量,然后和已有的投影求得欧式距离,根据阈值来判断是否匹配。具体的方法在人脸识别经典算法一:特征脸方法(Eigenface)里有,可前往查看。需要说明的是,LDA和PCA两种方法对光照都是比较敏感的,如果你用光照均匀的图像作为依据去判别非均匀的,那基本就惨了。
OpenCV源码
fisher_faces.cpp
void Fisherfaces::train(InputArrayOfArrays _src, InputArray _local_labels)

void Fisherfaces::predict(InputArray _src, Ptr collector)
Local Binary Pattern Histograms
Eigenfaces和Fisherfaces使用整体方法来进行人脸识别。你把你的数据当作图像空间的高维向量。我们都知道高维数据是糟糕的,所以一个低维子空间被确定,对于信息保存可能很好。Eigenfaces是最大化总的散度,这样可能导致,当方差由外部条件产生时,最大方差的主成分不适合用来分类。所以为使用一些鉴别分析,我们使用了LDA方法来优化。Fisherfaces方法可以很好的运作,至少在我们假设的模型的有限情况下。
现实生活是不完美的。你无法保证在你的图像中光照条件是完美的,或者说1个人的10张照片。所以,如果每人仅仅只有一张照片呢?我们的子空间的协方差估计方法可能完全错误,所以识别也可能错误。是否记得Eigenfaces在AT&T数据库上达到了96%的识别率?对于这样有效的估计,我们需要多少张训练图像呢?下图是Eigenfaces和Fisherfaces方法在AT&T数据库上的首选识别率,这是一个简单的数据库:

因此,若你想得到好的识别率,你大约需要每个人有8(7~9)张图像,而Fisherfaces在这里并没有好的帮助。以上的实验是10个图像的交叉验证结果,使用了facerec框架: https://github.com/bytefish/facerec。
LBPH(Local Binary Patterns Histograms,局部二值模式)是提取局部特征作为判别依据的。LBPH方法显著的优点是对光照不敏感,但是依然没有解决姿态和表情的问题。不过相比于特征脸方法,LBPH的识别率已经有了很大的提升。有些人脸库的识别率已经达到了98%+。
LBP特征提取
最初的LBPH是定义在像素3x3邻域内的,以邻域中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3x3邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBPH码,共256种),即得到该邻域中心像素点的LBPH值,并用这个值来反映该区域的纹理信息。如下图所示:
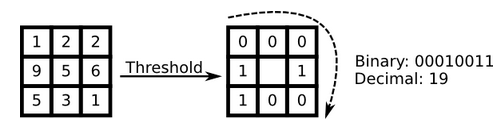
用比较正式的公式来定义的话:
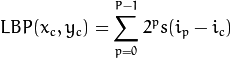
其中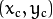

LBP的改进版本
(1)圆形LBP算子
基本的LBPH算子的最大缺陷在于它只覆盖了一个固定半径范围内的小区域,这显然不能满足不同尺寸和频率纹理的需要。为了适应不同尺度的纹理特征,并达到灰度和旋转不变性的要求,Ojala等对 LBP 算子进行了改进,将 3×3邻域扩展到任意邻域,并用圆形邻域代替了正方形邻域,改进后的 LBP 算子允许在半径为 R 的圆形邻域内有任意多个像素点。从而得到了诸如半径为R的圆形区域内含有P个采样点的LBP算子。比如下图定了一个5x5的邻域:
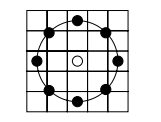
上图内有八个黑色的采样点,每个采样点的值可以通过下式计算:
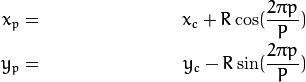
其中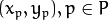

(2)LBP等价模式
一个LBP算子可以产生不同的二进制模式,对于半径为R的圆形区域内含有P个采样点的LBP算子将会产生2^P种模式。很显然,随着邻域集内采样点数的增加,二进制模式的种类是急剧增加的。例如:5×5邻域内20个采样点,有220=1,048,576种二进制模式。如此多的二值模式无论对于纹理的提取还是对于纹理的识别、分类及信息的存取都是不利的。同时,过多的模式种类对于纹理的表达是不利的。例如,将LBP算子用于纹理分类或人脸识别时,常采用LBP模式的统计直方图来表达图像的信息,而较多的模式种类将使得数据量过大,且直方图过于稀疏。因此,需要对原始的LBP模式进行降维,使得数据量减少的情况下能最好的代表图像的信息。
为了解决二进制模式过多的问题,提高统计性,Ojala提出了采用一种“等价模式”(Uniform Pattern)来对LBP算子的模式种类进行降维。Ojala等认为,在实际图像中,绝大多数LBP模式最多只包含两次从1到0或从0到1的跳变。因此,Ojala将“等价模式”定义为:当某个LBP所对应的循环二进制数从0到1或从1到0最多有两次跳变时,该LBP所对应的二进制就称为一个等价模式类。如00000000(0次跳变),00000111(只含一次从0到1的跳变),10001111(先由1跳到0,再由0跳到1,共两次跳变)都是等价模式类。除等价模式类以外的模式都归为另一类,称为混合模式类,例如10010111(共四次跳变)。比如下图给出了几种等价模式的示意图。
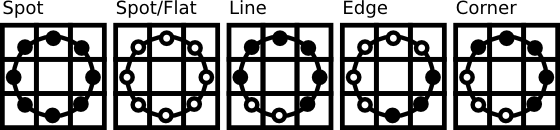
通过这样的改进,二进制模式的种类大大减少,而不会丢失任何信息。模式数量由原来的2P种减少为 P ( P-1)+2种,其中P表示邻域集内的采样点数。对于3×3邻域内8个采样点来说,二进制模式由原始的256种减少为58种,这使得特征向量的维数更少,并且可以减少高频噪声带来的影响。
通过上述方法,每个像素都会根据邻域信息得到一个LBP值,如果以图像的形式显示出来可以得到下图,明显LBP对光照有较强的鲁棒性。

LBP特征匹配
如果将以上得到的LBP值直接用于人脸识别,其实和不提取LBP特征没什么区别,会造成计算量准确率等一系列问题。文献[1]中,将一副人脸图像分为7x7的子区域(如下图),并在子区域内根据LBP值统计其直方图,以直方图作为其判别特征。这样做的好处是在一定范围内避免图像没完全对准的情况,同时也对LBP特征做了降维处理。

对于得到的直方图特征,有多种方法可以判别其相似性,假设已知人脸直方图为Mi,待匹配人脸直方图为Si,那么可以通过:
(1)直方图交叉核方法
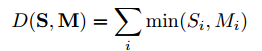
该方法的介绍在博文:Histogram intersection(直方图交叉核,Pyramid Match Kernel)
(2)卡方统计方法
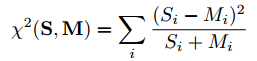
该方法的介绍在博文:卡方检验(Chi square statistic)
OpenCV源码
lbph_faces.cpp
void LBPH::train(InputArrayOfArrays _in_src, InputArray _in_labels, bool preserveData)



void LBPH::predict(InputArray _src, Ptr collector)















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









