






排序:
本章大部分内容假设整个排序工作能在主存中完成,因此元素个数较小(10的六次方)内部排序
在磁盘或磁带上完成的排序也很重要,这种排序成为外部排序
我们假设N是排序例程中的元素个数,对于所有的排序,数据都将在位置0开始
1、插入排序
插入排序保证元素是已经排过序的

如果输入数据已预先排序,那运行时间为O(N²)
通过交换相邻元素进行排序的任何算法要花费Ω(N²)
希尔排序:
它通过比较一定间隔的元素来排序,间隔的距离随着算法的进行而减小,直到比较相邻元素(插入排序),所以也叫缩小增量排序

通过角标不变并拆分成几个小数组的方法
然后各自改变每一个小数组的方式来排序
关键是要选择一个增量序列ht(间隔的元素)
每个元素相隔hk

建议的序列就是把N个元素除以2并向下取整
直到取到hk为1(插入排序)
以上的序列还可改进
代码

堆排序:
优先队列可以花费O(NlogN))时间排序,基于该想法的算法叫堆排序
实践中却慢与Sedgewick增量序列的希尔排序
通过第二个数组记录deletemin的值
因为使用了第二个数组,所以存储需求增加一倍
所以可以在deletemin时把值记录在最后一个空穴,最后堆就会以递减的方式存储。
也就是把第一个元素和最后一个元素交换,空间得以重复利用
哈夫曼树(最优二叉树):
路径:从树的一个结点到另一个结点之间的分支构成这两个结点间的路径
结点的路径长度:两结点间路径上的分支数
树的路径长度·:从树根到每一个结点的路径长度之和,记作TL
结点数相同的二叉树中,完全二叉树是路径长度最短的二叉树
权:
将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权`
结点的带权路径长度:
从根节点到该结点之间的路径长度与该结点的权的乘积·
树的带权路径长度:
树中所有叶子结点的带权路径长度之和记作WPL

哈夫曼树:最优树(带权路径长度(WPL)最短的树
带权路径长度最短,是在度相同的树中比较而得的,因此有最优二叉树,最优三叉树等
哈夫曼树:最优二叉树(带权路径长度(WPL)最短的二叉树

贪心算法:构造哈夫曼树时首先选择权值小的叶子结点
哈夫曼算法:·
构造森林全是根:
(1)根据n个权值构成n颗二叉树的森林,每个数的根节点就是权值
选用两小造新树:
(2)在森林里选取权值最小的树作为左右子树构造一棵新的二叉树,新树的根节点权值为其左右子树上根结点的权值之和
删除两小提添新人
(3)删除这两棵树,并将新得到的二叉树加入森林
重复2、3剩单根
(4)重复(2)(3)直到森林只有一棵树,这棵树即为哈夫曼树

总结:

哈夫曼树的实现:

因为哈夫曼树有2n-1个节点,所有使用数组时大小为2n(从0开始)
哈夫曼编码:
1、统计字符集中每个字符在电文中出现的平均概率
2、利用哈夫曼树的特点:权越大的叶子离根越近,将每个字符的概率值作为权值,构造哈夫曼树,则概率越大的结点,路径越短
3、在哈夫曼树的每个分支上标0或者1
结点的左分支标0,右分支标1
把从根到每个叶子的路径标号连起来,作为该叶子代表的字符的编码
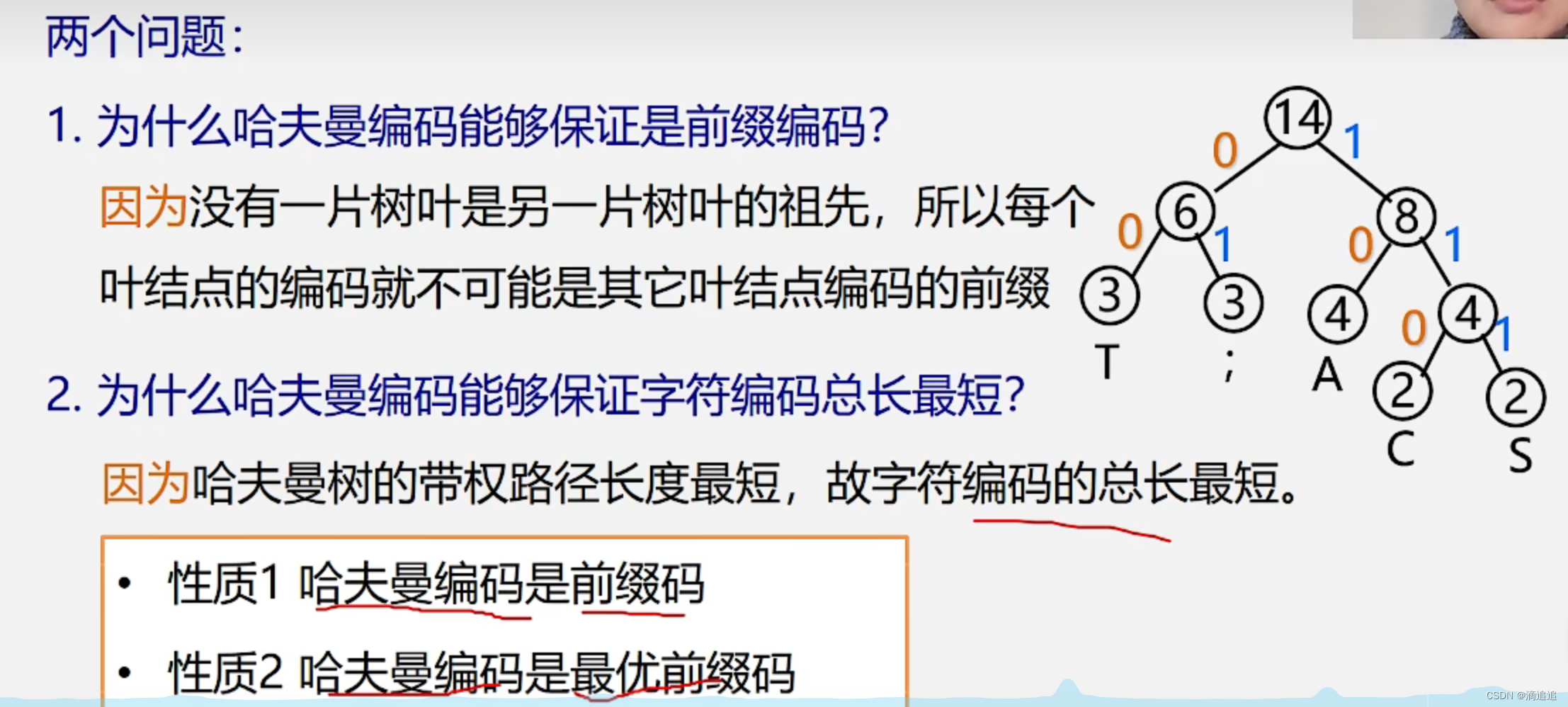
前缀码即使不会发生重码
求哈夫曼编码

图:
G=(V,E)
V:顶点的有穷非空集合
E:边的有穷集合
无向图:每条边都是没方向的
有向图:每条边都是有方向的
完全图:任意两个点都有一条边相连

稀疏图:有很少边或弧的图(e<nlogn)】
稠密图:有较多边或弧的图
网:边/弧带权的图
邻接:有边/弧相连两个顶点之间的关系
存在(vi, vj)则称vi和vj互为邻接点(圆括号无先后关系,无向图)
存在<vi, vj>则称,vi邻接到vj,vj邻接与vi(尖括号表示vi到vj是有序的序偶,有向图)
关联(依附):边/弧度与顶点的关系
存在(vi,vj)或<vi, vj>则称该边/弧依附于vi和vj














 336
336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









