






解决的问题:将手写数字的灰度图像(28像素x28像素)划分到10个类别中(0~9)
在机器学习中,分类问题中的某个类别叫做类(class)。数据点叫做样本。某个样本(sample)对应的类叫做标签(label)。
1.加载Keras中的MNIST的数据集。(注意加载MNIST数据集时,需要连接外网,或者直接下载mnist.npz文件添加到\.keras\datasets\文件夹下)
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()train_images和train_labels构成训练集(train set),模型将从这些数据中进行学习。然后在测试集(test set 即test_images和test_labels)上对模型进行测试。(train_images.shape=[60000,28,28],test_images.shape=[10000,28,28]) 图像被编码成Numpy数组,而标签是数字数组,取范围是0~9。图像和标签一一对应。 接下来的工作流程是:首先,将训练数据(train_images和train_labels)输入神经网络;其次,网络学习将标签和图像关联起来;最后,网络对test_images进行预测,而我们需要验证这些预测与test_labels中的标签是否一致。 2.构建网络
from tensorflow.keras import models
from tensorflow.keras import layers
network = models.Sequential()
network.add(layers.Dense(512, activation='relu', input_shape=(28*28,)))
network.add(layers.Dense(10, activation='softmax'))神经网络的核心组件就是层(layer),它是一种数据处理模块,你可以将它视为数据过滤器。大多数深度学习就是将简单将其链接起来,从而实现渐进式的数据蒸馏(data distillation)。深度学习模型就像是数据处理的筛子,包含一系列越来越精细的数据过滤器(层)。本网络中共包含两个Dense层,它们是密集连接(全连接)的神经层。第二层是一个10路softmax层,它将返回一个由10个概率值(总和为1)组成的数组。每个概率表示当前数字图像属于10数字类别中的某一个的概率。
3.编译步骤
network.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics='accuracy')要想训练网络,我们还需要选择编译步骤中的三个参数。
损失函数(loss function):网络如何衡量在训练数据上的性能,即网络如何朝着正确的方向前进。
优化器(optimizer):基于训练数据和损失函数来更新网络的机制。
在训练和测试过程中需要监控的指标(metric):本网络只关心精度,即正确分类的图像所占的比例。
4.准备图像数据
train_images = train_images.reshape((60000, 28*28))
train_images = train_images.astype('float32')/255
test_images = test_images.reshape((10000, 28*28))
test_images = test_images.astype('float32')/255在训练之前,需要对图像进行预处理,将其变换成网络要求的形状,并缩放到所有值都在[0,1]区间。比如,训练图像之前保存在uint8类型的数组中,其形状为(60000,28,28),取值区间为[0,255]。我们需要将其变换为一个float32数组,其形状为(60000,28*28),取值区间为[0,1]。
5.准备标签
from tensorflow.keras.utils import to_categorical
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)6.训练网络
network.fit(train_images, train_labels, epochs=5, batch_size=128)网络开始在训练数据上进行迭代(每个小批量包含128个样本),共迭代5次(在所有训练数据上迭代一次叫做一个轮次(epoch))。每次迭代过程中,网络会计算批量损失相对于权重的梯度,并相应的更新权重。
训练过程显示了两个数字,一个是网络在训练数据上的损失(loss),另一个是在训练数据上的精度(acc)。我们很快在训练数据上达到了98.08%的精度。
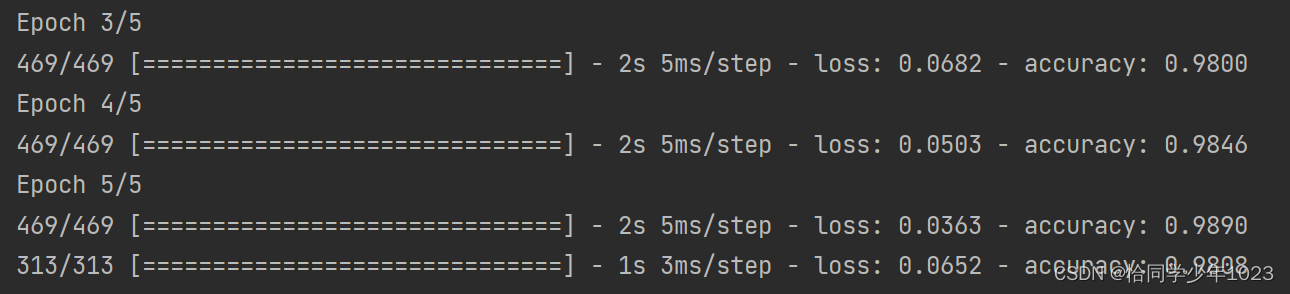
7.模型测试(检查模型在测试集上的性能)
test_loss, test_acc = network.evaluate(test_images, test_labels)
print('test_acc:', test_acc)在测试集上模型的测试精度为98.079%
![]()
知识小结:
1.学习是指找到一组模型参数,使得在给定训练数据样本和对应的目标值上的损失函数最小化。
2.学习的过程:随机选取包含数据样本及其目标值的批量,并计算损失函数相对于网络参数的梯度。然后将网络参数沿着梯度的反方向稍稍移动(移动距离由学习率决定)
3.整个学习过程之所以能够实现,是因为神经网络是一系列可微分的张量运算,因此可以利用求导的链式法则来得到梯度函数,这个函数将当前参数和当前数据批量映射为一个梯度值。
4.损失是在训练过程中需要最小化的量,因此,它可以能够衡量当前任务是否已成功解决。
5.优化器是使用损失梯度更新参数的具体方式,比如:RMSProp优化器、带动量的随机梯度下降(SGD)等。















 976
976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









