







本文为 Introduction to 3D Game Programming with DirectX 11 读书笔记
坐标系统
DirectX使用的是左手坐标系,使用左手坐标系计算叉乘的时候方向用左手决定
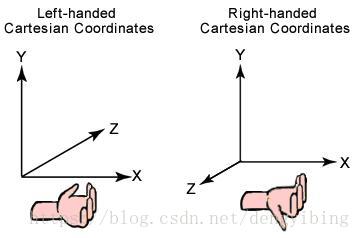
书上给的图如下
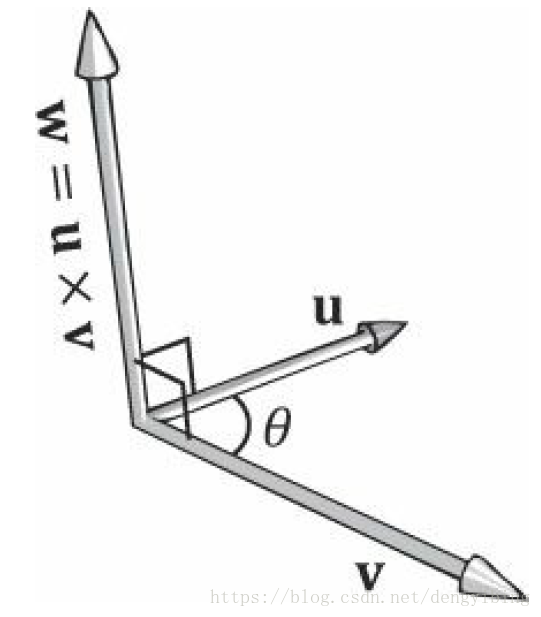
Vector Algebra
win10已经把DirectX11集成到了windows SDK中,所以如果是使用win10做开发,则不需要手动下载DirectX11的类库。
对于D3D11,数学计算库用XNA Math library,该库提供了SIMD指令的封装,SIMD是单指令多数据,简而言之就是计算速度更快,所以在每当要做计算的时候就要对矩阵、向量等做类型转换。
要使用XNA Math library只要,原先是xnmath.h,但是早就不可用了,下面是正确的
#include <DirectXMath.h>
#include <DirectXPackedVector.h>
using namespace DirectX;
using namespace DirectX::PackedVector;SIMD一条指令使用多个数据,比如4个32位的数都放到一个128位的寄存器上,然后执行一次运算指令,得到输出,这样对于同样的操作,执行4次指令,得到输出要快大约4倍。
XNA Math定义的可以执行SIMD的Vector类型是 XMVECTOR,这是一个128位的类型,可以用SIMD指令处理4个32位的浮点数。如果机器支持SSE2,则将会有定义
typedef __m128 XMVECTOR;XMVECTOR需要16位对齐,对于局部变量和全局变量都是如此,上面解释了SIMD,需要把整块数据都移到寄存器上,但这都是自动完成的。
对于一般的类中使用的变脸则使用一般的struct类型就行了,只有在需要计算的时候才做转换。
一般的类型基本如下,之后说到的矩阵也是类似的情况。
typedef struct _XMFLOAT2 {
FLOAT x;
FLOAT y;
} XMFLOAT2;
typedef struct _XMFLOAT3 {
FLOAT x;
FLOAT y;
FLOAT z;
} XMFLOAT3;
typedef struct _XMFLOAT4 {
FLOAT x;
FLOAT y;
FLOAT z;
FLOAT w;
} XMFLOAT4;XMFLOAT*类型与XMVECTOR类型的相互转换。
// Loads XMFLOAT2 into XMVECTOR
XMVECTOR XMLoadFloat2(CONST XMFLOAT2 *pSource);
// Loads XMFLOAT3 into XMVECTOR
XMVECTOR XMLoadFloat3(CONST XMFLOAT3 *pSource);
// Loads XMFLOAT4 into XMVECTOR
XMVECTOR XMLoadFloat4(CONST XMFLOAT4 *pSource);
// Loads 3-element UINT array into XMVECTOR
XMVECTOR XMLoadInt3(CONST UINT* pSource);
// Loads XMCOLOR into XMVECTOR
XMVECTOR XMLoadColor(CONST XMCOLOR *pSource);
// Loads XMBYTE4 into XMVECTOR
XMVECTOR XMLoadByte4(CONST XMBYTE4 *pSource);
// Loads XMVECTOR into XMFLOAT2
VOID XMStoreFloat2(XMFLOAT2 *pDestination, FXMVECTOR V);
// Loads XMVECTOR into XMFLOAT3
VOID XMStoreFloat3(XMFLOAT3 *pDestination, FXMVECTOR V);
// Loads XMVECTOR into XMFLOAT4
VOID XMStoreFloat4(XMFLOAT4 *pDestination, FXMVECTOR V);
// Loads XMVECTOR into 3 element UINT array
VOID XMStoreInt3(UINT* pDestination, FXMVECTOR V);
// Loads XMVECTOR into XMCOLOR
VOID XMStoreColor(XMCOLOR* pDestination, FXMVECTOR V);
// Loads XMVECTOR into XMBYTE4
VOID XMStoreByte4(XMBYTE4 *pDestination, FXMVECTOR V);
FLOAT XMVectorGetX(FXMVECTOR V);
FLOAT XMVectorGetY(FXMVECTOR V);
FLOAT XMVectorGetZ(FXMVECTOR V);
FLOAT XMVectorGetW(FXMVECTOR V);
XMVECTOR XMVectorSetX(FXMVECTOR V, FLOAT x);
XMVECTOR XMVectorSetY(FXMVECTOR V, FLOAT y);
XMVECTOR XMVectorSetZ(FXMVECTOR V, FLOAT z);
XMVECTOR XMVectorSetW(FXMVECTOR V, FLOAT w);
类型定义
// 32-bit Windows
typedef const XMVECTOR FXMVECTOR;
typedef const XMVECTOR& CXMVECTOR;
// 64-bit Windows
typedef const XMVECTOR& FXMVECTOR;
typedef const XMVECTOR& CXMVECTOR;有很多方法都已经被DirectXMath高效的实现了,要善用高效的方法。
Matrix Algebra
矩阵的情况跟向量的一样,简单说一下常用的矩阵的性质:
行列式
矩阵的行列式在计算逆矩阵的时候会用到,百度百科对行列的简单介绍,更多的看wiki,行列式返回一个实数
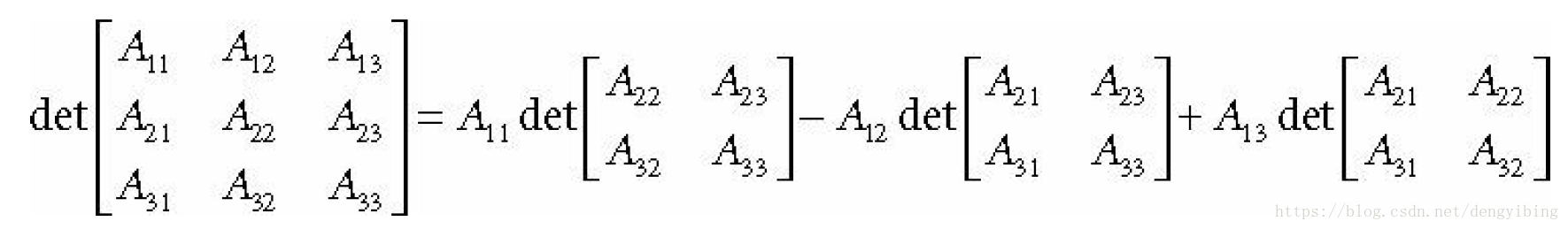
伴随矩阵
A∗
A
∗
设矩阵
A=(aij)n×n
A
=
(
a
i
j
)
n
×
n
,将矩阵A的元素
aij
a
i
j
所在的第i行第j列元素划去后,剩余的
(n−1)2
(
n
−
1
)
2
个元素按原来的排列顺序组成的n-1阶矩阵所确定的行列式称为元素
aij
a
i
j
的余子式,记为
Mij
M
i
j
,称
Aij=(−1)i+jMij
A
i
j
=
(
−
1
)
i
+
j
M
i
j
为元素
aij
a
i
j
的代数余子式。
方阵的
A=(aij)n×n
A
=
(
a
i
j
)
n
×
n
各元素的代数余子式
Aij
A
i
j
所构成的如下矩阵
A∗
A
∗
:
该矩阵 A∗ A ∗ 称为矩阵A的伴随矩阵。
逆矩阵
当然最基础还是矩阵与逆矩阵的乘机为单位矩阵
XNA类型跟Vector非常类似
TRANSFORMATIONS
下面说到的矩阵变换表示都是对向量右乘一个矩阵,对向量
u=(x,y,z)
u
=
(
x
,
y
,
z
)
执行矩阵
A
A
的变换
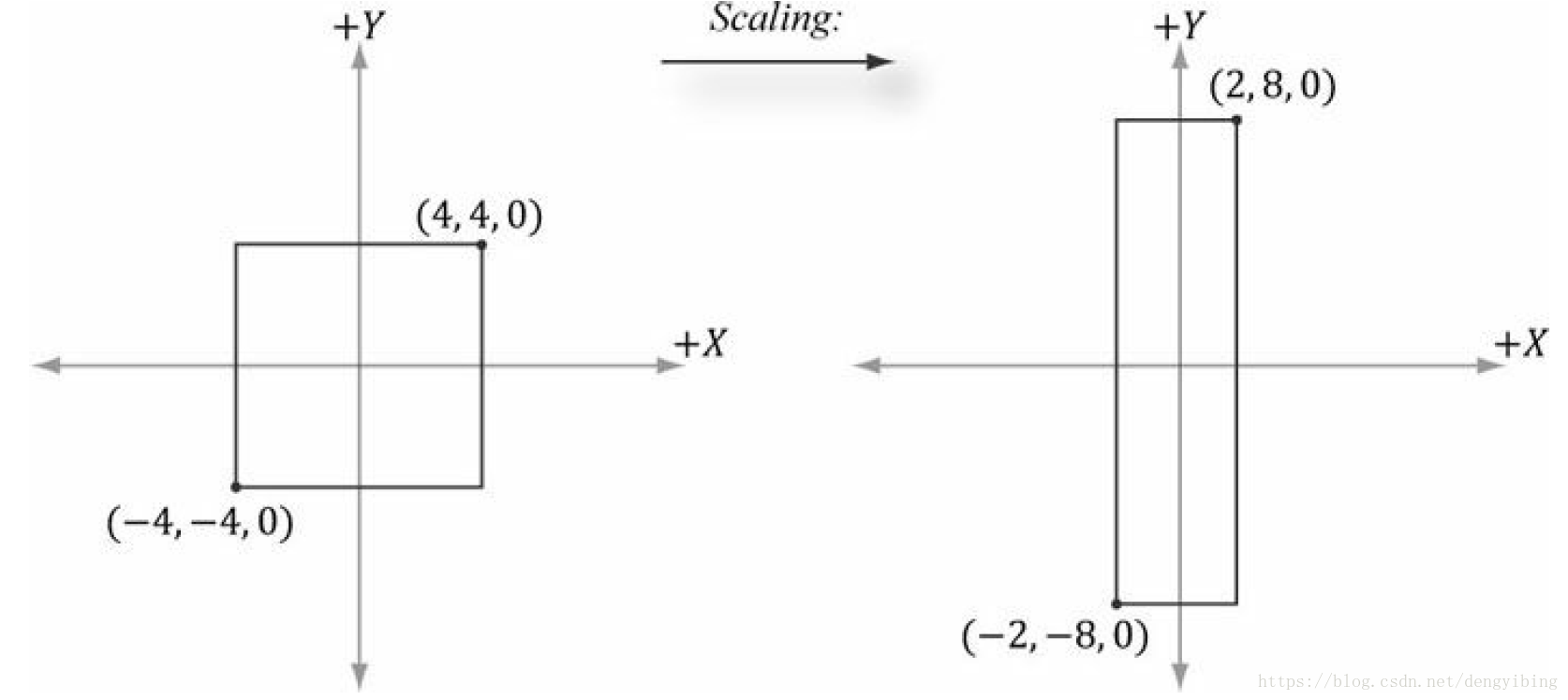
缩放
矩阵表示,沿着
x,y,z
x
,
y
,
z
轴旋转的缩放系数分别是
sx,sy,sz
s
x
,
s
y
,
s
z
其逆矩阵为
例子
旋转
绕任意轴旋转,比如绕轴
n
n
旋转,假设为单位长度。此时向量 v 要绕着轴 n 旋转 角度,得到
Rn(v)
R
n
(
v
)
。把v分解为平行于n的部分
projn(v)
p
r
o
j
n
(
v
)
和垂直于n的部分.
v⊥=perpn(v)=v−projn(v)
v
⊥
=
p
e
r
p
n
(
v
)
=
v
−
p
r
o
j
n
(
v
)
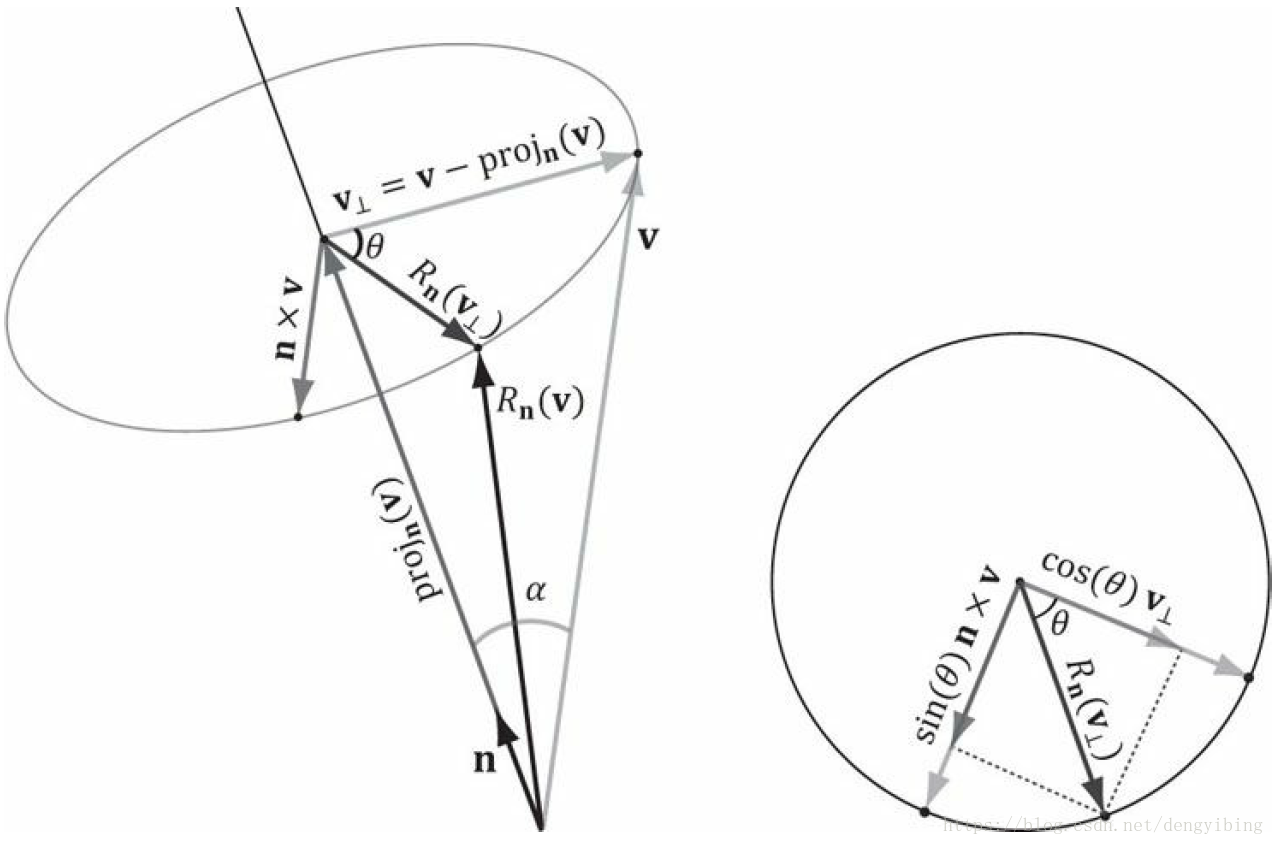
由上图可以得到
把上面公式写成跟公式(1)类似的,对向量 (x,y,z) ( x , y , z ) 做旋转,矩阵形式如下,其中 c=cosθ,s=sinθ c = cos θ , s = sin θ :
而且该矩阵为正交矩阵,正交矩阵的逆为其转置
则作为特殊情况,绕
x,y,z
x
,
y
,
z
轴
(n=(1,0,0),n=(0,1,0),n=(0,0,1))
(
n
=
(
1
,
0
,
0
)
,
n
=
(
0
,
1
,
0
)
,
n
=
(
0
,
0
,
1
)
)
分别旋转的旋转矩阵分别如下
仿射变换
仿射变换就是带偏移的线性变换,可以表示为如下:
但是上面的写法很麻烦,所以用4维向量和矩阵计算将会更简洁高效,因为GPU本身就是并行运算能力超强。
所以上面改写为如下:
上面是对点的变换,所以把最后一项设置为1,因为点有偏移;但是,对于向量来说,是没有偏移这个概念的,所以最后一项设置为0。这样的4维向量和矩阵才是图形学中常用的形式。
移动
转移矩阵可以写为
其逆矩阵
对缩放和旋转的仿射矩阵
仿射变换矩阵的几何解释
上面介绍的仿射变换就是旋转/缩放,移动
用公式表示
a(x,y,z)=τ(x,y,z)+b=xτ(i)+yτ(j)+zτ(k)+b
a
(
x
,
y
,
z
)
=
τ
(
x
,
y
,
z
)
+
b
=
x
τ
(
i
)
+
y
τ
(
j
)
+
z
τ
(
k
)
+
b
如下(其中对于顶点
w=1
w
=
1
,对于向量
w=0
w
=
0
):
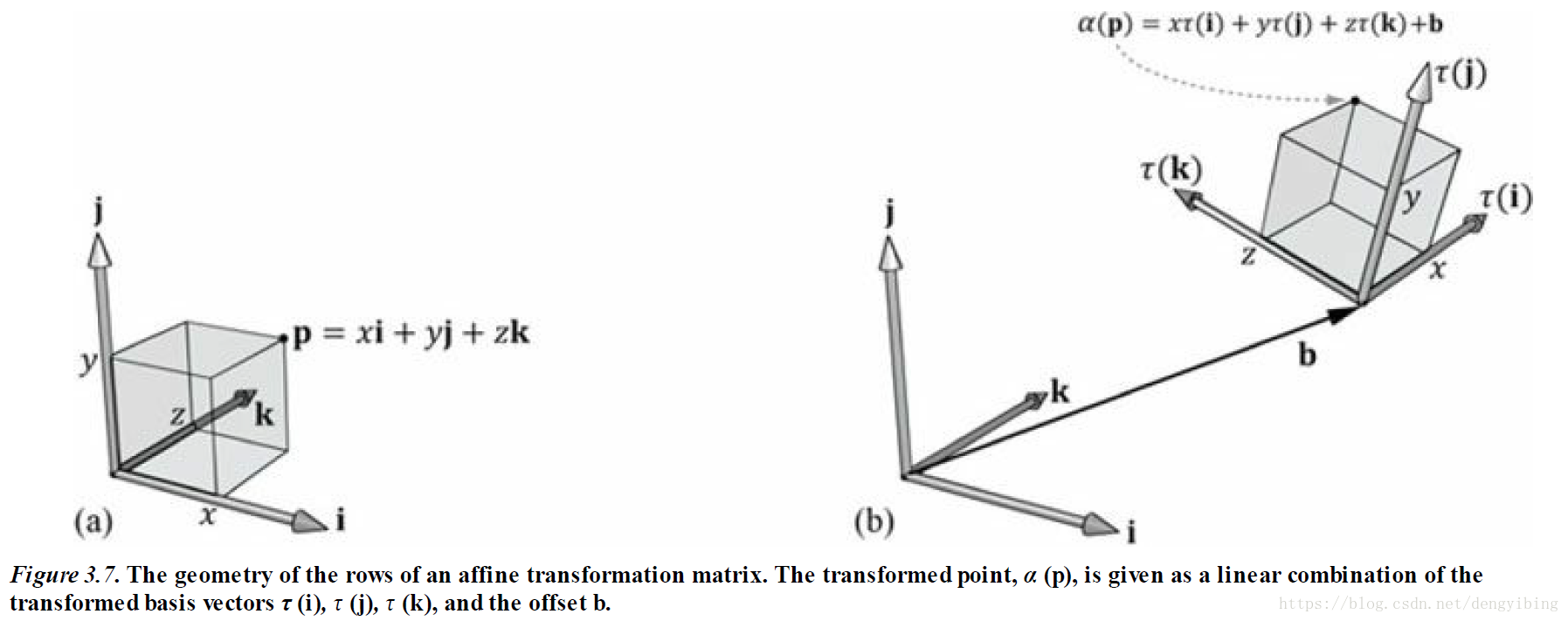
因为矩阵有结合律但没有交换律,所以矩阵相乘最后作用于对象的顺序非常关键,是先旋转再平移与先平移再旋转有很大差别。
坐标系变换
摄氏度与华氏度表示相同的问题时数字大小是不一样的,不同的基底(坐标系)之间的转换得到相同坐标不同的表示。
对基底的变换与做顶点和向量的变换不同,刚好是完全相反的。
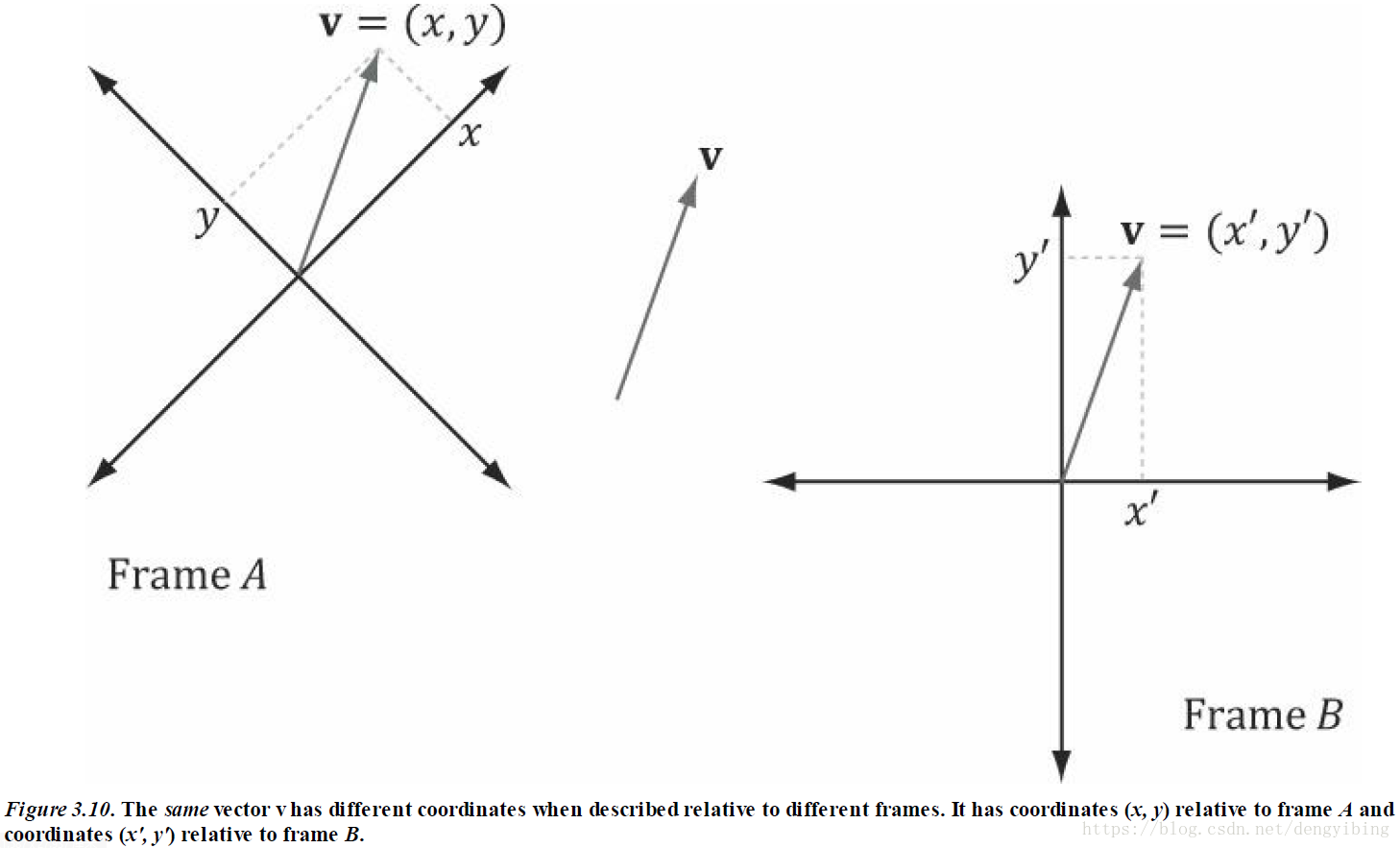
简单的坐标系统变换
顶点和向量的坐标转换,将坐标系A下的顶点表示转换为坐标系B下的顶点表示。
跟之前介绍的一样, w=0 w = 0 表示对向量的坐标系变换, w=1 w = 1 表示对顶点的变换。
上式写成矩阵形式
其中 QB=(Qx,Qy,Qz,1),uB=(ux,uy,uz,0),vB=(vx,vy,vz,0),wB=(wx,wy,wz,0) Q B = ( Q x , Q y , Q z , 1 ) , u B = ( u x , u y , u z , 0 ) , v B = ( v x , v y , v z , 0 ) , w B = ( w x , w y , w z , 0 ) 分别表示原点以及齐次坐标系A相对于齐次坐标系B的轴。
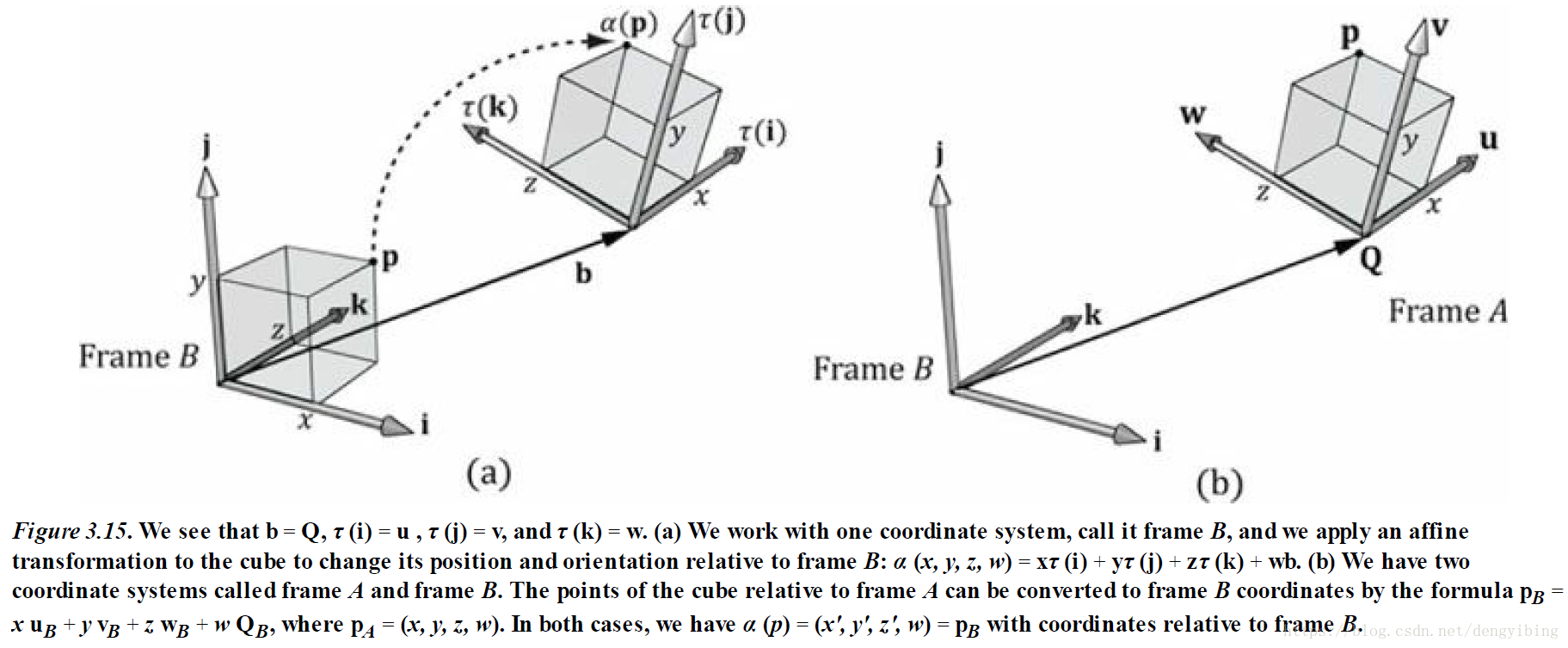
给个例子,如下图:
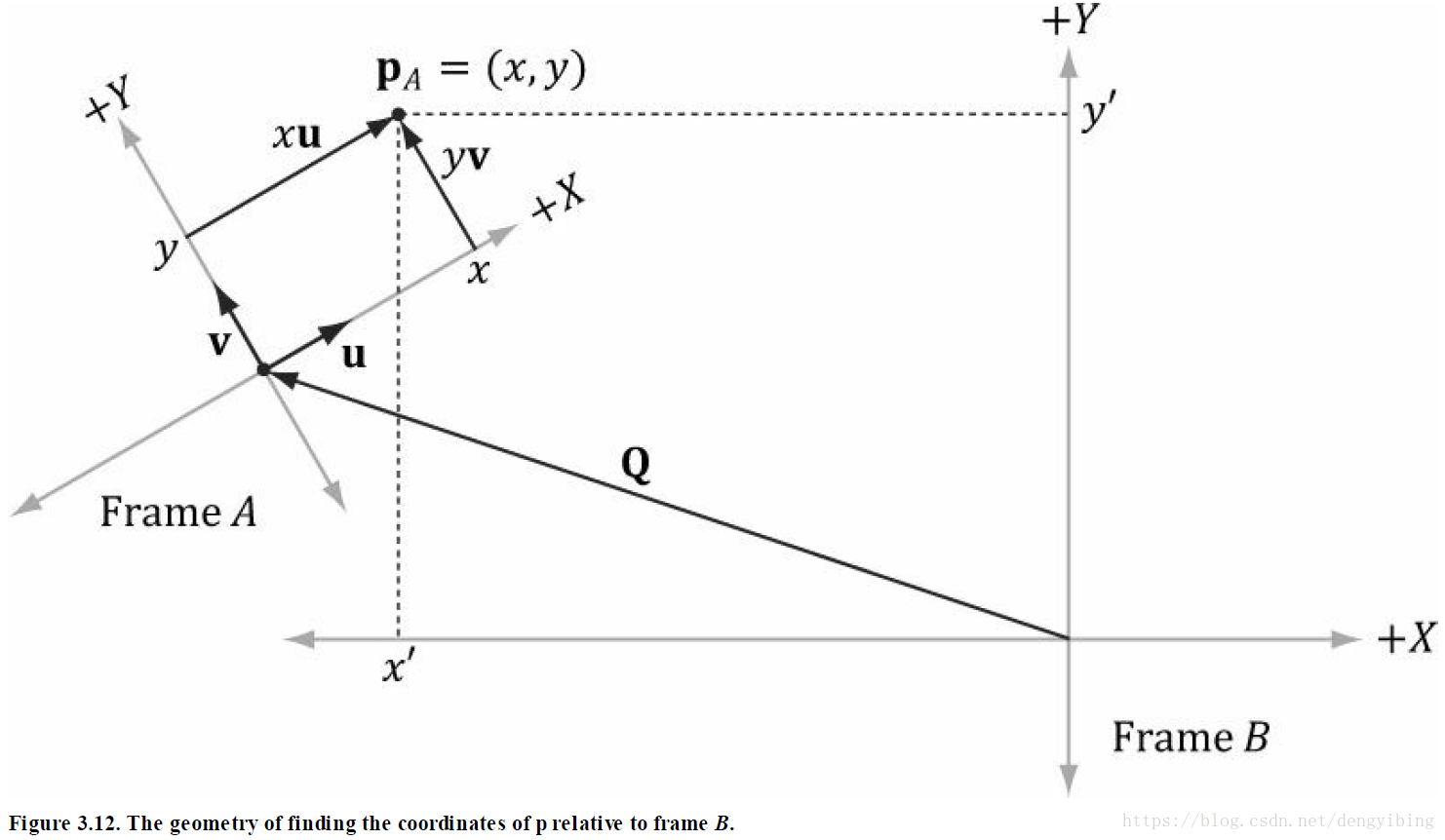
比较转换矩阵和坐标系变换矩阵
TRANSFORMATION MATRIX VERSUS CHANGE OF COORDINATE MATRIX
其实两者数学上是等价的,不同之处在于理解和解释转换的方式有所不同
XNA的实现
在XNA中,所有这些转换都已经实现了
// Constructs a scaling matrix:
XMMATRIX XMMatrixScaling(
FLOAT ScaleX,
FLOAT ScaleY,
FLOAT ScaleZ); // Scaling factors
// Constructs a scaling matrix from components in vector:
XMMATR IX XMMatrixScalingFromVector(
FXMVECTOR Scale); // Scaling factors (sx , sy , sz)
// Constructs a x-axis rotation matrix : Rx
XMMATRIX XMMatrixRotationX(
FLOAT Angle); // Clockwise angle θ to rotate
// Constructs a y-axis rotation matrix : Ry
XMMATRIX XMMatrixRotationY(
FLOAT Angle); // Clockwise angle θ to rotate
// Constructs a z-axis rotation matrix : Rz
XMMATRIX XMMatrixRotationZ(
FLOAT Angle); // Clockwise angle θ to rotate
// Constructs an arbitrary axis rotation matrix : Rn
XMMATRIX XMMatrixRotationAxis(
FXMVECTOR Axis, // Axis n to rotate about
FLOAT Angle); // Clockwise angle θ to rotate
//Constructs a translation matrix:
XMMATRIX XMMatrixTranslation(
FLOAT OffsetX,
FLOAT OffsetY,
FLOAT OffsetZ); // Translation factors
//Constructs a translation matrix from components in a vector:
XMMATRIX XMMatrixTranslationFromVector(
FXMVECTOR Offset); // Translation factors (tx , ty ,tz)
// Computes the vector-matrix product vM:
XMVECTOR XMVector3Transform(
FXMVECTOR V, // Input v
CXMMATRIX M); // Input M
// Computes the vector-matrix product vM where vw = 1 for transforming points:
XMVECTOR XMVector3TransformCoord(
FXMVECTOR V, // Input v
CXMMATRIX M); // Input M
// Computes the vector-matrix product vM where vw = 0 for transforming vectors:
XMVECTOR XMVector3TransformNormal(
FXMVECTOR V, // Input v
CXMMATRIX M); // Input M














 3720
3720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









