







各位同学好,今天和大家分享一下Pandas库中Series的基本操作方法。
内容有:①检查缺失值;②通过索引获取数据;③布尔索引;④name属性;⑤读取前几行数据;⑥读取后几行数据。
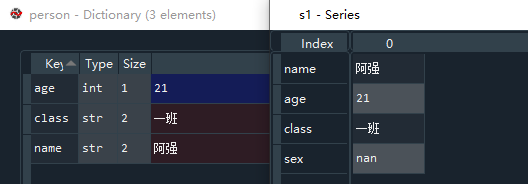
首先我们先定义一个Series
import pandas as pd #导入pandas库
person = {"name":"阿强","age":21,"class":"一班"} #定义一个字典person
# 生成一个Series,给它命名s1,以列表中给定的索引顺序排序,其中索引'sex'对应的值为None
s1 = pd.Series(person,["name","age","class","sex"])
(1)检查缺失值
方法: Series名.isnull() 和 Series名.notnull()
isnull() 判断索引对应的值是否为空,若为空,返回True。语句返回值为Series类型。
notnull() 判断索引对应的值是否为非空,若为空,返回False。
如下图所示,s1中索引'sex'对应的值为nan,因此用isnull()判断后,s2接收返回值,'sex'的返回值是True,其余返回的都是False。并且s2为Series类型。
#(1)检查缺失值
s2 = s1.isnull() # isnull判断值是否为空,空就返回一个True
s3 = s1.notnull() 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











