







环境:Win8.1 TensorFlow1.0.1
软件:Anaconda3 (集成Python3及开发环境)
TensorFlow安装:pip install tensorflow (CPU版) pip install tensorflow-gpu (GPU版)
转载:
1. 《TensorFlow实战》,黄文坚
2. 独家 |《TensorFlow实战》作者黄文坚:四大经典CNN网络技术原理
上篇博文中介绍了 ILSVRC 及往年的经典模型 AlexNet,VGG,Google Inception V1, 本文继续介绍 Inception 的后续版本,和15年微软著名的 ResNet。
6. Google Inception Net
Google Inception Net 的大家族包括:
- 2014年9月 Going Deeper with Convolutions 提出的 Inception V1(top-5错误率6.67%);
- 2015年2月 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate 提出的Inception V2(top-5错误率4.8%);
- 2015年12月 Rethinking the Inception Architecture for Computer Vision 提出的 Inception V3(top-5错误率3.5%);
- 2016年2月 Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning 提出的Inception V4(top-5错误率3.08%)。
Inception V2 学习了 VGGNet,用两个3´3的卷积代替5´5的大卷积(用以降低参数量并减轻过拟合),还提出了著名的Batch Normalization(以下简称BN)方法。BN 是一个非常有效的正则化方法,可以让大型卷积网络的训练速度加快很多倍,同时收敛后的分类准确率也可以得到大幅提高。BN 在用于神经网络某层时,会对每一个 mini-batch 数据的内部进行标准化(normalization)处理,使输出规范化到 N(0,1) 的正态分布,减少了Internal Covariate Shift(内部神经元分布的改变)。
补充:在 TensorFlow 1.0.0 中采用 tf.image.per_image_standardization() 对图像进行标准化,旧版为 tf.image.per_image_whitening。
BN 的论文指出,传统的深度神经网络在训练时,每一层的输入的分布都在变化,导致训练变得困难,我们只能使用一个很小的学习速率解决这个问题。而对每一层使用 BN 之后,我们就可以有效地解决这个问题,学习速率可以增大很多倍,达到之前的准确率所需要的迭代次数只有1/14,训练时间大大缩短。而达到之前的准确率后,可以继续训练,并最终取得远超于 Inception V1 模型的性能—— top-5 错误率4.8%,已经优于人眼水平。因为 BN 某种意义上还起到了正则化的作用,所以可以减少或者取消 Dropout,简化网络结构。当然,只是单纯地使用 BN 获得的增益还不明显,还需要一些相应的调整:
- 增大学习速率并加快学习衰减速度以适用 BN 规范化后的数据;
- 去除 Dropout 并减轻 L2正则(因BN已起到正则化的作用);
- 去除 LRN;
- 更彻底地对训练样本进行 shuffle;
- 减少数据增强过程中对数据的光学畸变(因为BN训练更快,每个样本被训练的次数更少,因此更真实的样本对训练更有帮助)。
- 在使用了这些措施后,Inception V2 在训练达到 Inception V1 的准确率时快了14倍,并且模型在收敛时的准确率上限更高。
而 Inception V3 网络则主要有两方面的改造:
一是引入了 Factorization into small convolutions 的思想,将一个较大的二维卷积拆成两个较小的一维卷积,比如将7´7卷积拆成1´7卷积和7´1卷积,或者将3´3卷积拆成1´3卷积和3´1卷积,如下图所示。一方面节约了大量参数,加速运算并减轻了过拟合(比将7´7卷积拆成1´7卷积和7´1卷积,比拆成3个3´3卷积更节约参数),同时增加了一层非线性扩展模型表达能力。论文中指出,这种非对称的卷积结构拆分,其结果比对称地拆为几个相同的小卷积核效果更明显,可以处理更多、更丰富的空间特征,增加特征多样性。
将一个3´3卷积拆成1´3卷积和3´1卷积
另一方面,Inception V3 优化了 Inception Module 的结构,现在 Inception Module 有35´35、17´17和8´8三种不同结构,如下图所示。这些 Inception Module 只在网络的后部出现,前部还是普通的卷积层。并且 Inception V3 除了在 Inception Module 中使用分支,还在分支中使用了分支(8´8的结构中),可以说是Network In Network In Network。

Inception V3 中三种结构的 Inception Module
而 Inception V4 相比 V3 主要是结合了微软的 ResNet,而 ResNet 将在下一节单独讲解,这里不多做赘述。因此本节将实现的是 Inception V3,其整个网络结构如下表所示。由于 Google Inception Net V3 相对比较复杂,所以这里使用 tf.contrib.slim 辅助设计这个网络。contrib.slim 中的一些功能和组件可以大大减少设计 Inception Net 的代码量,我们只需要少量代码即可构建好有42层深的 Inception V3。
Inception V3 网络结构

7. ResNet
ResNet(Residual Neural Network)由微软研究院的 Kaiming He 等4名华人提出,通过使用 Residual Unit 成功训练152层深的神经网络,在 ILSVRC 2015 比赛中获得了冠军,取得3.57%的 top-5 错误率,同时参数量却比 VGGNet 低,效果非常突出。ResNet 的结构可以极快地加速超深神经网络的训练,模型的准确率也有非常大的提升。上一节我们讲解并实现了 Inception V3,而 Inception V4 则是将 Inception Module 和 ResNet 相结合。可以看到 ResNet 是一个推广性非常好的网络结构,甚至可以直接应用到 Inception Net 中。本节就讲解 ResNet 的基本原理,以及如何用 TensorFlow 来实现它。
在 ResNet 之前,瑞士教授 Schmidhuber 提出了 Highway Network,原理与 ResNet 很相似。这位 Schmidhuber 教授同时也是 LSTM 网络的发明者,而且是早在1997年发明的,可谓是神经网络领域元老级的学者。通常认为神经网络的深度对其性能非常重要,但是网络越深其训练难度越大,Highway Network 的目标就是解决极深的神经网络难以训练的问题。Highway Network 相当于修改了每一层的激活函数,此前的激活函数只是对输入做一个非线性变换,Highway NetWork 则允许保留一定比例的原始输入x。这样前面一层的信息,有一定比例可以不经过矩阵乘法和非线性变换,直接传输到下一层,仿佛一条信息高速公路,因此得名Highway Network。
Highway Network 主要通过 gating units 学习如何控制网络中的信息流,即学习原始信息应保留的比例。这个可学习的 gating 机制,正是借鉴自 Schmidhuber 教授早年的 LSTM 循环神经网络中的 gating。几百乃至上千层深的 Highway Network 可以直接使用梯度下降算法训练,并可以配合多种非线性激活函数,学习极深的神经网络现在变得可行了。事实上,Highway Network 的设计在理论上允许其训练任意深的网络,其优化方法基本上与网络的深度独立,而传统的神经网络结构则对深度非常敏感,训练复杂度随深度增加而急剧增加。
ResNet 和 HighWay Network 非常类似,也是允许原始输入信息直接传输到后面的层中。ResNet 最初的灵感出自这个问题:在不断加神经网络的深度时,会出现一个 Degradation 的问题,即准确率会先上升然后达到饱和,再持续增加深度则会导致准确率下降。这并不是过拟合的问题,因为不光在测试集上误差增大,训练集本身误差也会增大。假设有一个比较浅的网络达到了饱和的准确率,那么后面再加上几个的全等映射层,起码误差不会增加,即更深的网络不应该带来训练集上误差上升。而这里提到的使用全等映射直接将前一层输出传到后面的思想,就是 ResNet 的灵感来源。
假定某段神经网络的输入是 x,期望输出是 H(x),如果我们直接把输入 x 传到输出作为初始结果,那么此时我们需要学习的目标就是F(x)=H(x)-x。如下图所示,这就是一个 ResNet 的残差学习单元(Residual Unit),ResNet 相当于将学习目标改变了,不再是学习一个完整的输出,只是输出和输入的差别,即残差F(x)。
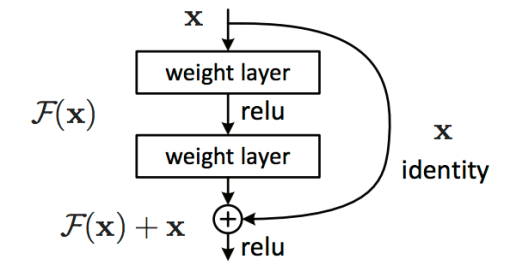
ResNet的残差学习模块
下图所示为 VGGNet-19,以及一个34层深的普通卷积网络,和34层深的 ResNet 网络的对比图。可以看到普通直连的卷积神经网络和 ResNet 的最大区别在于,ResNet 有很多旁路的支线将输入直接连到后面的层,使得后面的层可以直接学习残差,这种结构也被称为shortcut 或 skip connections。
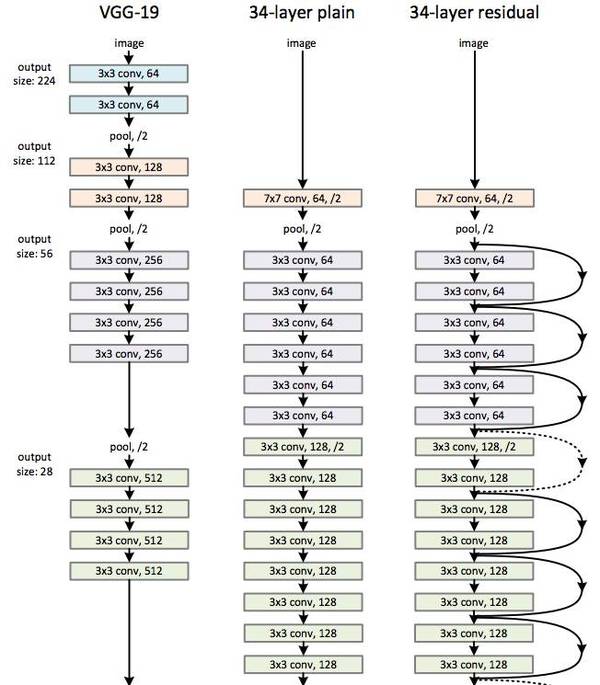
VGG-19,直连的34层网络,ResNet的34层网络的结构对比
传统的卷积层或全连接层在信息传递时,或多或少会存在信息丢失、损耗等问题。ResNet 在某种程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络则只需要学习输入、输出差别的那一部分,简化学习目标和难度。
在 ResNet 的论文中,除了提出残差学习单元的两层残差学习单元,还有三层的残差学习单元。两层的残差学习单元中包含两个相同输出通道数(因为残差等于目标输出减去输入,即,因此输入、输出维度需保持一致)的3´3卷积;而3层的残差网络则使用了 Network In Network 和 Inception Net 中的1´1卷积,并且是在中间3´3的卷积前后都使用了1´1卷积,有先降维再升维的操作。另外,如果有输入、输出维度不同的情况,我们可以对x 做一个线性映射变换维度,再连接到后面的层。
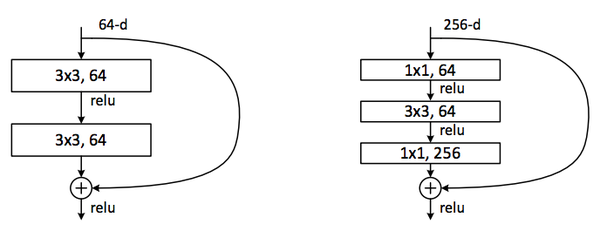
两层及三层的 ResNet 残差学习模块
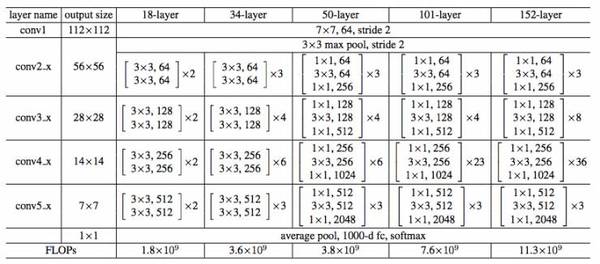
下表所示为 ResNet 在不同层数时的网络配置,其中基础结构很类似,都是前面提到的两层和三层的残差学习单元的堆叠。
ResNet不同层数时的网络配置
在使用了 ResNet 的结构后,可以发现层数不断加深导致的训练集上误差增大的现象被消除了,ResNet 网络的训练误差会随着层数增大而逐渐减小,并且在测试集上的表现也会变好。在 ResNet 推出后不久,Google 就借鉴了 ResNet 的精髓,提出了 Inception V4 和 Inception-ResNet-V2,并通过融合这两个模型,在 ILSVRC 数据集上取得了惊人的3.08%的错误率。
可见,ResNet 及其思想对卷积神经网络研究的贡献确实非常显著,具有很强的推广性。在 ResNet 的作者的第二篇相关论文 Identity Mappings in Deep Residual Networks中,ResNet V2 被提出。ResNet V2 和ResNet V1 的主要区别在于,作者通过研究 ResNet 残差学习单元的传播公式,发现前馈和反馈信号可以直接传输,因此 skip connection 的非线性激活函数(如ReLU)替换为 Identity Mappings()。同时,ResNet V2 在每一层中都使用了 Batch Normalization。这样处理之后,新的残差学习单元将比以前更容易训练且泛化性更强。
根据 Schmidhuber 教授的观点,ResNet 类似于一个没有 gates 的 LSTM 网络,即将输入 x 传递到后面层的过程是一直发生的,而不是学习出来的。同时,最近也有两篇论文表示,ResNet 基本等价于 RNN 且 ResNet 的效果类似于在多层网络间的集成方法(ensemble)。ResNet 在加深网络层数上做出了重大贡献,而另一篇论文 The Power of Depth for Feedforward Neural Networks 则从理论上证明了加深网络比加宽网络更有效,算是给 ResNet 提供了声援,也是给深度学习为什么要深才有效提供了合理解释。
8. 总结
以上,我们简单回顾了卷积神经网络的历史,下图所示大致勾勒出最近几十年卷积神经网络的发展方向。
Perceptron(感知机)于1957年由 Frank Resenblatt 提出,而 Perceptron 不仅是卷积网络,也是神经网络的始祖。Neocognitron(神经认知机)是一种多层级的神经网络,由日本科学家 Kunihiko Fukushima 于20世纪80年代提出,具有一定程度的视觉认知的功能,并直接启发了后来的卷积神经网络。LeNet-5 由 CNN 之父 Yann LeCun 于1997年提出,首次提出了多层级联的卷积结构,可对手写数字进行有效识别。

卷积神经网络发展图
可以看到前面这三次关于卷积神经网络的技术突破,间隔时间非常长,需要十余年甚至更久才出现一次理论创新。而后于2012年,Hinton 的学生 Alex 依靠8层深的卷积神经网络一举获得了 ILSVRC 2012 比赛的冠军,瞬间点燃了卷积神经网络研究的热潮。AlexNet 成功应用了 ReLU 激活函数、Dropout、最大覆盖池化、LRN 层、GPU加速等新技术,并启发了后续更多的技术创新,卷积神经网络的研究从此进入快车道。
在AlexNet之后,我们可以将卷积神经网络的发展分为两类,一类是网络结构上的改进调整(上图中的左侧分支),另一类是网络深度的增加(上图的右侧分支)。
2013年,颜水成教授的 Network in Network 工作首次发表,优化了卷积神经网络的结构,并推广了1´1的卷积结构。在改进卷积网络结构的工作中,后继者还有2014年的 Google Inception Net V1,提出了 Inception Module 这个可以反复堆叠的高效的卷积网络结构,并获得了当年 ILSVRC 比赛的冠军。2015年初的 Inception V2 提出了 Batch Normalization,大大加速了训练过程,并提升了网络性能。2015年年末的 Inception V3 则继续优化了网络结构,提出了 Factorization in Small Convolutions 的思想,分解大尺寸卷积为多个小卷积乃至一维卷积。
而另一条分支上,许多研究工作则致力于加深网络层数,2014年,ILSVRC比赛的亚军 VGGNet 全程使用3´3的卷积,成功训练了深达19层的网络,当年的季军 MSRA-Net 也使用了非常深的网络。2015年,微软的 ResNet 成功训练了152层深的网络,一举拿下了当年 ILSVRC 比赛的冠军,top-5 错误率降低至3.46%。其后又更新了ResNet V2,增加了 Batch Normalization,并去除了激活层而使用 Identity Mapping 或 Preactivation,进一步提升了网络性能。此后,Inception ResNet V2 融合了 Inception Net 优良的网络结构,和 ResNet 训练极深网络的残差学习模块,集两个方向之长,取得了更好的分类效果。
我们可以看到,自 AlexNet 于2012年提出后,深度学习领域的研究发展极其迅速,基本上每年甚至每几个月都会出现新一代的技术。新的技术往往伴随着新的网络结构,更深的网络的训练方法等,并在图像识别等领域不断创造新的准确率记录。至今,ILSVRC 比赛和卷积神经网络的研究依然处于高速发展期,CNN 的技术日新月异。当然其中不可忽视的推动力是,我们拥有了更快的GPU计算资源用以实验,以及非常方便的开源工具(比如TensorFlow)可以让研究人员快速地进行探索和尝试。在以前,研究人员如果没有像 Alex 那样高超的编程实力能自己实现 cuda-convnet,可能都没办法设计 CNN 或者快速地进行实验。现在有了 TensorFlow,研究人员和开发人员都可以简单而快速地设计神经网络结构并进行研究、测试、部署乃至实用。















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









