







 NVIDIA A100 GPU基于Ampere架构,提供显著的性能提升,如增强的Tensor Core支持TF32和FP64,提供更高的计算吞吐量。新特性包括多实例GPU(MIG)虚拟化,可提高GPU利用率和安全性。A100的第三代NVLink和更大的L2缓存增强了多GPU扩展性和I/O性能。此外,A100支持结构化稀疏性,使计算吞吐量翻倍。此GPU适用于HPC、AI和数据分析等领域。
NVIDIA A100 GPU基于Ampere架构,提供显著的性能提升,如增强的Tensor Core支持TF32和FP64,提供更高的计算吞吐量。新特性包括多实例GPU(MIG)虚拟化,可提高GPU利用率和安全性。A100的第三代NVLink和更大的L2缓存增强了多GPU扩展性和I/O性能。此外,A100支持结构化稀疏性,使计算吞吐量翻倍。此GPU适用于HPC、AI和数据分析等领域。
2020 年 5 月 14日,NVIDIA 创始人兼首席执行官黄仁勋在 NVIDIA GTC 2020 主题演讲中介绍了基于最新 Ampere 架构的 NVIDIA A100 GPU。这篇文章将会带你深入了解这颗 GPU 并介绍 Ampere 结构的一些关键特性。
本文翻译自
https://devblogs.nvidia.com/nvidia-ampere-architecture-in-depth/
Part1.
NVIDIA A100 Tensor Core GPU介绍
NVIDIA A100 Tensor Core GPU 基于最新的 Ampere 架构,相比上一代 NVIDIA Tesla V100 GPU 增加了了许多新特性,在 HPC,AI 和数据分析领域都有更好的表现。
A100 为 GPU 计算和深度学习应用提供了超强扩展性,可以运行在单卡或多卡 GPU 工作站、服务器、集群、云数据中心、 边缘计算系统以及超算中心。A100 GPU 可以构建灵活,弹性且高性能的数据中心。

A100 搭载了革命性的多实例 GPU(Multi-instance GPU 或 MIG)虚拟化与 GPU 切割能力,对云服务供应商(CSPs)更加友好。当配置为 MIG 运行状态时,A100 可以通过分出最多 7 个核心来帮助供应商提高 GPU 服务器的利用率,无需额外投入。A100 稳定的故障分离也能够让供应商安全的分割GPU。
A100 带有性能强劲的第三代 Tensor Core,支持更为丰富的 DL 和 HPC 数据类型,同时具有比 V100 更高的计算吞吐。A100 新的稀疏(Sparsity)特性能够进一步让计算吞吐翻倍。
新的 TensorFloat-32 (TF32) 核心运算单元让 A100 在 DL 框架和 HPC 中轻松加速以 FP32 作为输入/输出数据的运算,比 V100 FP32 FMA 操作快10倍,稀疏优化(sparse)下可以达到20倍。在 FP16/FP32 的混合精度下也能达到 V100 的 2.5 倍,稀疏优化后达 5 倍。
新的 Bfloat16(BF16)/FP32 混合精度 Tensor Core 运算单元和 FP16/FP32 混合精度以相同的频率运行。Tensor Core 对 INT8,INT4 和 INT1 的加速为 DL 推理提供了全面支持,A100 sparse INT8 比 V100 INT8 快 20 倍。在 HPC 中,A100 Tensor 核心的 IEEE 兼容 FP64 处理让它的表现是 V100的 2.5 倍。
A100 不仅仅可以胜任复杂的大型工作,它同样可以有效率的加速许多小型工作。A100 能够让搭建的数据中心根据不同的工作需求做调整,提供更细致的工作配置,更高的 GPU 利用率以及更好的 TCO。
如图 2 所示,相对于 V100,A100 在训练和推理工作上提供了额外的加速。图 3 同样显示了 A100 在不同 HPC 应用上的表现有了显著的提升。

图 2 . A100 GPU 在 BERT 深度学习训练和推理场景中的性能与 NVIDIA Tesla V100 和 NVIDIA Tesla T4 的对比
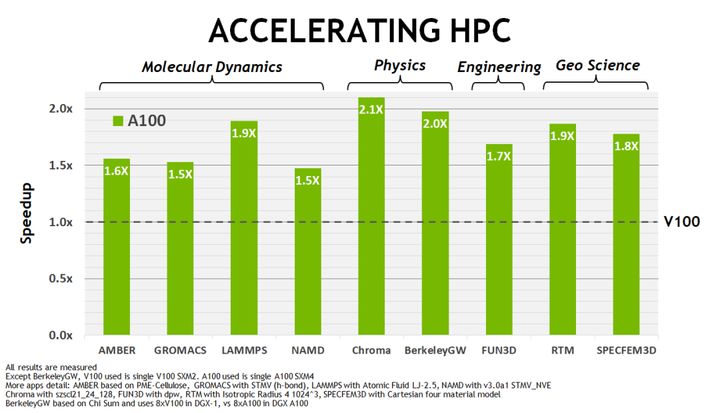
图 3. NVIDIA Tesla V100 A100 GPU HPC 应用速度提升与 NVIDIA Tesla V100 的对比
Part2.
核心特性
台积电 7nm 制程的 Ampere 架构 GA100 GPU 让 A100 在 826mm 的大小上拥有了 542 亿个晶体管
▍A100 GPU 流式多处理器
新的流式多处理器(SM)让 Ampere 架构的 A100 Tensor Core GPU 得到了显著的性能提升,在 Volta 和 Turning SM 架构上有了许多新特性,同时增加了许多新功能。
A100 的第三代 Tensor Core 增强了操作数共享并提高了效率,同时添加了功能强大的新数据类型,其中包括:
- 能够加速 FP32 数据处理的 TF32 Tensor Core 指令
- 适用于 HPC 的 IEEE 兼容的 FP64 Tensor Core 指令
- 和 FP16 达到同样吞吐的 BF16 Tensor Core 指令
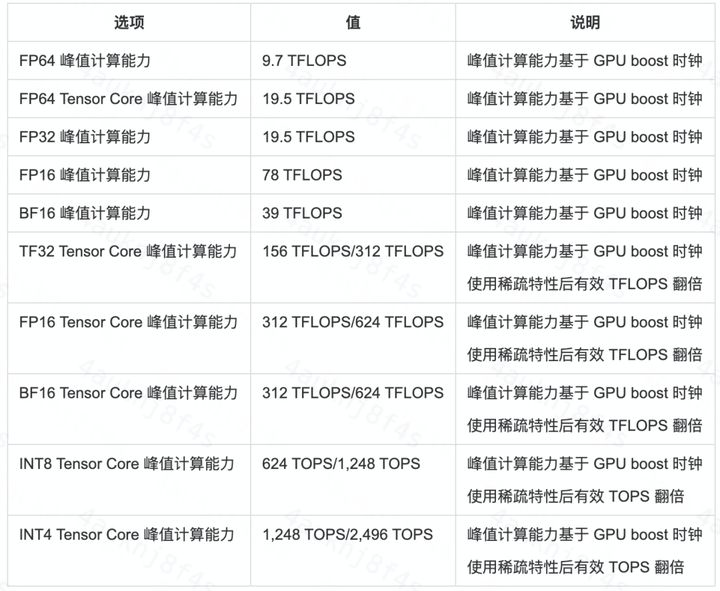
表1. A100 Tensor Core GPU 性能详单
A100 Tenso Core 的稀疏性(Sparsity)支持可以利用 DL 网络中细粒度的结构稀疏性来达到两倍的吞吐量。稀疏特性会在后文中讲解。
A100 更大更快的 L1 缓存和 shared memory 能够让它在每个流处理器上提供相当于 V100 1.5 倍的总容量(192 KB vs. 128 KB),为 HPC 和 AI 任务提供进一步加速。
一些新的流处理器特性可以提高效率及可编程性,同时降低软件复杂度。
▍40 GB HBM2 和 40 MB L2 缓存
为了满足其巨大的计算吞吐量,NVIDIA A100 GPU 拥有 40 GB 的高速 HBM2 显存以及顶尖 1555GB/s 的显存带宽,与 Tesla V100 相比提升了 73%。
此外,A100 GPU 拥有更多的片上存储,其中包括 40 MB 的 L2 缓存(比V100大近7倍)以最大化计算性能。借助新的分区交叉开关结构,A100 L2 缓存读取带宽是 V100 的 2.3 倍。
为了利用大容量片上存储进行性能优化,NVIDIA Ampere 架构提供了 L2 缓存驻留控制,让开发者自行决定保留或舍弃缓存数据。
A100 还增加了计算数据压缩功能,以使 DRAM 带宽和 L2 带宽最多增加 4 倍,L2 容量最多增加 2 倍。
▍多实例GPU
新的多实例GPU(MIG)特性能让 A100 被安全的分割成最多 7 个 GPU 实例,能够为多用户提供隔离的 GPU 资源,以加速他们的应用。
在 MIG 中每个 GPU 实例都有独立且隔离的显存通道、片上 crossbar 端口、SM、L2 缓存、显存控制器和 DRAM 地址总线。这样即
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1307
1307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









