






Milvus是什么
(一)Milvus 是向量数据库
Milvus 是一款向量数据库,于 2019 年开源,可用于存储、索引和管理由深度神经网络学习与其他机器学习模型生成的海量向量。
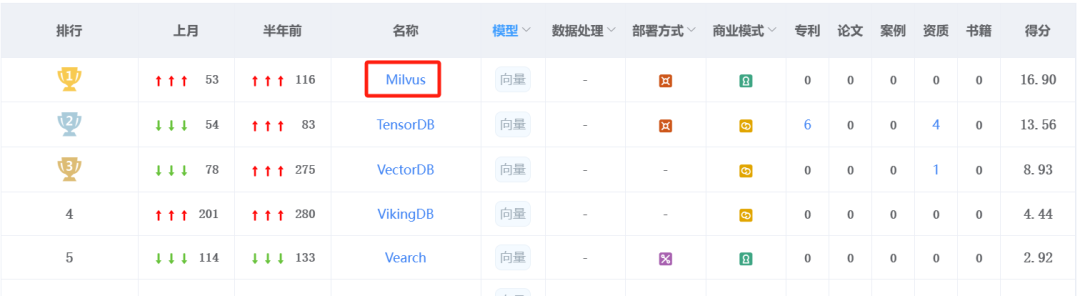
Milvus 在墨天轮中的向量数据库赛道中,排名第一。
(二)Milvus 有什么优势
搭建相似性搜索应用十分容易,但是将应用投入生产会面临不小的挑战。向量数据的结构十分复杂,因此不适合使用传统的数据表格。有些开发者会使用向量检索库来存储向量数据和进行向量相似性搜索。
但是,使用这种方法,会在构建索引时遇到问题。此外,搭建向量存储解决方案的成本高昂,并且还需要考虑扩展性的问题。Milvus 向量数据库能够帮助您轻松应对上述问题。
● 简单易用:使用 Milvus 向量数据库,仅需几分钟便可轻松搭建大型向量相似性搜索服务。Milvus 提供多种语言的 SDK,操作简单直观。
● 快速高效:Milvus 有效节省硬件资源,并提供多样的索引算法。Milvus 性能出色,向量召回速率极高。
● 高可用性:Milvus 向量数据库受上千家企业信赖,适用于多种用例场景。Milvus 系统组件相互独立、隔离,能充分确保系统弹性和可靠性。
● 高可扩展性:Milvus 的分布式架构和高吞吐量特性使其非常适合处理大规模向量数据。
● 云原生:Milvus 是一款云原生的向量数据库,采用存储与计算分离的架构设计,支持灵活扩展。
● 丰富功能:Milvus 支持多种数据类型,提供数据过滤、多种数据一致性等级、Time Travel 等丰富的功能。
(三)Milvus 的工作原理
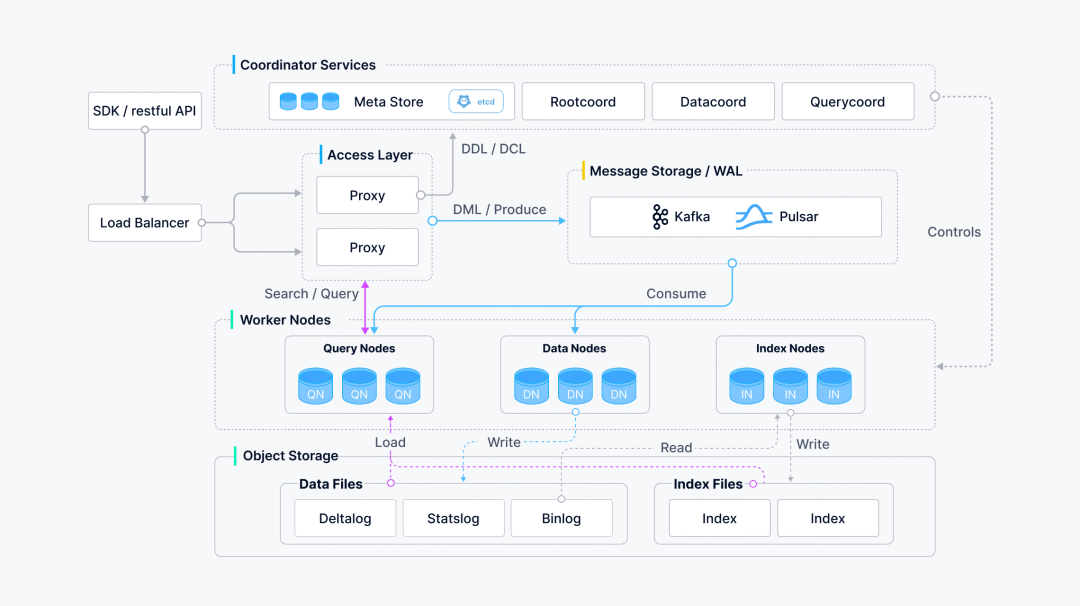
Milvus 2.0 是一款云原生向量数据库,采用存储与计算分离的架构设计,所有组件均为无状态组件,极大地增强了系统弹性和灵活性。整个系统分为四个层面:
● 接入层(Access Layer):系统的门面,由一组无状态 proxy 组成。对外提供用户连接的 endpoint,负责验证客户端请求并合并返回结果。
● 协调服务(Coordinator Service):系统的大脑,负责分配任务给执行节点。协调服务共有四种角色,分别为 root coord、data coord、query coord 和 index coord。
● 执行节点(Worker Node):系统的四肢,负责完成协调服务下发的指令和 proxy 发起的数据操作语言(DML)命令。执行节点分为三种角色,分别为 data node、query node 和 index node。
● 存储服务 (Storage):系统的骨骼,负责 Milvus 数据的持久化,分为元数据存储(meta store)、消息存储(log broker)和对象存储(object storage)三个部分。
(四)Milvus 的应用场景
Milvus 深受全球 1000 多家企业用户的信赖,应用场景丰富多样。
● 图片检索系统:以图搜图,从海量数据库中即时返回与上传图片最相似的图片。
● 视频检索系统:将视频关键帧转化为向量并插入 Milvus,便可检索相似视频,或进行实时视频推荐。
● 分子式检索系统:超高速检索相似化学分子结构、超结构、子结构。
● 音频检索系统:快速检索海量演讲、音乐、音效等音频数据,并返回相似音频。
● 推荐系统:根据用户行为及需求推荐相关信息或商品。
● 智能问答机器人:交互式智能问答机器人可自动为用户答疑解惑。
版本新特性
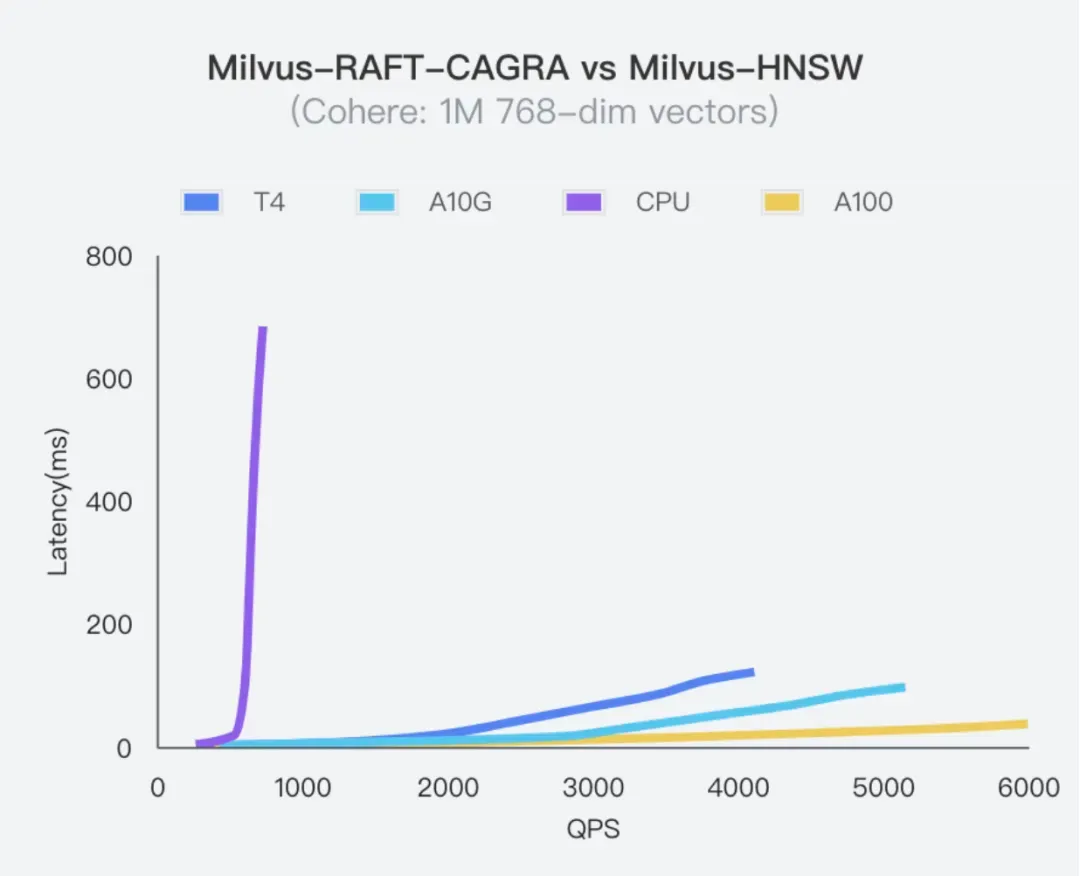
就在4月,Milvus 发布了全新版本 Milvus 2.4。本次发布中,Milvus 新增支持基于 NVIDIA 的 GPU 索引—— CUDA 加速图形索引(CAGRA),突破了现有向量搜索的能力。
GPU 索引是向量数据库技术中的重要里程碑,其速度和性能远超传统的 CPU 索引(如 HNSW)。继 2023 年新增 GPU IVF-Flat 和 GPU IVF-PQ 索引后,又在 Milvus 2.4 版本中进一步增强了 GPU 索引能力。而众所周知,向量搜索速度对于 RAG 应用至关重要。Milvus 2.4 发布后,可以轻松助力用户生成式 AI 应用的开发。
不止如此,Milvus 2.4 还支持多向量检索、Grouping 搜索功能、稀疏向量等。以下是 Milvus 2.4 的几个重要更新:
(一)支持 CAGRA 索引
Milvus 2.4 新增支持 CAGRA 索引,我们要衷心感谢 NVIDIA 团队对 CAGRA 的宝贵贡献,CAGRA 是 NVIDIA RAFT 库中最先进的基于图形处理器的图形索引。与以前只在大批量下获得性能优势的图形处理器索引不同,CAGRA 即使在小批量查询中也表现出压倒性的优势,虽然这是 CPU 索引传统上擅长的领域。此外,CAGRA 在大批量查询和索引构建速度方面的性能确实是无与伦比的。除了 CAGRA,该版本 Milvus 还支持了 GPU 暴搜,性能有数十倍提升,进一步满足需要高召回率的场景。
(二)支持多向量搜索
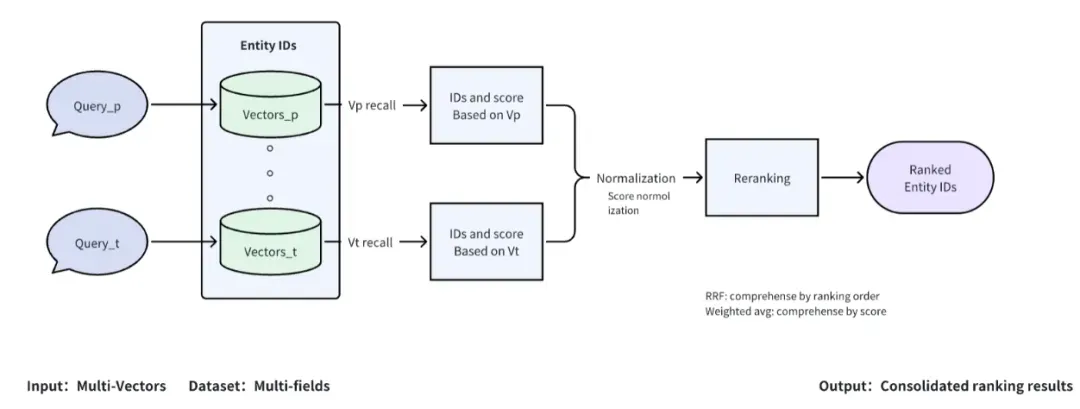
Milvus 2.4 支持多向量搜索,进一步为 AI 应用开发赋能。多向量搜索能力能够有效简化处理多模态搜索的流程,并提升检索召回率。Milvus 2.4 支持在 Collection 中存储和搜索多个向量列,从而满足用户在实际应用场景中的需求。
此外,该特性还简化了整合、优化自定义重排模型的流程,支持开发高级搜索功能,如利用多维度数据输入来做综合搜索的系统。
(三)Grouping 搜索
Milvus 2.4 的新增支持 Grouping 搜索功能,使得用户可以在搜索 vector 的基础上做分组聚合,返回的 TopK 是基于分组后的聚合结果而非简单的以向量为中心的片段信息。用户现在可以按特定标量字段中的值聚合搜索结果,这有助于RAG 应用程序实现文档级召回。考虑一个文档集合,每个文档拆分成各种段落。每个段落由一个向量嵌入表示,属于一个文档。要查找最相关的文档而不是分散段落,可以在 search() 操作中包含 group_by_field 参数,以按文档 ID 对结果进行分组。

(四)支持稀疏向量(beta)
Milvus 2.4 还支持稀疏向量。这一特性专为由 SPLADEv2 等神经模型和 BM25 等统计模型生成的向量设计,通过专注于语义相似性,在传统关键词搜索基础之上,进一步增强了语义搜索能力。具体而言,对稀疏向量的支持,进一步增强了 Milvus 的混合搜索能力——即将关键词搜索和向量搜索相结合,最终提高搜索准确性。当前该功能还处于内测阶段中。
(五)倒排索引和模糊匹配支持
在 Milvus 以前的版本中,基于内存的二进制搜索索引和 Marisa Trie 索引用于标量字段索引。然而,这些方法是内存密集型的。Milvus 2.4 采用了基于 Tantivy 的倒排索引,它可以应用于所有数字和字符串数据类型。这个新索引显著提高了标量查询性能,将字符串中关键字的查询减少了十倍。此版本还支持模糊匹配标量过滤使用前缀,中缀和后缀。
(六)内存映射存储
Milvus 使用内存映射存储(MMap)来优化其内存使用。这种机制不是将文件内容直接加载到内存中,而是将文件内容映射到内存中。这种方法带来了性能下降的权衡。通过在具有 2 个 CPU 和 8 GB RAM 的主机上为 HNSW 索引集合启用 MMap,您可以加载 4 倍以上的数据,性能下降不到 10%。此外,此版本还允许对 MMap 进行动态和细粒度的控制,而无需重新启动 Milvus。
(七)其他优化
Milvus 2.4 还包含其他新特性及功能优化,包括在元数据过滤中支持使用正则表达式对子字符串进行匹配、全新的标量倒排索引(由 Tantivy 贡献)以及用于检测并同步 Milvus Collection 中数据变化的 Change Data Capture 工具。所有上述新特性及功能优化都致力于提升 Milvus 性能和功能,帮助 Milvus 轻松应对更复杂的数据操作。
新特性体验
看到这些 Milvus 2.4 的新功能,我还是有些“手痒”的,很想体验一下多向量搜索的威力。多向量搜索的新特性主要是基于多模态的多向量搜索,本质是用两个不同模态的向量在 Milvus 中进行搜索。比如:先提取人员A的脸部照片向量、声纹向量,然后在 Milvus 中,把人员A的脸部照片向量在众多人员的脸部向量中进行搜索,并且把人员A的声纹向量在众多人员的声纹向量中搜索,最后根据设定的两个模态向量的权重,对两个向量搜索结果重新排序,这样得到的结果,要比单向量搜索的更加准确。
但是我有自己的想法,我想使用一个物品不同角度的照片来生成不同的向量,按照一定的权重排序,最后看看能否使用一张图片,搜索各种角度的向量,来让结果更加准确。说干就干!
1、数据准备
我在某东上手动准备了十双鞋子的照片,每双鞋子的第一张都是俯瞰图,第二张是侧面图且方向一致:
2、代码编写
先创建一个有一个图片路径,且有两个向量的表:
def create_milvus_collection(collection_name, dim):
if utility.has_collection(collection_name):
utility.drop_collection(collection_name)
fields = [
FieldSchema(name='path', dtype=DataType.VARCHAR, description='path to image', max_length=500,
is_primary=True, auto_id=False),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, description='image embedding vectors', dim=dim),
FieldSchema(name='embedding1', dtype=DataType.FLOAT_VECTOR, description='image embedding vectors1', dim=dim)
]
schema = CollectionSchema(fields=fields, description='reverse image search2')
collection = Collection(name=collection_name, schema=schema)
index_params = {
'metric_type': METRIC_TYPE,
'index_type': INDEX_TYPE,
'params': {"nlist": 512}
}
collection.create_index(field_name='embedding', index_params=index_params)
collection.create_index(field_name='embedding1', index_params=index_params)
return collection然后把准备好的数据向量化并插入到创建的表中:
QUERY_SRC = 'photos/test-img'
entities = []
image_pipe = AutoPipes.pipeline('text_image_embedding')
for root, _, dirs in os.walk(QUERY_SRC):
img_list = []
for dir in dirs:
if dir.startswith('.'):
continue
sub_dir = os.path.join(root, dir)
sub_dir = sub_dir.replace('\\', '/')
img_list.append(sub_dir)
if len(img_list) > 0:
print(img_list[0])
print(img_list[1])
print("---------------------------------------")
embedding = image_pipe(img_list[0]).get()[0]
embedding1 = image_pipe(img_list[1]).get()[0]
entity = {
"path": img_list[0],
"embedding": embedding,
"embedding1": embedding1
}
entities.append(entity)
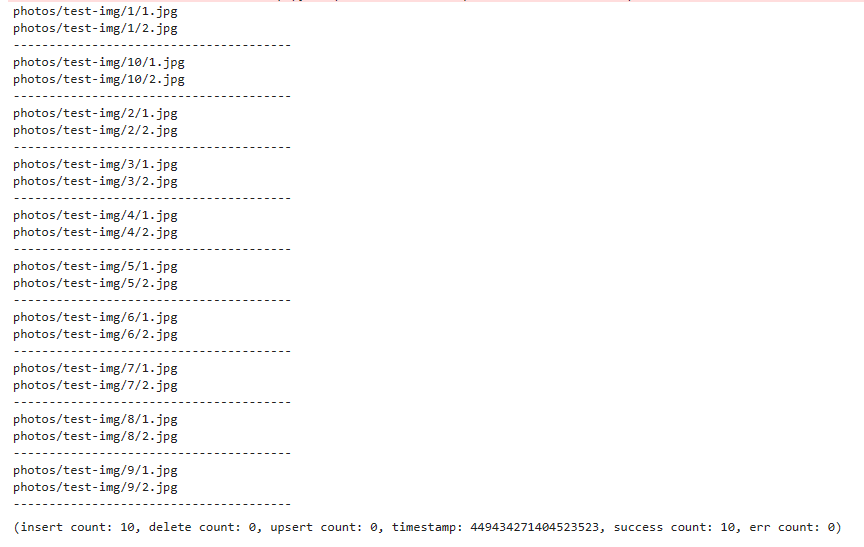
collection.insert(entities)已经全部插入成功:
3、单向量搜索
先用单向量搜索看看结果如何:
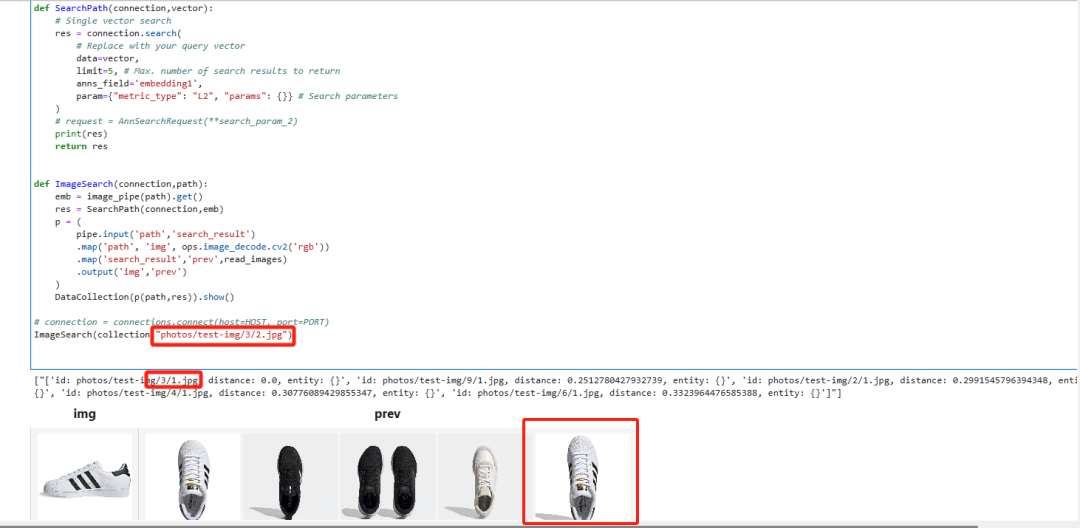
可以在结果中看到,我是用的第三双鞋的侧面照片进行搜索的,结果中第一个就是第三双鞋,说明单向量的准确度已经很高了,但是最后一个图片的相似度也很高,排名却是在最后,说明可能还会有漏网之鱼。
4、多向量搜索
接下来使用多向量搜索看看结果如何:
def get_image_pipe(path1,path2):
emb = image_pipe(path1).get()
search_param_1 = {
"data": emb,
"anns_field": "embedding",
"param": {
"metric_type": "L2",
"params": {"nprobe": 10}
},
"limit": 5
}
request_1 = AnnSearchRequest(**search_param_1)
emb1 = image_pipe(path2).get()
search_param_2 = {
"data": emb1,
"anns_field": "embedding1",
"param": {
"metric_type": "L2",
"params": {"nprobe": 10}
},
"limit": 5
}
request_2 = AnnSearchRequest(**search_param_2)
reqs = [request_1, request_2]
rerank = WeightedRanker(0.6, 0.4)
res = collection.hybrid_search(
reqs,
rerank,
limit=5
)
return res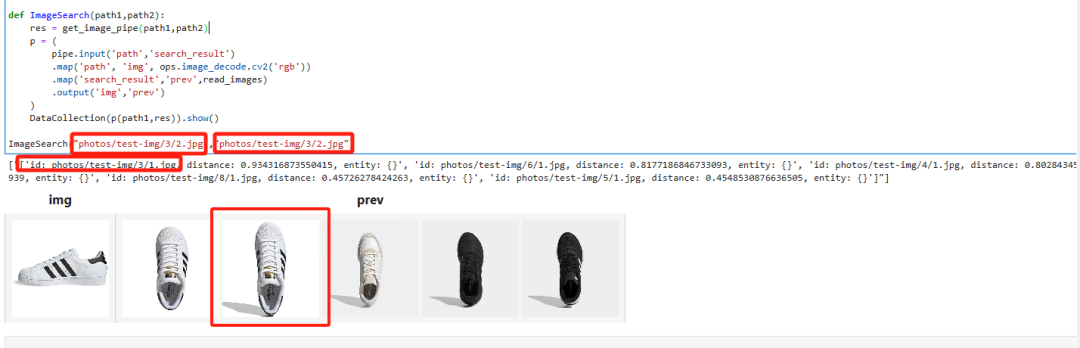
多向量搜索的时候,我使用的还是同一张图片,并且我是用同一张图片在两个向量中搜索的,权重设置的是,第一张照片的向量占60%,第二张照片的向量占40%。这个时候结果比较符合预期了,第一名意料之中的还是第三双鞋。但是相似度非常高的第六双鞋,排名第二了。说明多向量搜索,能弥补单向量搜索的不足,让搜索的结果准确度更高。
社区活动体验
前段时间,Milvus 老友汇·Arch Meetup 在深圳圆满落幕。我有幸参加了本次活动,体验了一下 Milvus 社区的专业和活力。到场签到就可以领取小礼品,好评!活动期间,社区小伙伴们也踊跃发言提问,学习氛围非常好。

本次 Meetup 由 Milvus 社区携手 Shopee 共同举办,举办场地就在 Shopee 的会议室,同时还邀请到来自 AWS、点石科技的技术专家,分享电商行业、RAG 场景、AI 平台等如何基于向量数据库构建业务方案。现场大佬详细的讲解了 Milvus 2.4 的新特性也介绍了 Milvus 以后的发展方向。更有大佬分享了 Milvus 生产架构及其优势。也让我学到了很多新的知识。
未来,我将继续关注 Milvus 的发展,并积极参与 Milvus 社区的活动。我也会深入学习 Milvus 的理论和实践,提高自己的动手能力。
我相信,Milvus 将会在我未来的职业生涯中发挥重要的作用。















 593
593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









