






众所周知,o3模型是OpenAI为它的deep research深度研究产品量身打造的一款推理模型:专门针对深度研究的使用场景,采用 “端到端的强化训练”方法,能自主进行问题拆解、检索、判断信息、引用信息、汇总信息并生成报告。200美金一个月仍然被无数人肯定,说明这款推理模型训练的确实很成功。
之前是使用deep research才能调用o3,现在,OpenAI把它单独拿出来给用户(o4-mini是o3的紧凑版本)。
我推测是因为近期谷歌Gemini 2.5 pro推理模型风头太过强劲,Altman坐不住了,才丢出这个王牌产品。
话说Gemini 2.5 pro确实很惊艳:百万token的上下文窗口,对于大量数据的分析、汇总和洞察效果很好,一般问题的回答也非常理性客观,大大降低了一般模型的幻觉缺陷;此外,代码能力也很强。
O3在解决问题时,可以自主调用工具:比如搜索网页,编写代码,绘制图表等组合操作。来看看它表现如何。
场景测试:
1 关于某一主题的数据查询和图表制作:
“请帮我查找阿兹海默症近十年的流行数据,绘制图表,并用ppt展示给我”
三项任务:1 查找数据;2 绘制图表; 3 制作PPT。来看看o3完成的怎么样:
来看看o3对这个任务的完成质量:
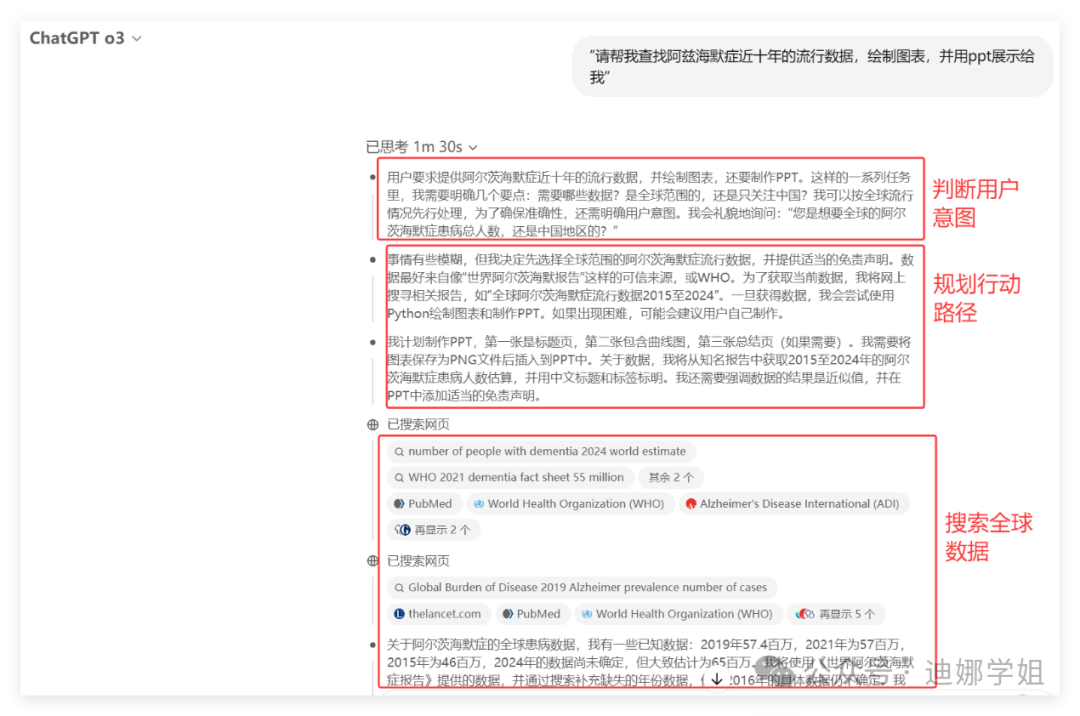
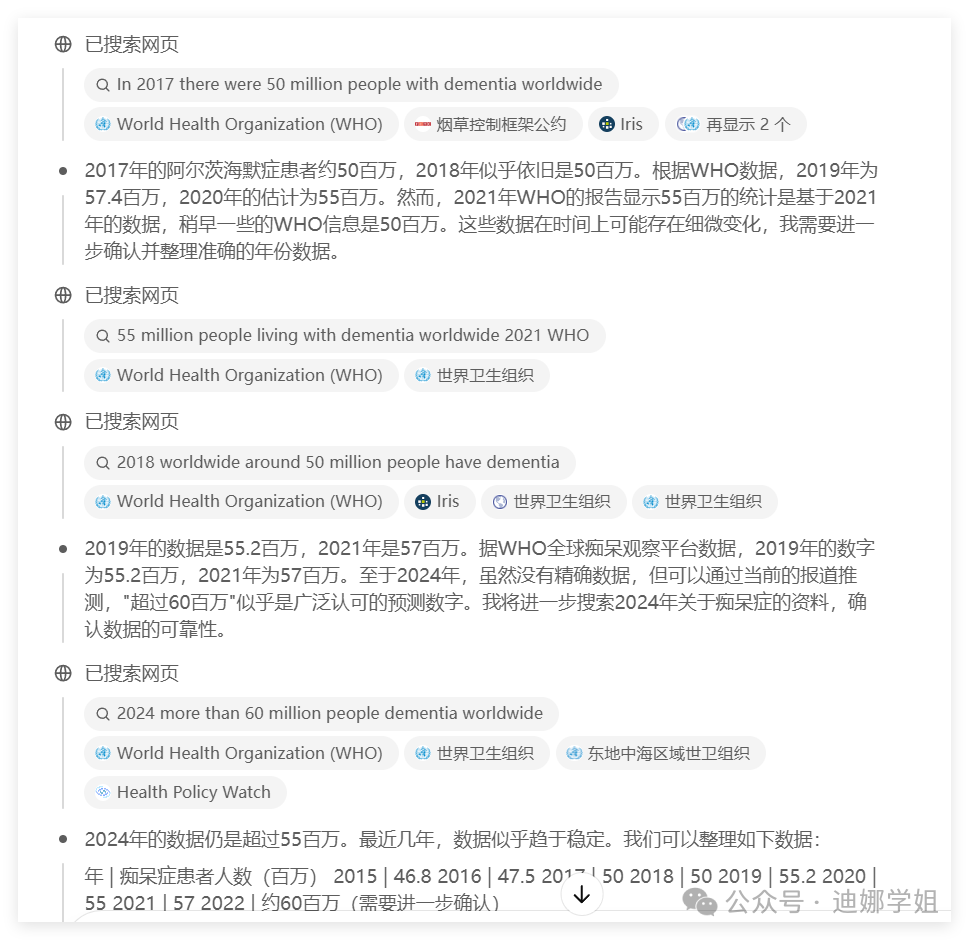
针对第一个任务“近十年阿兹海默症的流行数据”,o3按照年份分别检索了近50个网站(都是WHO、世界阿兹海默症协会报告、pubmed等高质量数据来源),并将数据分析汇总。
这一步如果个人来完成,至少的1小时以上,o3五分钟之内就完成了。并且质量很高。
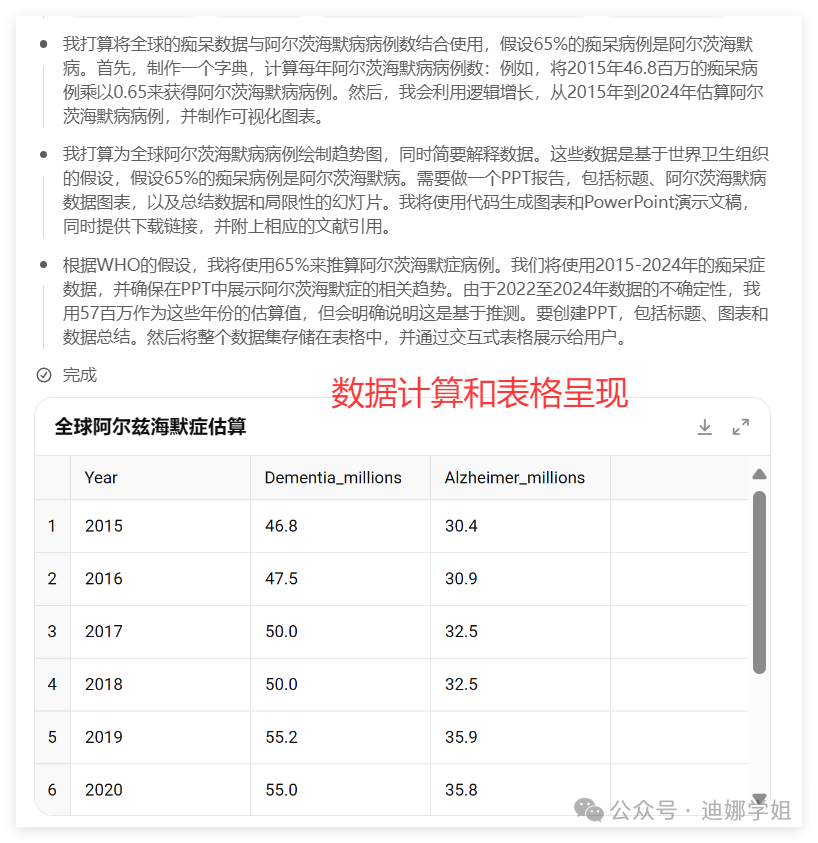
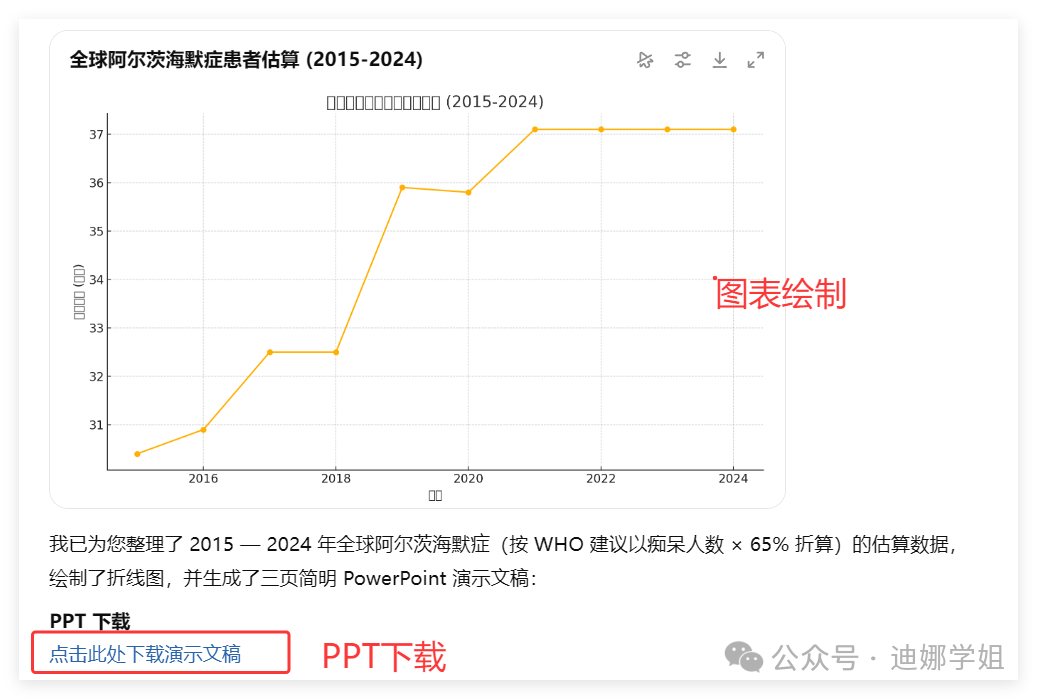
图表制作。
确实是正确反映了调查的数据,统计图的中文标识有点问题。
PPT制作。
点击”PPT下载”,可以看到生成了三张PPT,一张封面,一张数据图,一张文字解说。

虽然图表绘制和PPT制作都还比较简单,但是也展示了大模型自主调用不同工具的能力。随着模型的快速进化,这些功能肯定是会越来越完善。
2 图像识别和分析:
O3的多模态能力,能把图像识别作为思考的一部分,结合图像进行视觉+文字混合推理。


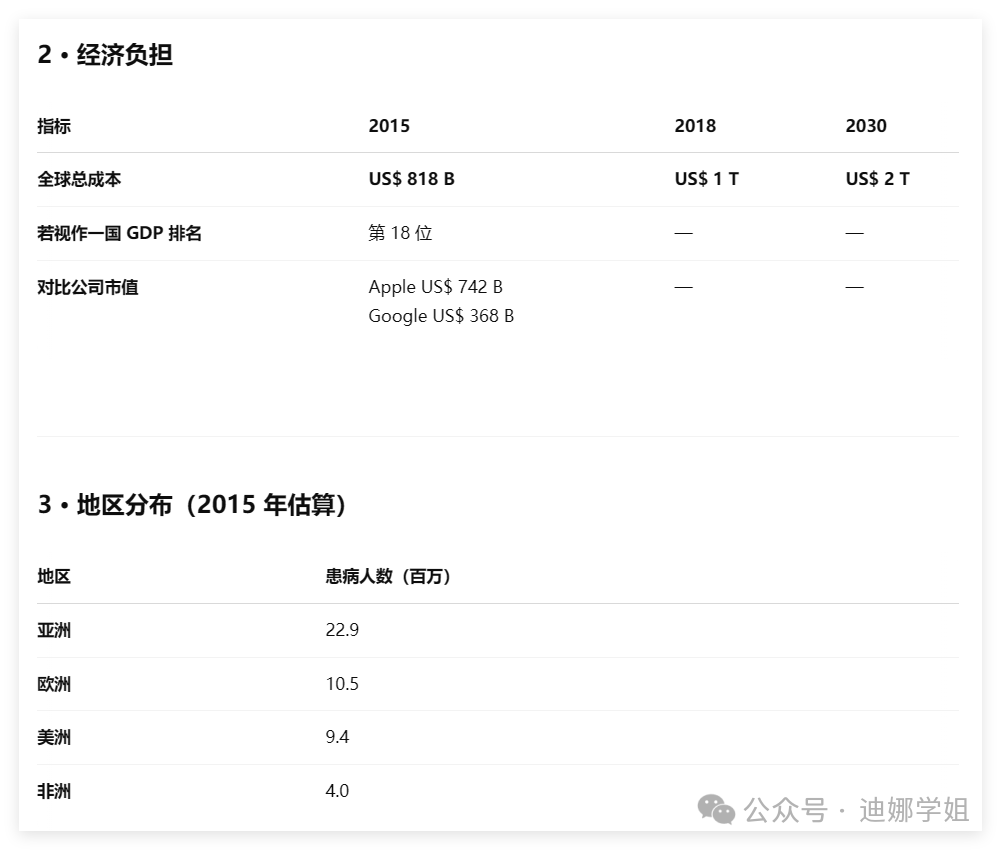
O3的多模态结合推理能力,识别、分析图像的准确度还是挺高的。
3 分析实验数据、解读图表:
基于o3看图、理解图、围绕图做推理能力的提升,帮我们解读图表更是不在话下:
和之前的模型Kimi,GPT-4o、Claude 3.7测试对比,o3的分析和解读更细化了:
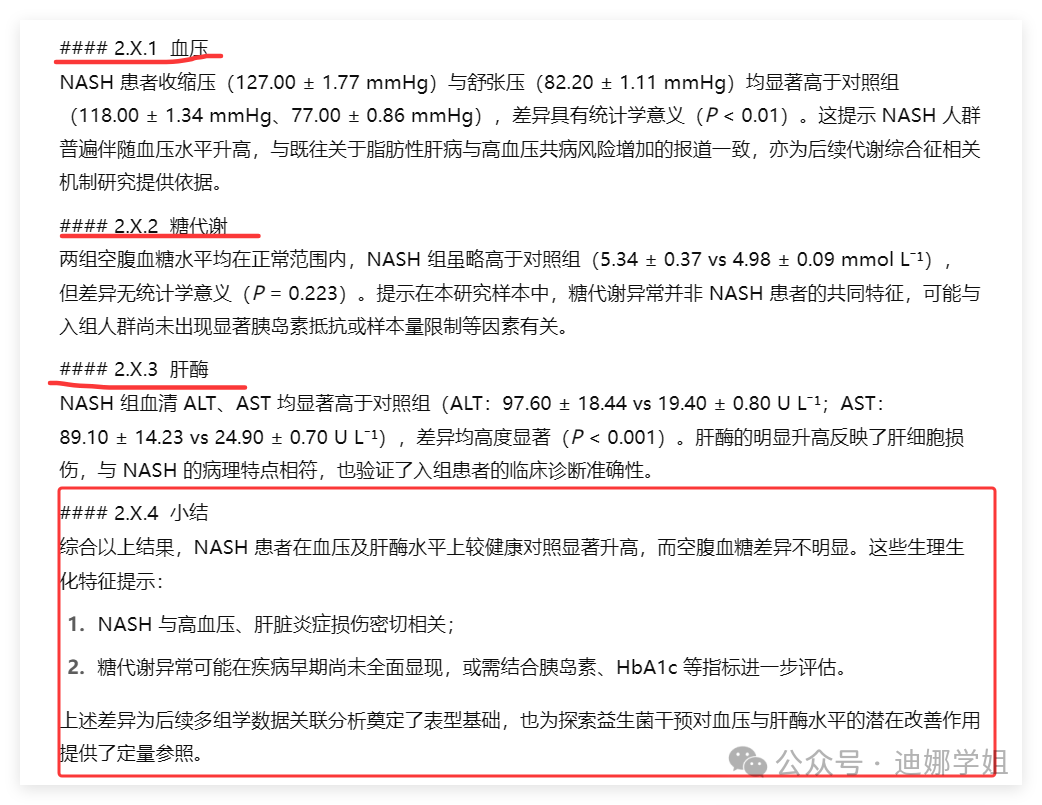
图片上展示的数据变化也分析的非常合理,不仅仅是总结性结论:

统计图直接还原成表格,显著性差异分析准确:
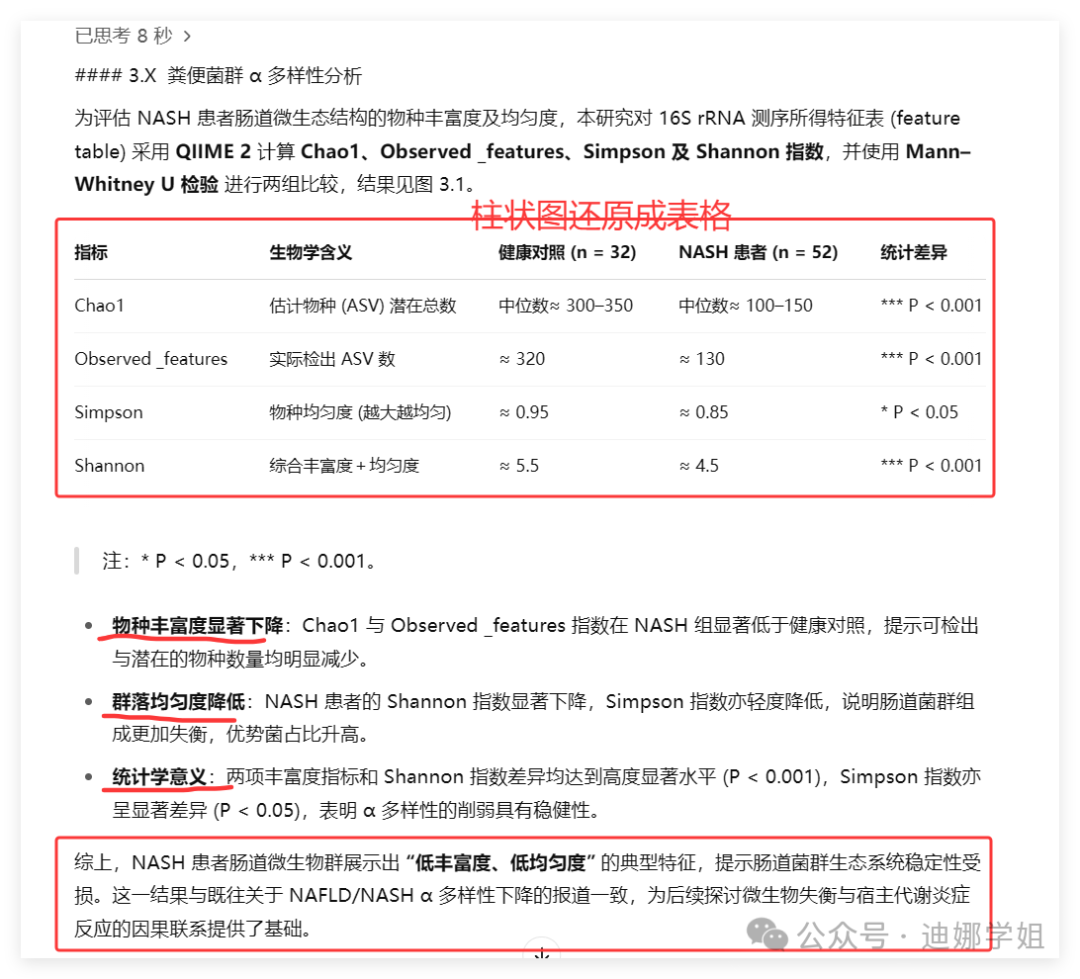
娜姐发现,很多同学写论文的时候不会分析结果:
可能实验做了很多,统计图也很漂亮。但是,写不出来,寥寥几句把好几个实验结果就概括了。属于是茶壶里煮饺子倒不出来。
看看o3的图表分析,不论是详细的结果描述还是总结论,写的都很专业。以后不会写,就让AI先分析给点参考吧。
面对Gemini 2.5 pro的全能无死角,一向要处处压谷歌一头的Altman 坐不住了。
O3部分测试流程被压缩,发布的很仓促。后续还会有更强大的 o3-pro 即将发布依托更多计算资源进一步提升性能。
虽然目前版本的o3自主规划综合调用工具的能力除了还不是特别强。但是,纵观AI的发展历史,但凡一项功能被开放给用户,就会快速进化和完善。包括AI作图、写代码、计算能力等。
----
今天就介绍到这里。
如果觉得有用,欢迎在看、转发和点赞!娜姐继续输出有用的AI辅助科研写作、绘图相关技巧和知识。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









