







开篇
这边本来是打算把维特比算法直接放到HMM那篇博客里面,但是发现自己在复习HMM的时候,对维特比的理解有一定的偏差,时不时会串线到beam search算法上,所以这边具体写一下他们之间的联系和区别。
首先要给出的结论是它们是不同的算法,但是思想上是有联系的
区别
- beam search 的操作属于贪心算法思想,不一定reach到全局最优解。因为考虑到seq2seq的inference阶段的搜索空间过大而导致的搜索效率降低,所以即使是一个相对的局部优解在工程上也是可接受的。
- viterbi属于动态规划思想,保证有最优解。viterbi应用到宽度较小的graph最优寻径是非常favorable的,毕竟,能reach到全局最优为何不用!
seq2seq中,beam search 是为了找出词表所构成的token组合路径。词表所构成的搜索空间是所有可能的输出token,数量非常非常庞大,比如下面的词表:{‘你’,‘说的’,‘是’,‘对的’,‘……’},可以非常长;
hmm中,viterbi是为了找出隐状态所构成的隐状态符号组合路径。隐状态符号表所构成的搜索空间相对是比较窄的。比如是这样的隐状态符号:{‘O’,‘I’,‘B’}。
参考:https://www.zhihu.com/question/54356960/answer/324590737
思想上的联系
它们很像,但是维特比算出来的一定是最优解,由于HMM中的隐藏状态的依赖关系只和前一个状态有关,它每一个时刻的一个状态的最大值都是前一时刻所有状态转移到这一状态的最大值。我画了一个简易的图,希望大家能够理解。
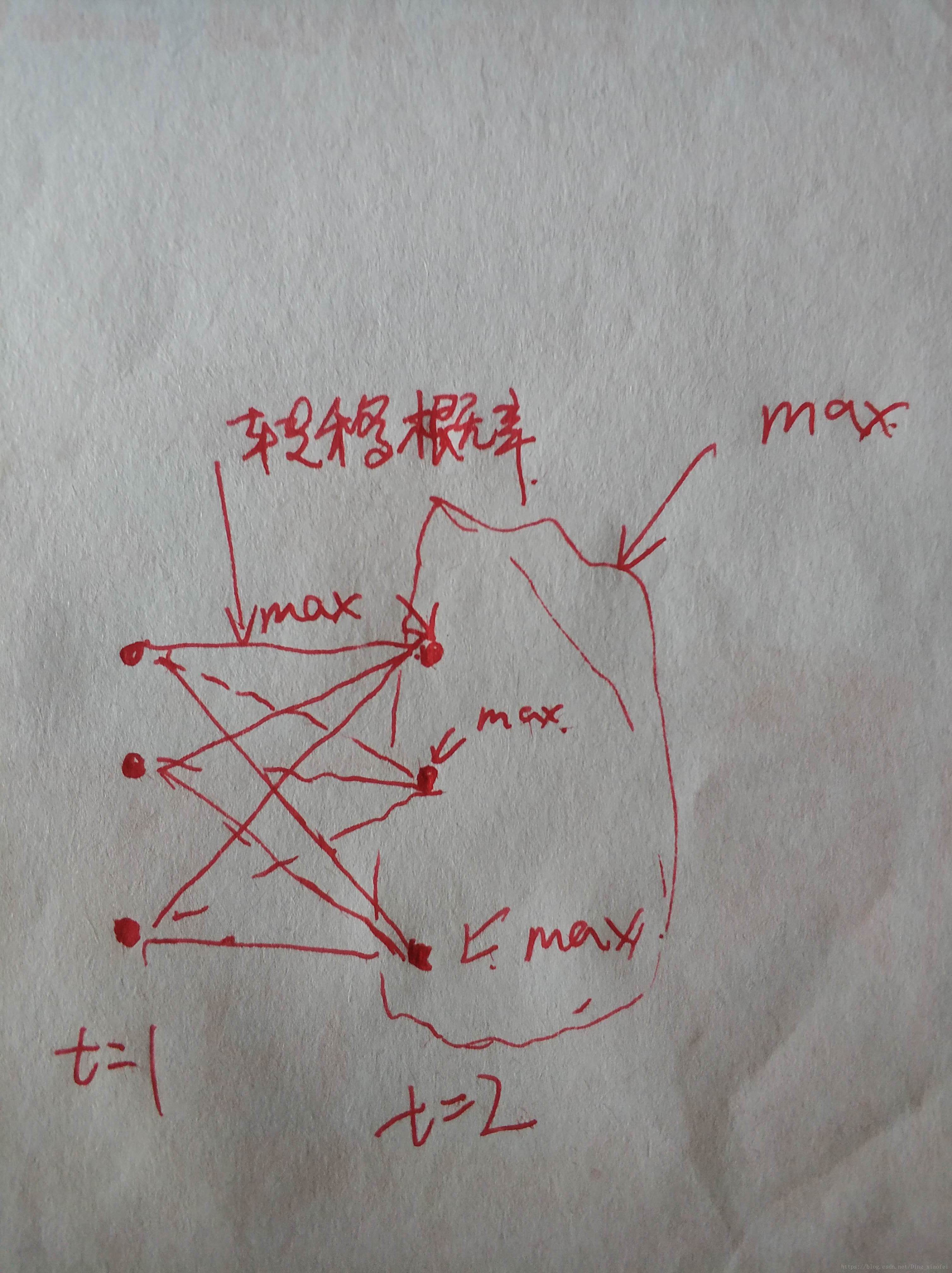
图片上是维特比的图,举个简单的例子,为什么维特比不应用到beam search的场景呢,我们的hmm最长做的一件事情就是pos,词性就是我们的隐藏状态,词性是比较少的,不会像我们nlp任务中的词典,动辄就几十万,我们正常使用的词性就十几个吧。这样我们的隐藏状态转移矩阵维度就会非常的小,使用维特比就能很快的计算出最优解。
ok,我来分析一下这张图,希望能够帮助大家理解维特比算法,最后我会放上维特比的数学表现形式。我们以t2时刻为例,假如我们就算到t2时刻的最佳路径,这边最佳路径是指概率最大的路径。首先我们会计算t2时候每一个状态的最大值,也就是它和前一时刻三个状态的条件概率,我们选择最大的那个条件概率作为这个状态的概率,t2时刻的每一个状态我们都会计算出一个max,最终我们再选一个最大的作为我们的路径终点,我图上画出了所有的路径,其实我们主要保留max路径就可以啦。
再提一下beam search,它做不到计算所有的路径,所以它有一个集束范围k,也就是每次取k条最大的路径继续往下走,当k和词典长度一样的时候,两个算法的本质就是一样的啦,当然前提是它们都是一元依赖关系。
维特比的算法复杂度很高,是幂方级别的。
数学表现形式




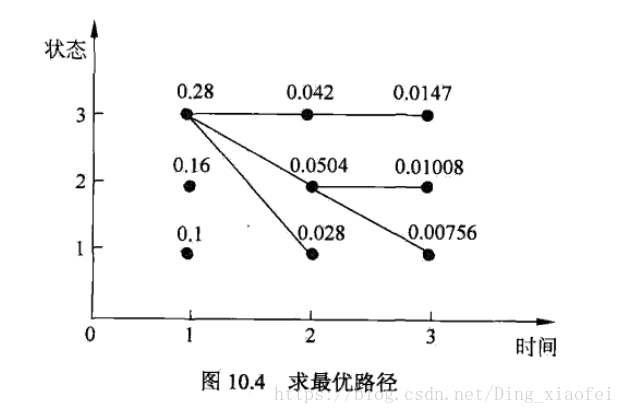
放上只保留最大路径的图














 3945
3945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









