







Gradient Descent with Large Datasets
我们已经知道,得到一个高效的机器学习系统的最好的方式之一是,用一个低偏差(low bias)的学习算法,然后用很多数据来训练它。 下面是一个区分混淆词组的例子:
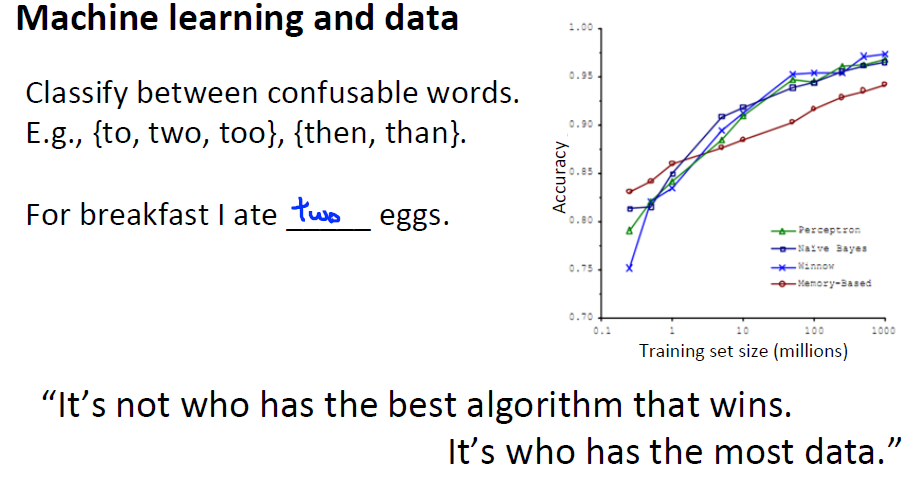
但是,大数据存在一个问题,当样本容量m=1,000时还行,但是当m=100,000,000呢?请看一下梯度下降的更新公式:
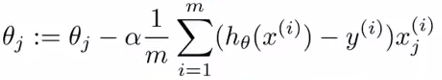
计算一个 θ 值需要对1亿个数据进行求和,计算量显然太大,所以时间消耗肯定也就大了。
当然,这都是建立在低偏差(low bias)的问题上。如果问题本身不是低偏差,那么m取1,000与100,000,000并无多大区别。
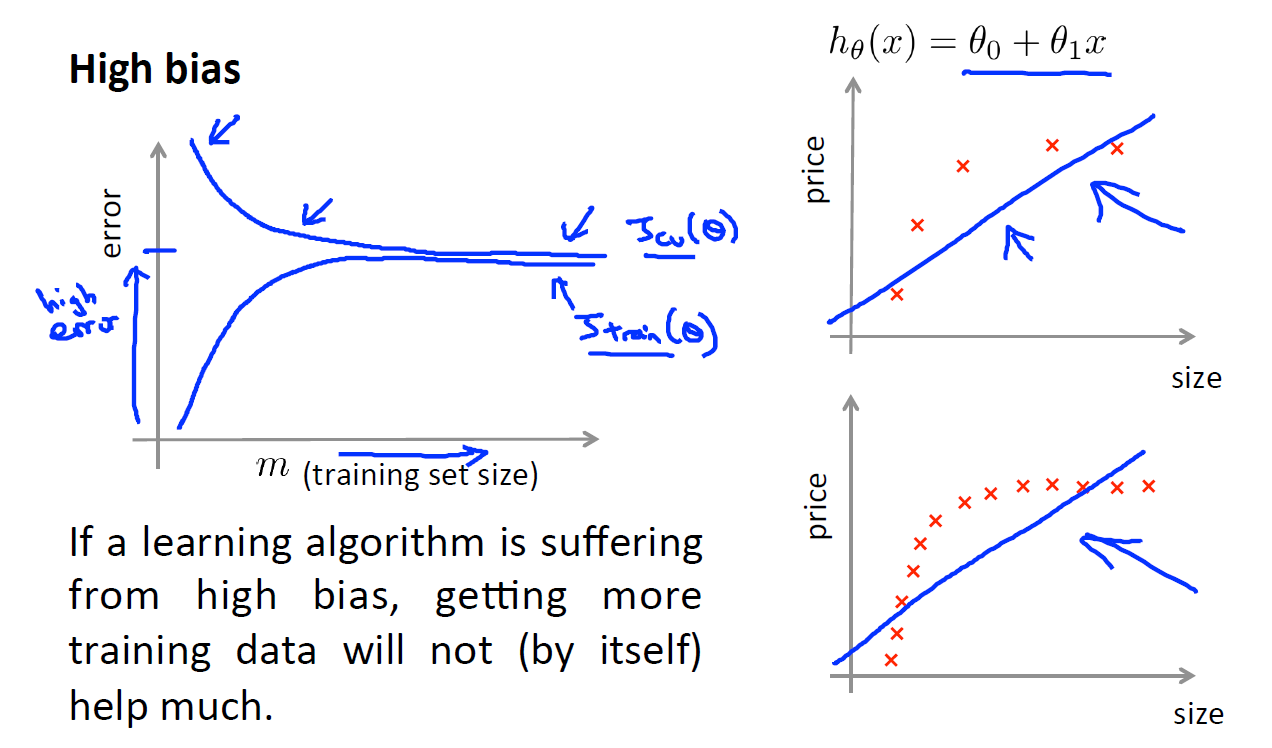
简单回顾一下高偏差(低方差.underfit),高方差(低偏差)的问题:
 |
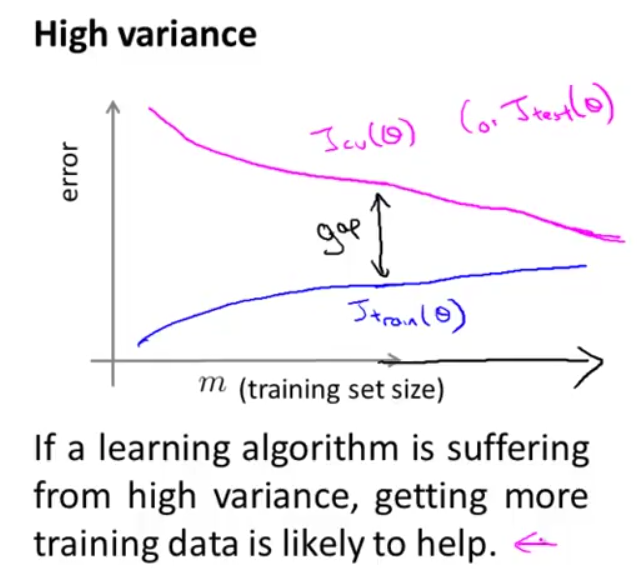 |
我们发现,当学习曲线处于low bias(high variance)状态时,我们可以通过增加样本数量来提高准确度。
先来看线性回归方程的梯度(有时称batch gradient descent,因为需要计算所有数据)求解:
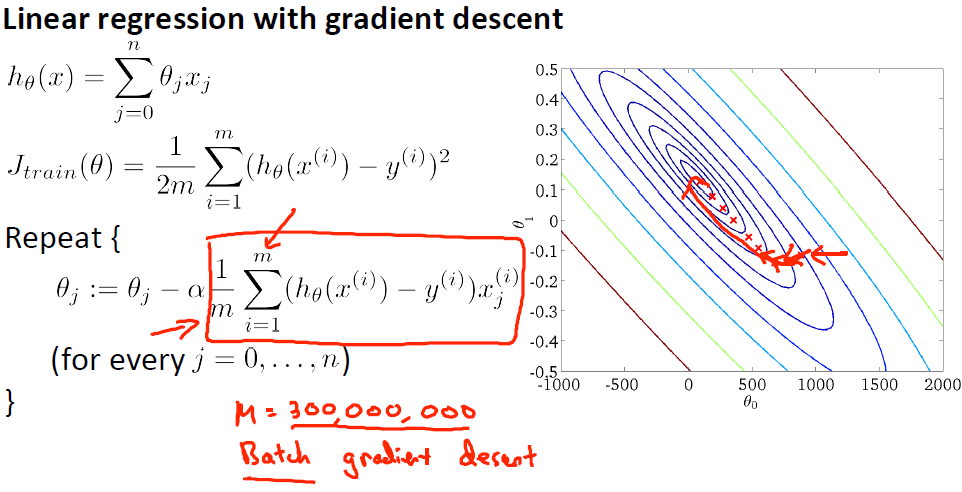
那么在你运行梯度下降的过程中,多步迭代最终会将参数锁定到全局最小值,迭代的轨迹看起来非常快地收敛到全局最小(上图右侧),而梯度下降法的问题是当m值很大时,计算这个微分项的计算量就变得很大,因为需要对所有m个训练样本求和。
由此引入Stochastic Gradient Descent(随机梯度下降算法):
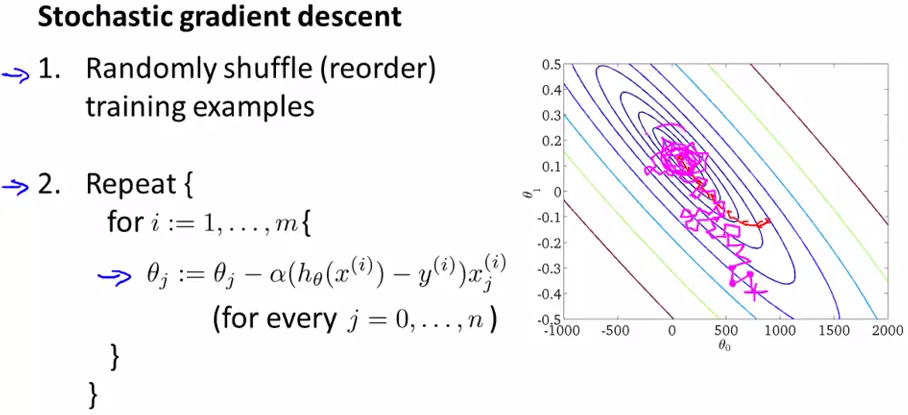
与上述梯度下降算法不同的是,随机梯度下降算法每次 不必关注所有样本,而是对每个样本都进行梯度求解,换句话说,首先对第一组训练样本 x(1),y(1)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 647
647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









