






故事导入
CPU是一家企业的老板,平时不仅要干自己分内的活(比如做做数学题),还要打点公司大大小小的事情。但是悲催的是,为了省钱,他并没有雇一个帮忙跑腿的助理,只有一辆用来送资料的小推车(总线)。(啥?为啥要有小推车?这年头,资料都是一堆一堆的,自己扛根本扛不动)
如果一些**小客户(低优先级外设)一个电话打过来说要点什么资料,他就会让他们等一等,等自己忙完手上的东西就去送;但是如果是大客户(高优先级外设)**可不能得罪啊,CPU就得赶紧放下手中活,亲自推着小推车去送资料。
长此以往,CPU顶不住了,心想:我干嘛为了省这点钱,白白干那么多体力活啊?这工作效率也太低了,而且我整天去给别人送资料,不知道的还以为我就是一个文员呢。不行,我得雇一个跑腿的。
于是,CPU雇了一个叫DMA的跑腿小哥,还把自己的办公室腾出来一小块地方供DMA使用。以后如果有客户打电话来要资料,他就会把客户的信息、要什么资料,从哪里拿,拿到哪里去都告诉跑腿小哥让他去送。小哥一看这资料这么多,搬过去岂不是累死?这时,他想起办公室有一辆小推车,于是就去和CPU申请使用权限。等申请下来后,DMA去跑腿,而CPU就把这省下来的时间用来干其他更重要的事情,比如做数学题哈哈。
自从DMA开始接手跑腿工作后,CPU轻松多了,公司的经营状况也越来越好了。CPU心想,我早干嘛去了……
背景
在没有DMA技术出现以前,外部设备(比如打印机)想要想要从存储器中读取信息需要经过下图的步骤:
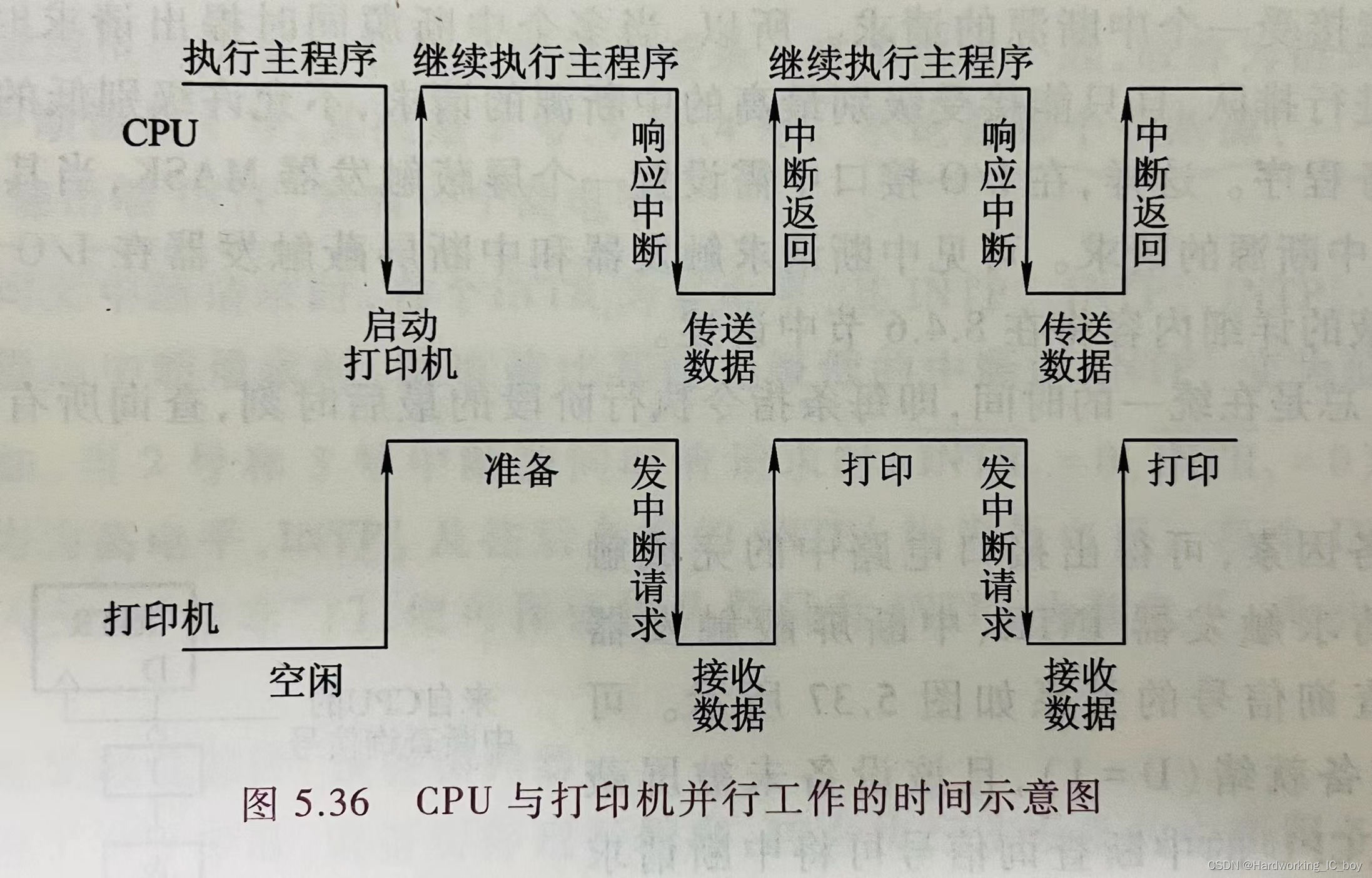
1、没有外设请求时,CPU执行主程序。
2、打印机 (外设) 要接收数据时,都得先向CPU发送中断请求。待CPU响应中断后,就会从存储器中将数据传输到打印机。而这段时间里,可以看到CPU需要停止执行主程序来传输数据,大量占用了CPU花在执行主程序(比如高性能计算等)上的时间。
3、所以,如果有很多的外设一直跟请求接收数据,结果就是,低优先级的外设等很久都没有响应,而高优先级的外设如果一直请求,那么CPU就需要经常停下手中的活来传输数据,会导致效率低下。
因此我们就需要给CPU请一个跑腿,让他来帮忙搬运数据,从而解放CPU。CPU需要做的就是给这个跑腿交代一些信息(从哪里拿,拿多少,搬去哪里等),并且赋予他实权去占用总线进行跑腿工作,传输数据,最后再收尾一下就好了(看还需不需要继续跑腿,需要的话就告诉他相关信息)。
而这个跑腿就是接下来要登场的DMA小哥。
概念及作用
DMA, Direct Memory Access,叫直接存储器访问。这里的这个“直接”指的是可以不用CPU的干预,直接访问存储器的意思。具体就是用来提供在外设和存储器之间、存储器与存储器之间或者外设和外设之间的高速数据传输,从而减轻CPU的负担。
注意,前面提到的中断响应方式是通过软件进行的,而DMA则是一个硬件,是一块独立的芯片,叫协处理器DMAC。他主要就是用于数据传输控制的。
双面性
对于CPU来说,DMA就是个普通的外设,是个slave,只是负责跑腿而已;
但是这个外设背靠着CPU这个大老板,还是有那么权力的。所以对于普通的外设而言,DMA就是master的角色。
分类
DMA可以分为自带DMA和公用DMA。对于一些比较大的IP,会自带DMA功能;而向SPI、UART等小IP,基本使用公用的DMA。
DMA传输过程
一个完整的DMA传输过程必须经过DMA请求、DMA响应、DMA传输、DMA结束4个步骤。
请求
外设发起请求,告诉CPU说要进行数据传输(此时DMA是不知道的)。CPU需要对DMA进行配置,也就是告诉DMA是读还是写、从哪里,拿多少数据,传到哪儿去。CPU完成对DMA的配置后,就继续执行原来的程序去了。
具体的预置信息如下:
- 给DMA控制逻辑指明数据传输的方向是输入(写主存)还是输出(读主存)
- 给DMA设备地址寄存器送入设备号,并启动设备。
- 向DMA主存地址寄存器送入交换数据的主存起始地址。
- 对字计数器赋予交换数据的个数
当外设准备好发送的数据(输入)或者上次接收的数据已经处理完毕(输出)时,它便向DMA接口发送请求,让DMA去向CPU提出占用总线的申请。
若有多个DMA同时申请,则按照优先级排序。
响应
DMA控制器收到请求后,向CPU发起总线控制权的请求,等待CPU的响应。当CPU响应之后,便把总线(包括地址、数据和控制)的控制权交给DMA。
传输
以数据从存储器传输到外设为例。接管总线控制权后,DMA通过总线从存储器中取数据,然后发送给外部设备。至于这个数据是先在DMA里缓存一下再发送给外设还是直接发送给外设,就得具体看DMA工作模式了。
结束
结束传输后,DMA向CPU发起中断请求,将总线控制权还给CPU。CPU响应DMA的请求时,会停止原程序的执行,做一些DMA的后处理。包括:
- 校验送入主存的数据是否正确
- 决定是否继续用DMA传送其他数据块。如是,就对DMA接口进行初始化。否则就停止外设
- 测试在传送过程中是否发生错误,若是,则转错误诊断及处理错误程序。
DMA工作模式
FIFO模式
FIFO模式下,可以将要传输的多个数据存储在FIFO缓冲器中,当达到了阈值后,就自动把存储的数据一次性发到目标地址。
直接模式
一般外设内部也有FIFO,所以DMA也可以直接将数据从源地址传输到目标地址。
CPU vs DMA
我们前面说到,DMA就是给CPU当跑腿的。而他们又只有一个小推车(总线)。那么如果有一天DMA和CPU同时都要用到这个小推车,那么谁可以先用咧?其实反而是DMA的优先级高一些。因为他跑腿的都是一些比较着急的单(高速外设),所以反而会把小推车先让给他用。
具体可以细分为以下三种情况:
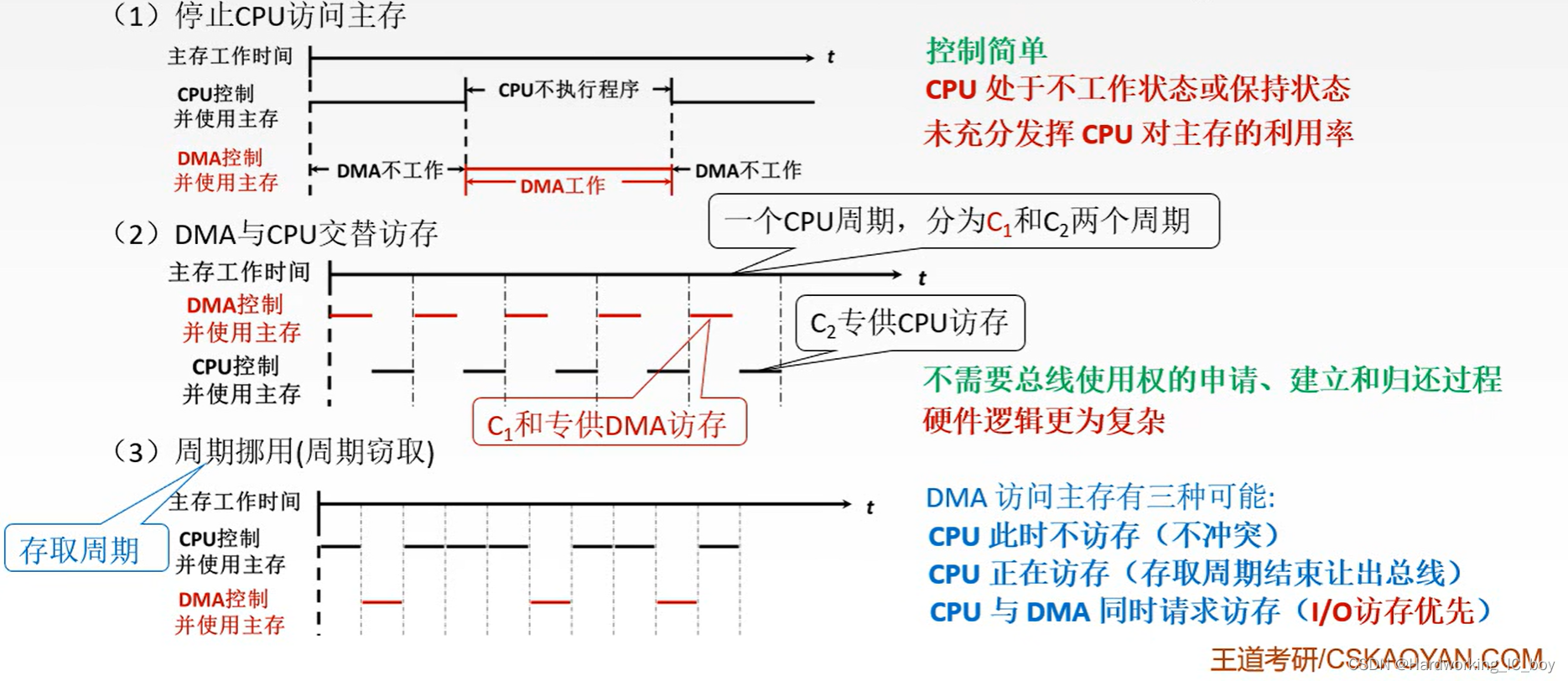
1、停止CPU访问主存
当客户(外设)要求传送一批数据时,DMA跑腿小哥会向CPU发送停止信号,要求CPU把小推车(总线)交出来。之后DMA小哥用小推车运送数据。结束后,就把小推车还给CPU(交还总线控制权)。
优点:控制简单
缺点:DMA在访问主存时,CPU基本上不工作或者保持原状态,未充分发挥CPU对主存的利用率
2、DMA与CPU交替访存
CPU可以把自己的工作情况分为两种,一种是需要亲自用小推车去送资料的业务,另一种是其他业务。在CPU进行其他业务时,就可以把小推车交给DMA,让DMA去搬运资料。
这种方法适用于CPU的工作周期比主存存取周期长的情况。例如,CPU的工作周期为1.2us,主存的存取周期小于0.6us,那么可以将一个CPU周期分为C1和C2两个分周期,其中C1专供DMA访存,C2专供CPU访存。
优点:不需要总线使用权的申请、建立和归还过程。CPU既不需要停止主程序的运行也不进入等待状态,即完成了DMA的数据传送。
缺点:硬件逻辑更为复杂,也就是把CPU访存和不访存的硬件部分分开;而且CPU和DMA访存可能并不均匀,所以在分配主存利用的时候可能效率也不是那么高。
3、(存取)周期挪用(窃取)
外设请求DMA传送会有三种情况:
1、此时CPU不需要访问主存(比如CPU在做乘法,时间比较长,不用访存),此时不冲突
2、此时如果CPU正在访存,就必须等存取周期结束后,CPU才能让出总线占有权。就是说,得等CPU用完小推车把数据送完了,才能够腾出小推车来。
3、如果DMA和CPU同时要求访问主存,就产生了冲突。此时DMA的优先级比较高,先占用总线。因为DMA服务的外设多为高速外设,如果DMA需要访存了,说明数据缓冲寄存器被写满了,如果不及时访存,高速外设传输来的数据就会对先前的数据产生覆盖。
这时,DMA要窃取一两个存取周期,也就是CPU在执行访问主存指令过程中插入了DMA请求,并挪用了一两个存取周期,使CPU延缓了一两个存取周期再访问主存。
就是说,DMA和CPU同时要用小推车时,因为DMA服务的客户比较急,所以一般情况下都先让DMA用,用完了再给CPU。
第三种方式既实现了与外设的数据传送,又较好地发挥了主存与CPU的效率,是一种广泛采用的方法。
Q&A
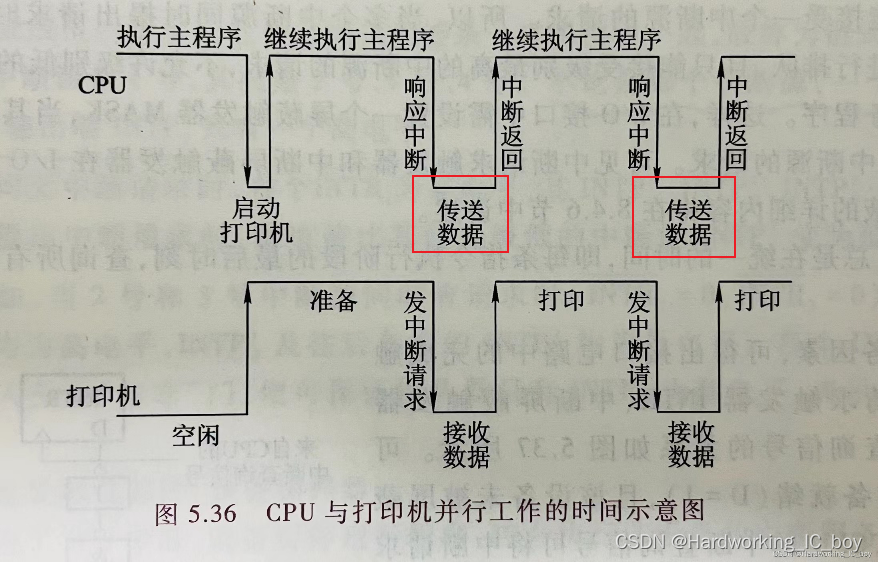
1、DMA不是一样会占用总线吗?总线被占用了那CPU不也没法干活吗?怎么就说可以并行节约时间了?
其实,这里提到的节约时间,指的是把下方标出的红框里的时间。没有DMA时,传输数据的阶段CPU就没法去干其他更重要的事情,比如高性能计算等。而有了DMA后,CPU就只需要进行DMA初始化以及完成时的后处理即可。在总线被DMA占用做数据传输的阶段,CPU就可以进行一些内部的高性能计算(比如乘法等,不需要总线),所以说可以并行运行,节约时间。
2、外设是要跟谁提请求?是直接告诉CPU传输的信息(地址、方向等),CPU再告诉DMA让他去搬运数据?还是说要先通过DMA去告诉CPU?
唐朔飞的《计算机组成原理》第3版的205页提到
在DMA接口开始工作之前,CPU必须给它预置如下信息。
- 给DMA控制逻辑指明数据传输的方向是输入(写主存)还是输出(读主存)
- 给DMA设备地址寄存器送入设备号,并启动设备。
- 向DMA主存地址寄存器送入交换数据的主存起始地址。
- 对字计数器赋予交换数据的个数
所以其实都要。外设一共会发送两次请求。
- 第一次是向CPU请求,让CPU先去初始化DMA;
- 第二次是向DMA提请求,让DMA去向CPU提出占用总线的申请。当外设准备好发送的数据(输入)或者上次接收的数据已经处理完毕(输出)时,它便向DMA接口发送请求,让DMA去向CPU申请总线占用,并传输数据。
DMA设计详解
下面用一个实际的例子来介绍DMA。
DMA系统架构
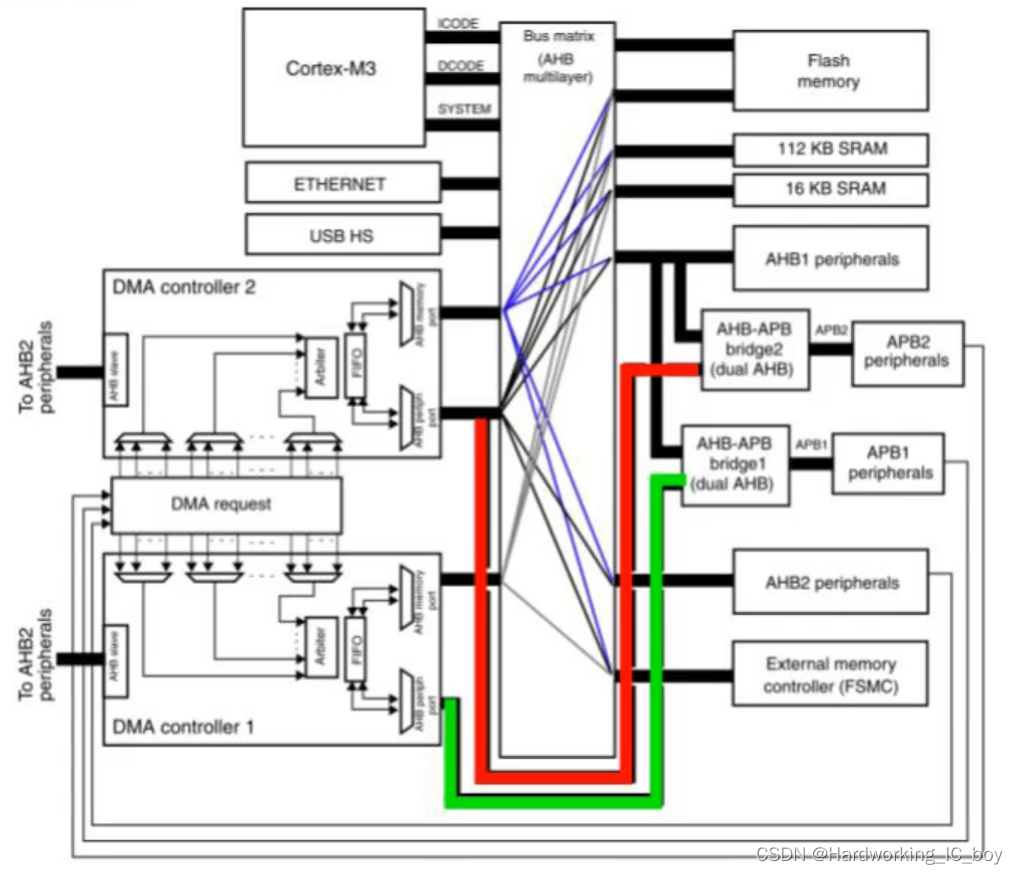
介绍
- 左边部分是master,包括Cortex-M3核,以太网、USB HS和两个 DMA控制器;其中DMA controller 2有两个master端口都连到了bus matrix上,而其中一个端口也可以绕过bus matrix直接连接到AHB-APB桥2上(红线),从而连接APB2外设;而DMA controller 1只有一个master端口连到bus matrix上,另一个绕过bus matrix直接连接到AHB-APB桥1上(绿线),从而连接APB2外设。
- 右边部分是slave,包括一些内存、以及AHB1/2 外设、AHB-APB桥1/2、APB1/2、FSMC扩展外设
- 位于中间的是bus matrix,里面的实线是master和slave之间的通道。bus matrix中的连线,说明了DMA可以访问到Flash、SRAM等,从而进行读写操作;DMA controller 1的上端口只连接到Flash、SRAM等关于memory的外设
Q&A:
1、DMA与CPU如何竞争总线
- 两路DMA、CPU都是bus matrix的master
- DMA和CPU同时访问同一slave时, bus matrix的内部仲裁器会对请求进行仲裁
- DMA和CPU同时访问不同slave时,可以同时工作
2、为什么使用两个DMA?
- 一个DMA的通道数是有限的,因此连接的外设也是有限的,两路DMA可以连接更多的外设DMA请求源
- 两路DMA,在内存、外设的访问空间上做一定区分,可以同时工作,提高效率
3、两个DMA会不会发生竞争?
- 看情况,如果两个DMA连接到同一个外设,比如memory,那么就会产生竞争,此时需要bus matrix进行仲裁
- 如果连接到不同的外设,比如一个连memory一个连AHB2,那就不会
4、同样是DMA,DMA1和2的应用区别?
- DMA2的master端口可以访问总线矩阵的所有slave,包括存储器、AHB1、AHB2、APB1、APB2,因此可以实现存储器、AHB1、AHB2、APB1、APB之间的数据的相互传输
- DMA1的端口1只连接了存储器属性的slave,端口2直接连接到了APB1,只能实现存储器和APB1之间的数据传输;绿线没有经过bus matrix,访问速度快,而且也可以减轻bus matrix的负担,提高效率
5、DMA1为什么只有1个master口连在矩阵上?
- (分工合作)同一个DMA有多个master接口,master功能不同,所映射的地址范围不同,各个端口可以分开操作不同的外设,提高性能
- (加快速度)绕开bus matrix的仲裁而直接连到外设的AHB2APB桥,可以加快对外设的访问速度(注意,DMA 2直接连AHB-APB bridge2,而DMA 1直接连AHB-APB bridge1)
- (降低总线矩阵复杂性)减少连接到bus matrix的master接口数量,降低矩阵复杂性,有利于提高系统效率
ref
- 【芯片通识】04. 芯片中的捷径–DMA功能
- 王道计算机考研 计算机组成原理
- DMA设计详解 - 极术社区
- 《计算机组成原理》第3版 唐朔飞


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











