







1.基础知识
1.1编译器和硬件对程序的优化
1.1.1指令重排序
int i = 0; //语句1
bool flag = false; //语句2
i = 1; //语句3
flag = true; //语句4
优化后可能变成 1324
1.1.2指令合并
int i = 0; //语句1
i = 1; //语句2
i = true; //语句3
优化后 2 3 变为一条语句 i = true
1.2缓存优化
多线程模式下,一个CPU,且CPU有多核,每个核都至少有一个L1 cache。多个线程访问进程中的某个共享内存,且这多个线程分别在不同的核心上执行,则每个核心都会在各自的caehe中保留一份共享内存的缓冲。由于多核可以做到真并行,可能会出现多个线程同时写各自的cache,
因此CPU有“缓存一致性”原则,即每个处理器(核)都会通过嗅探在总线上传播的数据来检查自己的缓存值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器(核)。因此,我们经常看到在多核多线程的场景下,在声明变量时候使用volatile,volatile变量要求在更新了缓存之后立即写入到系统内存,而非volatile变量,则是CPU修改缓存,缓存在适当的时候将缓存数据写入内存。写入内存的操作会出发其他处理器(核)将自己已经缓存的那块正在被写入的内存失效,并在下次需要使用到该内存的时候重新从内存读取。
编译器优化和CPU缓存都加快了单线程模式下执行效率,但是也导致了多线程模型程序执行的"迷惑行为"。
1.3指令执行过程
例如:MOV A,#0E0H (0000H 地址数据+1)
加载 指令到寄存器
读取0000H到累加寄存器
累加寄存器执行+1
回写到内存/寄存器
一条指令会分N次执行。所以指令的操作并不是原子的。
2.volatile
volatile阻止编译器对变量,并且每次store 时从内存中读取。这样volatile 可保证顺序性和可见性,但是没办法保证原子性。
3.锁
加锁的本质其实就是用一个变量lock=1表示未加锁,lock=0表示加锁。
if(lock == 1){
lock = 0 //加锁
//访问互斥区
lock = 1 //解锁
}
这里有两个问题:
1.单核处理器,当A线程执行了if(lock == 1) 还没有执行lock = 0,这时产生时钟中断,系统调度到另外一个线程B,B也通过了if(lock == 1)的判断,这样导致了A B同时访问互斥资源。
2.多核处理器上并行两个线程同样的问题。
那么有没有一种机制可以保证,处理器访问一个变量时其他处理器不能访问这个变量(可见性),并且这个操作时不可被打断的。只是用软件手段不可能实现,所以需要硬件的支持。硬件为我们提供了CMPXCHG原子操作(原子操作的赋值等)和总线锁。
总线锁:
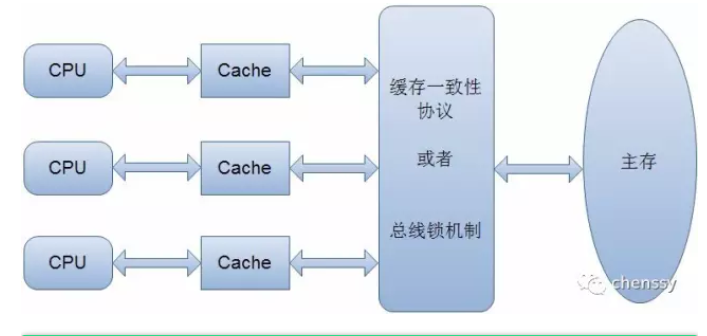
总线锁切断了处理器与内存之间的通道,可以让某个处理器独享某个变量的内存。
3.1原子指令
在并发环境下,要保证共享资源的原子性、顺序性、可见性。所以这个功能由硬件提供。硬件层面上实现原子指令,并且保证其顺序性和可见性。
原子指令:
testandset:t = load(x) if(t == 0) store(x,t) 原子操作 不可被打断
3.2 自旋锁 互斥锁
3.2.1 自旋锁
int lock = 1;
int spin_lock(lock){
//总线加锁
while(!CMPXCHG(lock,1,0)){
}
//总线解锁
}
3.2.1 互斥锁
mutex_lock(mutex) {
//总线加锁
mutex = mutex - 1;
if(mutex != 0)
block()
else
success
//总线解锁
}
3.2 常见并发BUG
死锁( AA ABBA)
if(mutex != 0)
block()
else
success
//总线解锁
}
## 3.2 常见并发BUG
死锁( AA ABBA)
有资源竞争但是忘记加锁 导致原子性违反 顺序性违反















 101
101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









