






想想吴恩达讲的CV里面,复用其他网络的结构,只在最后一层加入一个全连接层,对这个全连接层进行微调,也就是如下过程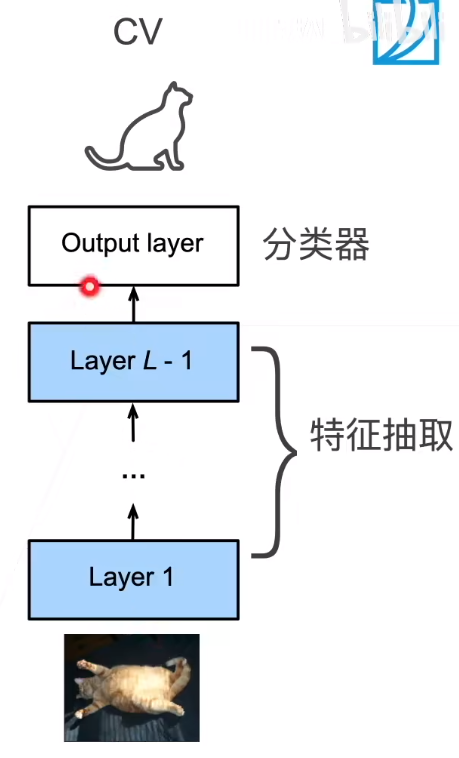
那么CV里面可以这么用,NLP里面当然也可以这么用,如下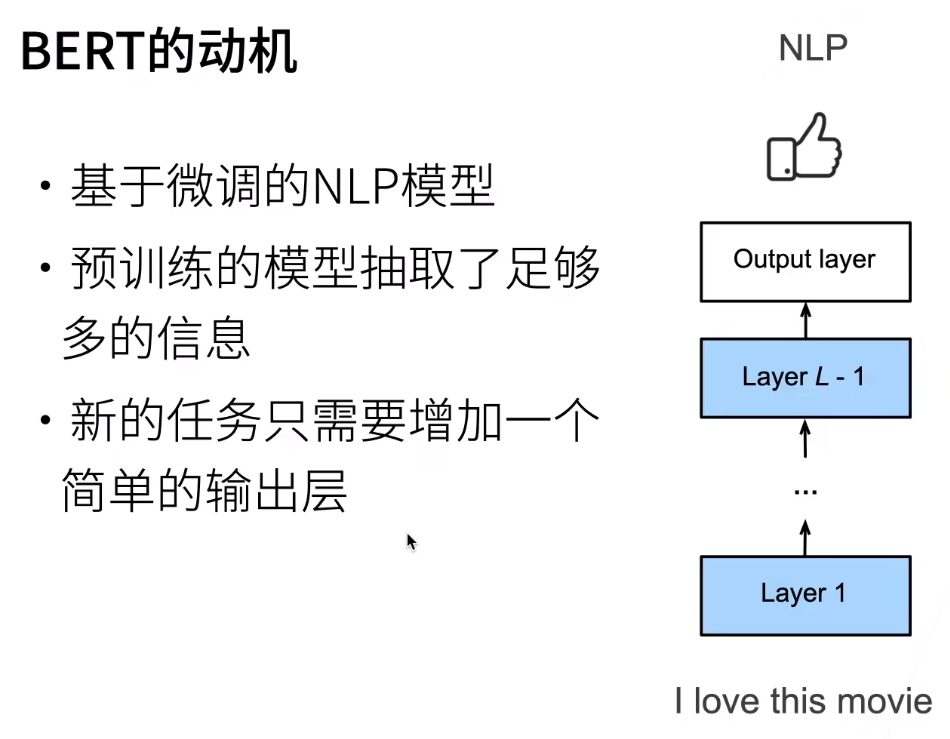
我们只需要调整这个新增加的简单输出层即可
BERT说白了,就是只有编码器的Transformer
他有两个版本,见下
blocks就是Transformer的EncoderBlock
现在考虑BERT的输入。一般来说NLP里面的输入都是成对的,比如机器翻译,有一个源句子还有一个目标句子。那么这里如何让输入是两个句子呢?我们只用拼接起来就好了,如下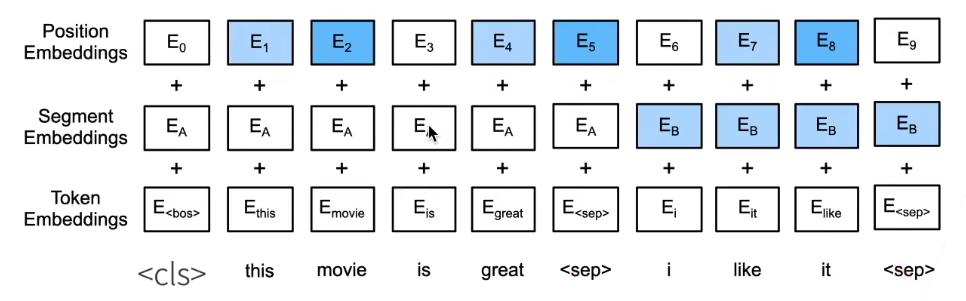
<cls>表示classification,sep表示句子分隔符(separation);Segment Embeddings就是用来区分词元来自哪个句子的
当然其实我们可以连接三个句子或更长,但是一般不这么做
BERT的任务是构建一个通用的模型,那么在NLP里面,语言模型(看一些词,预测下一个词)显然是最通用的,所以我们将BERT训练成一个语言模型,即带掩码的语言模型。但是Transformer是双向的,而语言模型是单向的,这显然就不能直接训练,于是这就是我们带掩码的原因。<mask>就是我们要填写的词,相当于完形填空,此时就不是预测未来了,所以看双向信息是没问题的
那么书上的<mask>那一段到底是为什么要这么换呢?
在BERT的掩蔽语言模型训练中,“要预测一个掩蔽词元而不使用标签作弊”指的是:
如果直接将被掩盖的词元保留在输入中(例如,输入是原句“this movie is great”,而标签是“great”),模型可能会直接“偷看”输入中的原词元来预测,而非真正学习上下文关系。这种依赖输入中的原始词元信息的行为称为“标签作弊”。
为了避免这种情况,BERT采用以下方法:
- 始终用“<mask>”替换被掩盖的词元(如将“great”替换为“this movie is <mask>”)。
- 此时,输入中不再包含被掩盖词元的原始信息,迫使模型必须通过双向上下文(如“this movie is”和周围词元)来推断被掩盖的词元。
但为了避免模型过度依赖“<mask>”标记(因为实际下游任务中不会有“<mask>”),BERT进一步引入:
- 80%时间用“<mask>”
- 10%时间用随机词元(如“this movie is drink”)
- 10%时间保留原词元(如“this movie is great”)
这种策略既防止了标签作弊(通过掩盖原词元),又通过随机噪声增强了模型的鲁棒性,使其更专注于上下文推理而非标记本身。
注意,在BERT引入的三种方法中,无论是哪种方法,模型始终都知道要预测的词的位置(比如上文举的例子的三种情况,模型知道预测的词分别是<mask>,drink和great)
那么除了语言模型,另一个预训练任务就是下一个句子预测
这两个数据一个是正例一个是负例

















 369
369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









