






K-Nearest neighbor
(个人观点,仅供参考。)
k-近邻算法,第一个机器学习算法,非常有效且易掌握,本文将主要探讨k-近邻算法的基本理论和使用距离侧量的算法分类物品;最后通过k-近邻算法改进约会网站和手写数字识别系统。文章内容参考《机器学习实战》
K-近邻分类算法
简单的说,通过采用不同特征值之间的距离方法进行分类
优点:精度高,对异值不敏感,无数据输入假定。
缺点:计算复杂、需要大量的内存。
适用于:数值型和标称型数据。
工作原理: 在训练集中,每个样本都存在标签,即我们知道样本集中每一个数据与所属的分类的对应关系。当我们给一个没有标签的数据时,我们比较这份数据与现有的所有数据分别进行比较,然后算法从样本集中提取样本集中特征最相近似数据的分类标签。一般来说,我们只选择样本数据集中前K个相似的的数据,通常k不大于20;
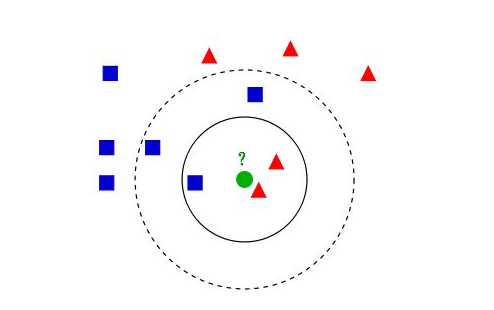
例:区分电影的类型,人类可以工具自己对影片的理解来区分影片类型,但是机器则没有那么高级。但可以根据类型的特性来却别,例如爱情片打kiss的要多于动作片打Kiss的场景,动作片kick的场景要多与kiss。假设你无聊数了几部电影中kiss和kick的场景,数据如下图:

根据上表使用python画出散点图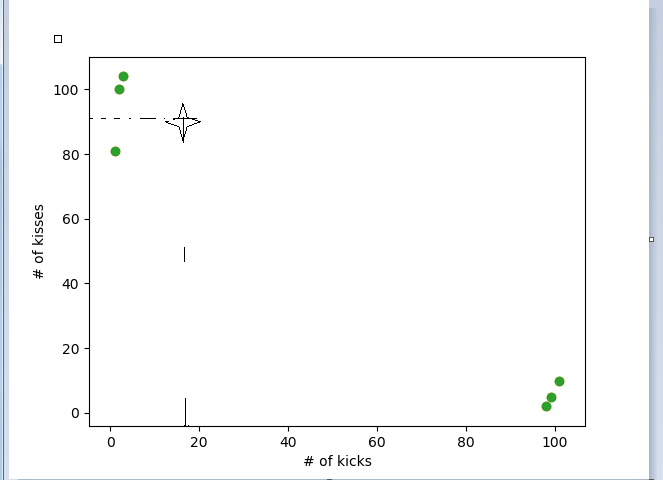
从图中可以很明了的看出未知类型的电影和哪一类电影更相近一些,假设这里的k取值三,这里靠近未知电影的的三部电影全部为爱情电影,所以我们判定未知电影为爱情片。
按照上一篇文章机器学习的基本步骤,将使用python完成一个简单的KNN算法的。
KNN算法的简单方法:
1.收集数据:任何方式
2.准备数据:计算距离所需要的数据,最好是结构化的数据
3.分析数据:
4.训练数据:KNN算法不需要
5.测试:计算误差
6.算法应用
from numpy import *
import operator
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labelsK-Nearest Neighbors 算法
从文本文件中解析和导入数据
# KNN Load data from files and translate to matris
def file2matrix(filename):
fr = open(filename, encoding='utf-8')
# get number of lines in files
numberOfLines = len(fr.readlines())
# create Numpy matrix to return
# create a matrix [0,0,0]
returnMat = zeros((numberOfLines,3))
classLabelVector = []
fr = open(filename,encoding='utf-8')
index = 0
for line in fr.readlines():
# strip() return a copy of the sequence with speciafied leading and trailing bytes removed
line = line.strip()
# split() split the binary sequence into subsequenceds of the same type, using sep as the delimiter string
listFromLine = line.split('\t')
# print (listFromLine)
# 提取数据前三列 which generate a new matrix listFromLine
returnMat[index,:] = listFromLine[0:3]
# print (returnMat)
# print (listFromLine)
# print (listFromLine[0:3])
# according to the flag to classify
# print (listFromLine)
classLabelVector.append(int(listFromLine[-1]))
index = index + 1
return returnMat,classLabelVector(原文中的代码有些问题。文件数据中的最后一列需要转化成为数字)
使用python创建扩散图
分别定义了三个绘制散点图的函数:
# 绘制不带标签的散点图
def draw_scatter_noLabels(datingDataMat):
fig = plt.figure()
# 设置画布的布局
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,1],datingDataMat[:,2])
return (plt.show())
# 绘制无标签数据
def draw_Time_Icecream_scatter_withLabels(datingDataMat,datingLabels):
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15*array(datingLabels),15*array(datingLabels))
ax.set_title('Hellen\'s data')
ax.set_xlabel('percentage of Time Spent Playing Video Games')
ax.set_ylabel('Liters of ice cream consumed per week')
return (plt.show())
# 绘制带有标签的Flyier MIles-Time spent on the video game
def draw_Miles_Time_scatter_withLabels(datingDataMat,datingLabels):
fig = plt.figure()
ax = fig.add_subplot(111)
# identify three class type1 不喜欢 type2 喜欢 type3很喜欢
type1_x = []
type1_y = []
type2_x = []
type2_y = []
type3_x = []
type3_y = []
for i in range(len(datingLabels)):
# print (datingLabels)
if datingLabels[i] == 1:
type1_x.append(datingDataMat[i][0])
type1_y.append(datingDataMat[i][1])
if datingLabels[i] == 2:
type2_x.append(datingDataMat[i][0])
type2_y.append(datingDataMat[i][1])
if datingLabels[i] == 3:
type3_x.append(datingDataMat[i][0])
type3_y.append(datingDataMat[i][1])
type1 = ax.scatter(type1_x,type1_y,s=20,c='r')
type2 = ax.scatter(type2_x,type2_y,s=40,c='y')
type3 = ax.scatter(type3_x,type3_y,s=60,c='b')
# ax.scatter(datingDataMat[:,0],datingDataMat[:,1],15*array(datingLabels),15*array(datingLabels),label=datingLabels)
ax.set_title('Hellen\'s data')
ax.set_xlabel('Frequent Flyier Mils earned Per Year')
ax.set_ylabel('percentage of time spentplaying video games')
plt.legend((type1,type2,type3),("Did Not like ",'Like in small Does','liked in large Does'))
return (plt.show())
归一化数值
···
http://docs.alerta.io/en/latest/index.html
http://alerta.io/
End Sub















 1327
1327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









