线性回归的一个问题是可能出现欠拟合现象。显而易见,模型欠拟合就不能取得好的预测效果,如下图,线性拟合并不能挖掘出数据的一些潜在规律。
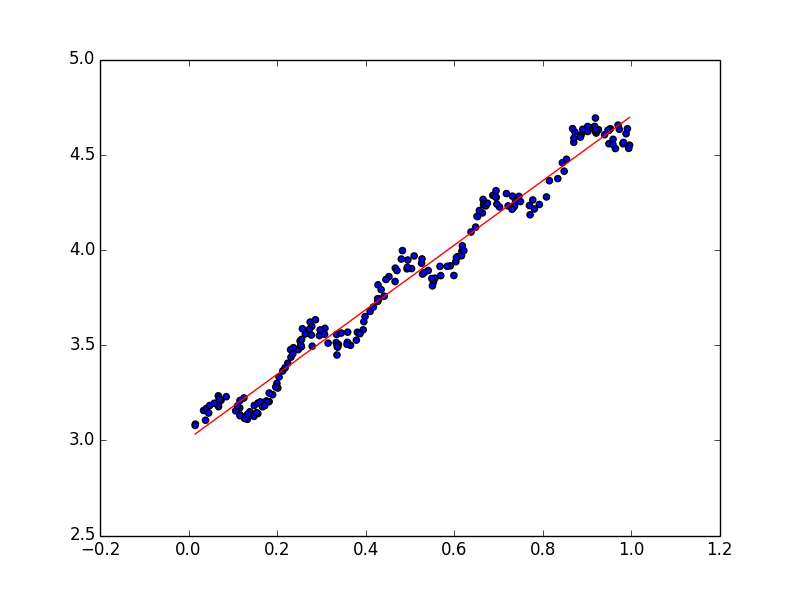
一个常见的解决方法是局部加权回归。该算法的思想是给待预测点附近的每一个点赋予一定的权重(离待预测点越近权重越大,越远权重越小,即以待预测点附近点的一个子集来进行普通的线性回归)
普通线性回归与局部加权线性回归的区别在于,普通线性回归是选择合适的参数
θ
最小化
∑i(y(i)−θTx(i))
;而局部加权回归则是要最小化
∑iw(i)(y(i)−θTx(i))
。
w
即为权重函数,需要满足前面提到的条件,最常用的函数形式为高斯型:
w(i)=exp(−(x(i)−x)22k2)
该算法解出的回归系数形式为:
w=(XTWX)−1XTWY
在采用上述高斯型权重函数前提下,
W
<script type="math/tex" id="MathJax-Element-7">W</script>是一个对角矩阵。函数中K是一个需要用户指定的参数,它决定了对附近的点赋予多大的权重。
示例:
import numpy as np
import matplotlib.pyplot as plt
def loadData(fileName):
numFeat = len(open(fileName).readline().split('\t')) - 1
x = []
y = []
ifs = open(fileName)
for line in ifs.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat):
lineArr.append(float(curLine[i]))
x.append(lineArr)
y.append(float(curLine[-1]))
return x,y
x,y = loadData('ex0.txt')
K = [1.0, 0.01, 0.003]
subplot = [311, 312, 313]
fig = plt.figure(figsize=(10,15),dpi=80)
for index in range(len(K)):
m = len(x)
yHat = np.zeros(m)
for i in range(m):
curExp = x[i]
xMat = np.mat(x)
yMat = np.mat(y).T
weights = np.mat(np.eye(m))
for j in range(m):
diffMat = curExp - xMat[j,:]
k = K[index]
weights[j,j] = np.exp(diffMat * diffMat.T/(-2*k*k))
ws = (xMat.T * weights * xMat).I * xMat.T * weights * yMat
yHat[i] = curExp * ws
print yHat[0]
plt.subplot(subplot[index])
plt.scatter(xMat[:,1].flatten().A[0],yMat[:,0].flatten().A[0],s=2,c='red')
sortIndex = xMat[:,1].argsort(0)
xSort = xMat[sortIndex][:,0,:]
plt.plot(xSort[:,1].flatten().A[0],yHat[sortIndex])
plt.show()
当采用不同的K时,对拟合产生的影响如下图所示:
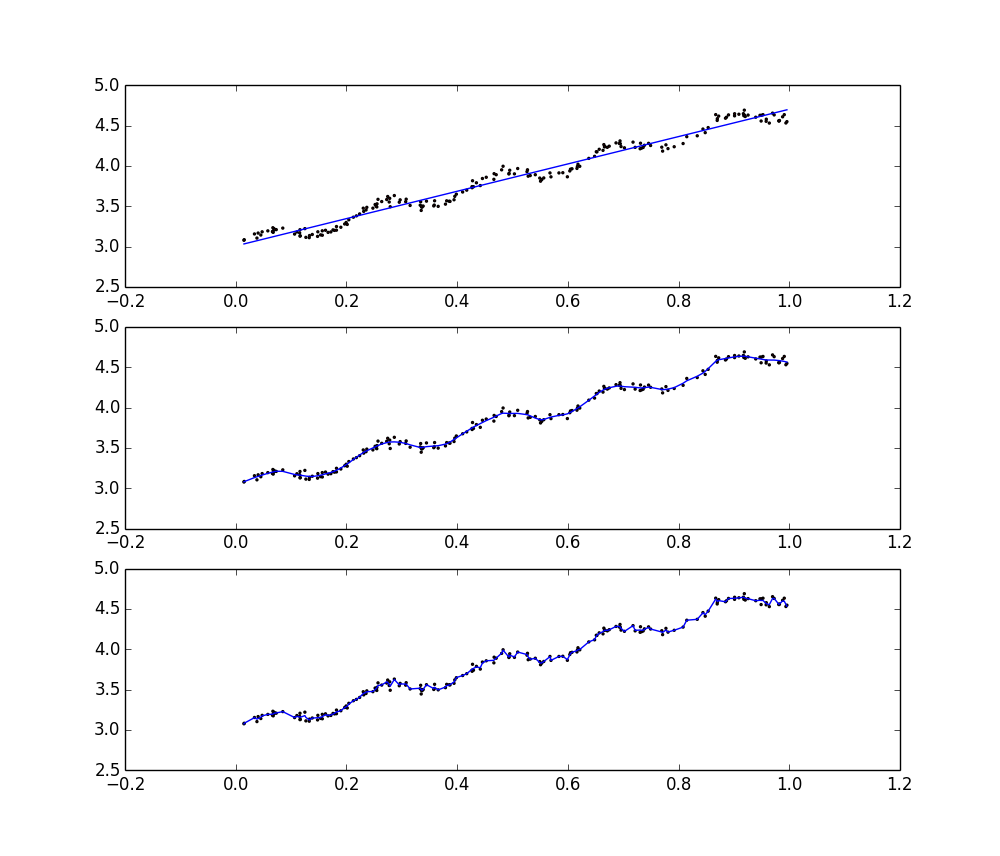
k=1.0时权重很大,即将所有数据点权重视为相同,此时就与普通的线性回归一致。k=0.01时得到了很好的效果,挖掘出了数据的潜在规律。k=0.003时又引入了过多的噪声,拟合的效果过于贴近。也就是说,k=1时欠拟合了,而k=0.003时又过拟合了。
局部加权回归也存在一个问题,即增加了计算量,因为它对每个点做预测时都必须使用整个数据集。























 3908
3908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









