







局部加权线性回归
依赖
import numpy as np
import matplotlib.pyplot as plt
人工数据集
n = 100
true_theta1 = np.array([1, 2]).reshape(-1,1)
true_theta2 = np.array([16, -3]).reshape(-1,1)
X = np.random.normal(3, 1, (n,1))
X = np.insert(X, 0, 1, axis = 1)
def get_y(X):
return np.array([e @ true_theta2 if e[1]>3 else e @ true_theta1 for e in X]).reshape(-1,1)
y = get_y(X) + np.random.normal(0, 0.01, (n,1))
np.insert(X, 2, y.T, axis = 1)
plt.scatter(X[:,1], y)
<matplotlib.collections.PathCollection at 0x7efdca896fd0>
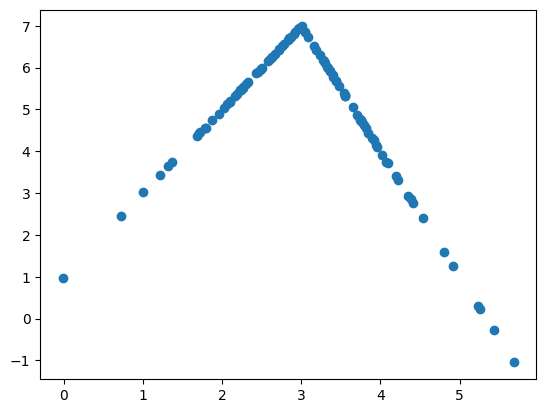
以上为人工数据集分布。
局部加权线性回归函数
本代码通过使用最小二乘法直接求最优解。
def lwlr(X, x, y, k):#直接返回最优解的theta
m = X.shape[0]
W = np.diag(np.exp(-(X[:,1]-x)**2/2/(k**2)))
return np.linalg.pinv(X.T @ W @ X) @ X.T @ W @ y
#np.array([1,x]) @ theta ,np.array([1,x]) @ true_theta1, np.array([1,x]) @ true_theta2, get_y([[1,x]])
损失函数
损失函数如下,其中 w i = e ( x − x i ) 2 2 τ 2 w_i = e^{\frac{(x-x_i)^2}{2\tau ^2}} wi=e2τ2(x−xi)2
J
(
θ
)
=
1
n
∑
i
=
1
n
w
i
(
X
i
θ
−
y
i
)
2
=
(
X
θ
−
y
)
T
W
(
X
θ
−
y
)
\begin{array}{rcl} J(\pmb\theta) &=& \frac{1}{n} \sum_{i=1}^{n}w_i(\pmb X_i\pmb\theta-y_i)^2 \\ &=&(\pmb X\pmb\theta-\pmb y)^T\pmb W (\pmb X\pmb\theta-\pmb y) \\ \end{array}
J(θθ)==n1∑i=1nwi(XXiθθ−yi)2(XXθθ−yy)TWW(XXθθ−yy)
对表达式求导:
∂
J
(
θ
)
∂
θ
=
∇
θ
(
(
X
θ
−
y
)
T
W
(
X
θ
−
y
)
)
=
x
=
X
θ
−
y
∂
x
T
W
x
∂
x
∇
θ
(
X
θ
−
y
)
=
(
2
W
x
)
T
X
=
2
(
X
θ
−
y
)
T
W
X
\begin{array}{rcl} \frac{\partial J(\pmb\theta)}{\partial\pmb\theta} &=& \nabla_{\pmb \theta}((\pmb X\pmb\theta-\pmb y)^T\pmb W (\pmb X\pmb\theta-\pmb y)) \\ &\overset{\pmb{x} = \pmb X\pmb\theta-\pmb y }{=}& \frac{\partial\pmb x^T \pmb W \pmb x}{\partial \pmb x} \nabla_{\pmb \theta}(\pmb X \pmb\theta - \pmb y)\\ &=& (2\pmb W \pmb x)^T \pmb X\\ &=& 2(\pmb X\pmb\theta-\pmb y)^T \pmb W \pmb X\\ \end{array}
∂θθ∂J(θθ)==xx=XXθθ−yy==∇θθ((XXθθ−yy)TWW(XXθθ−yy))∂xx∂xxTWWxx∇θθ(XXθθ−yy)(2WWxx)TXX2(XXθθ−yy)TWWXX
令
∂
J
(
θ
)
∂
θ
=
0
\frac{\partial J(\pmb\theta)}{\partial\pmb\theta} = \pmb 0
∂θθ∂J(θθ)=00
得
2
(
X
θ
−
y
)
T
W
X
=
0
2(\pmb X\pmb\theta-\pmb y)^T \pmb W \pmb X = \pmb 0
2(XXθθ−yy)TWWXX=00
2
(
X
θ
−
y
)
T
W
X
=
0
(
X
θ
−
y
)
T
W
X
=
0
(
(
X
θ
)
T
−
y
T
)
W
X
=
0
(
θ
T
X
T
−
y
T
)
W
X
=
0
θ
T
X
T
W
X
−
y
T
W
X
=
0
θ
T
X
T
W
X
=
y
T
W
X
X
T
W
X
θ
=
X
T
W
y
θ
=
(
X
T
W
X
)
−
1
X
T
W
y
\begin{array}{rcl} 2(\pmb X\pmb\theta - \pmb y)^T \pmb W \pmb X &=& \pmb 0\\ (\pmb X\pmb\theta - \pmb y)^T \pmb W \pmb X &=& \pmb 0\\ ((\pmb X\pmb\theta)^T - \pmb y^T)\pmb W \pmb X &=& \pmb 0\\ (\pmb\theta^T\pmb X^T - \pmb y^T)\pmb W \pmb X &=& \pmb 0\\ \pmb\theta^T\pmb X^T\pmb W \pmb X - \pmb y^T\pmb W \pmb X &=& \pmb 0\\ \pmb\theta^T\pmb X^T\pmb W \pmb X &=& \pmb y^T\pmb W \pmb X\\ \pmb X^T \pmb W\pmb X\pmb\theta &=& \pmb X^T \pmb W\pmb y \\ \pmb\theta &=& (\pmb X^T \pmb W\pmb X)^{-1}\pmb X^T \pmb W\pmb y \\ \end{array}
2(XXθθ−yy)TWWXX(XXθθ−yy)TWWXX((XXθθ)T−yyT)WWXX(θθTXXT−yyT)WWXXθθTXXTWWXX−yyTWWXXθθTXXTWWXXXXTWWXXθθθθ========0000000000yyTWWXXXXTWWyy(XXTWWXX)−1XXTWWyy
预测
k=1
xrange = [x for x in np.arange(-1,10,0.1)]
t1 = [get_y([[1,x]])[0][0] for x in xrange]
print(t1)
#print(xrange)
#print([x for x in xrange])
t2 = [(np.array([[1,x]])@ lwlr(X, x, y, k))[0][0] for x in xrange]
print(t2)
c = ['o' for x in xrange] + ['+' for x in xrange]
for xx, yy, cc in zip([xrange[:],xrange[:]],[t1[:],t2[:]], c):
plt.scatter(xx, yy, marker = cc)
for i in xrange:
print(f"当x点为{i},真实值为{get_y([[1, i]])},预测值为{np.array([[1, i]])@ lwlr(X, i, y, k)}")
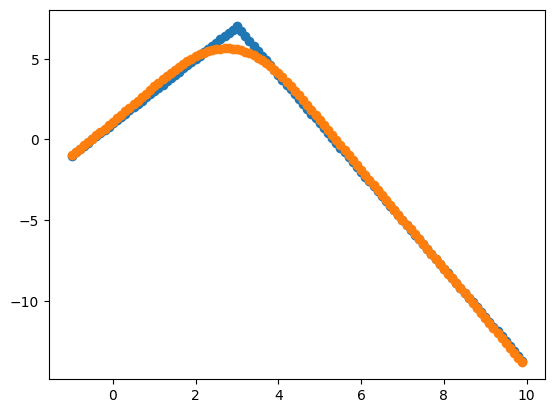
plt.show()
!
(●’◡’●)
局部加权线性回归需要保存训练的数据,能拟合不能确定模糊表达式的点集,其预测值主要会被附近的点影响,但远离预测值 x x x的对预测值的影响几乎为零。通过 w w w函数实现一个类钟形曲线的权重。当超参数 τ \tau τ(代码里的k)的大小能够调节钟形曲线的瘦高还是矮胖。 τ \tau τ越小,会更符合原数据,也会容易过拟合。而 τ \tau τ越大,曲线将会受很远的值影响,也会能预测出数据较少或者的位置的值。
但我所构建的数据集,其实并不符合实际,生活中的数据不应该出现毛刺,应该更平滑点如预测曲线,所以我认为预测曲线更符合实际。















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









