






逻辑回归
逻辑回归简介
[了解]应用场景
预测疾病(是阳性,不是阳性)
银行信任贷款(房贷,还是不房贷)
情感分析(正面,负面)
预测广告点击率(点击,不点击)
逻辑回归是解决二分类问题的利器
[熟悉]数学知识
[知道]sigmoid函数
数学公式
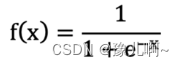
作用
![]()
数学性质
单调递增函数
拐点在x=0,y=0.5的位置
导函数公式
![]()
[理解]概率
概率 - 事件发生的可能性
联合概率和条件概率是概率论中的基本概念,它们用于描述随机变量之间的关系
北京早上堵车的可能性PA= 0.7,中午堵车的可能PB = 0.3, 晚上堵车的可能性PC = 0.4
联合概率 - 指两个或多个随机变量同时发生的概率
PA = 0.7 周一早上 周二早上同时堵车的概率 PAPB = 0.7*0.7 = 0.49
条件概率 - 表示事件A在另一个事件B已经发生条件的发生概率, P(a|b)
PA = 0.7 周一早上 堵车的情况下, 中午再堵车的概率PB|A = 0.7*0.3 = 0.21
[理解] 极大似然估计
核心思想
设模型中含有待估参数w,可以取很多值.已经知道了样本观测值,从w的一切可能值中(选出一个使该观察值出现的概率为最大的值,作为w参数的估计值,这就是极大似然估计.(顾名思义:就是看上去那个是最大可能的意思)
[知道]对数函数
对数函数


对数函数性质

逻辑回归原理
[理解]原理
逻辑回归概念
一种分类模型,把线性回归的输出,作为逻辑回归的输入
输出是(0,1)之间的值
基本思想
1.利用线性模型f(x) = wx + b根据特征的重要性计算出一个值
2.再使用 sigmoid函数将 f(x)的输出值映射为斜率值
1.设置阈值(eg:0.5),输出概率值大于0.5,输出概率值大于0.5,则将未知样本输出为1类
2.否则输出为0类
3.逻辑回归的假设函数
h(w) = sigmoid(wx+b)
线性回归的输出,作为逻辑回归的输入
[知道]损失函数
损失函数的原理的工作原理: 每个样本预测值有A,B两个类别 ,真实类别对应的位置,概率越大越好
我们对损失函数的希望是: 当样本是1类别,模型预测的p越大越好;
当样本是0类别,模型预测的(1-p)越大越好;
让联合概率事件最大时,估计w,b的权重参数,这就是极大似然估计
极大似然损失转对数似然损失,取log优化损失函数:连乘形式转为对数加法形式
最大化问题将其变为最小化问题
使用梯度下降优化算法,更新逻辑回归算法的权重参数
逻辑回归APL
sklearn.linear_model.LogisticRegression(solver='liblinear', penalty=‘l2’, C = 1.0)
solver** **损失函数优化方法**:
训练速度:liblinear 对小数据集场景训练速度更快,sag 和 saga 对大数据集更快一些。 2 正则化:
1. newton-cg、lbfgs、sag、saga 支持 L2 正则化或者没有正则化
2. 2liblinear 和 saga 支持 L1 正则化
penalty*正则化的种类,l1 或者 l2
C:正则化力度
默认将类别数量少的当做正例
分类评估方法
[理解]混淆矩阵
混淆矩阵作用在测试集样本集中:
1. 真实值是 正例 的样本中,被分类为 正例 的样本数量有多少,这部分样本叫做真正例(TP,True Positive)
2. 真实值是 正例 的样本中,被分类为 假例 的样本数量有多少,这部分样本叫做伪反例(FN,False Negative)
3. 真实值是 假例 的样本中,被分类为 正例 的样本数量有多少,这部分样本叫做伪正例(FP,False Positive)
4. 真实值是 假例 的样本中,被分类为 假例 的样本数量有多少,这部分样本叫做真反例(TN,True Negative)
True Positive :表示样本真实的类别
Positive :表示样本被预测为的类别
[掌握]Precision(精确率)
精确率也叫做查准率,指的是对正例样本的预测准确率。比如:我们把恶性肿瘤当做正例样本,则我们就需要知道模型对恶性肿瘤的预测准确率。
[掌握]Recall(召回率)
召回率也叫做查全率,指的是预测为真正例样本占所有真实正例样本的比重。
例如:我们把恶性肿瘤当做正例样本,则我们想知道模型是否能把所有的恶性肿瘤患者都预测出来。
[掌握]F1-score
如果我们对模型的精度、召回率都有要求,希望知道模型在这两个评估方向的综合预测能力如何?则可以使用 F1-score 指标。
[知道]ROC曲线和AUC指标
ROC 曲线
ROC 曲线:我们分别考虑正负样本的情况:
1. 正样本中被预测为正样本的概率,即:TPR (True Positive Rate)
2. 负样本中被预测为正样本的概率,即:FPR (False Positive Rate)
ROC 曲线图像中,4 个特殊点的含义:
1. (0, 0) 表示所有的正样本都预测为错误,所有的负样本都预测正确
2. (1, 0) 表示所有的正样本都预测错误,所有的负样本都预测错误
3. (1, 1) 表示所有的正样本都预测正确,所有的负样本都预测错误
4. (0, 1) 表示所有的正样本都预测正确,所有的负样本都预测正确
AUC 值
1. 我们发现:图像越靠近 (0,1) 点则模型对正负样本的辨别能力就越强
2. 我们发现:图像越靠近 (0, 1) 点则 ROC 曲线下面的面积就会越大
3. AUC 是 ROC 曲线下面的面积,该值越大,则模型的辨别能力就越强
4. AUC 范围在 [0, 1] 之间
5. 当 AUC= 1 时,该模型被认为是完美的分类器,但是几乎不存在完美分类器
AUC 值主要评估模型对正例样本、负例样本的辨别能力.
分类评估报告API
sklearn.metrics.classification_report(y_true, y_pred, labels=[], target_names=None )
y_true:真实目标值
y_pred:估计器预测目标值
labels:指定类别对应的数字
target_names:目标类别名称
return:每个类别精确率与召回率
AUC计算API
from sklearn.metrics import roc_auc_score
sklearn.metrics.roc_auc_score(y_true, y_score)
计算ROC曲线面积,即AUC值
y_true:每个样本的真实类别,必须为0(反例),1(正例)标记
y_score:预测得分,可以是正例的估计概率、置信值或者分类器方法的返回值














 1591
1591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









