






1.基础
先举房屋价面积x与房屋价格y间关系的例子,给出一系列数据集,数据集中包含不同房屋的面积与其对应价格,通过学习,得到一种算法,该算法可根据输入的房屋面积x,自动预测出价格y.
1) 假设函数h(hypothesis),经由学习算法在训练集上产生,输入x,产生估算的结果
2) 代价函数(cost function):即训练误差,在训练模型过程中需要合理选择模型的参数,使得训练结果尽可能符合数据集。
2.单变量线性回归
2.1梯度下降法
假设函数:$h_{\theta }=\theta _{0}+\theta _{1}x$
参数:$theta _{0},theta _{1}$
代价函数:$J\left ( \theta_{0},\theta_{1} \right )=\frac{1}{2m}\sum_{i=1}^{m}\left ( h_{\theta }\left ( x^{\left ( i \right )} \right )-y^{\left ( i \right )} \right )$
目标:调整$theta _{0},theta _{1}$,获得最小化的$J\left ( \theta_{0},\theta_{1} \right )$
算法:
外层迭代{
$\theta_{j}:=\theta_{j}-\alpha\frac{\partial }{\partial \theta_{j}}J\left ( \theta_{0},\theta_{1} \right ) (for j=0 and j=1)$
}
注意:1.所有的theta应同步更新(每次迭代中,中间用变量替代,最后再统一更新theta)
2.$\alpha$为学习率,即梯度下降法中梯度下降的快慢
3.多变量线性回归
3.1梯度下降法
3.1.1 introduce
类似与单变量线性回归中的梯度下降法,不同点是中间计算过程把参数和x,y都向量化。
$\theta_{j}= \begin{matrix}theta_{1}\\theta_{2}\\.\\.\\.\\theta_{n}\end{matrix}$ $x_{j}= \begin{matrix}x_{1}\\x_{2}\\.\\.\\.\\x_{n}\end{matrix}$
单变量与多变量迭代算法对比:
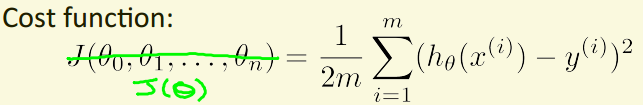
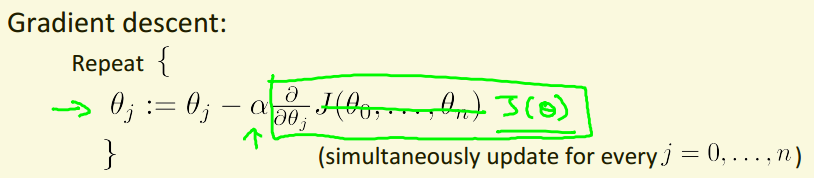

3.1.2 多变量梯度下降需注意的问题
1.特征缩放。
目的:统一各个特征的刻度,试制分布的范围接近[-1,1]。
方法:$x=\frac{x-\mu }{size}$
2.学习率
$\alpha$过低:训练慢
$\alpha$过高:有可能造成迭代时,代价函数反而增大
选择学习率原则:0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1...
3.2 正规方程
一种寻找合适参数$\theta$的直接方法,不需要设置学习率也不需要迭代,但是在n>106时运行速度不足。
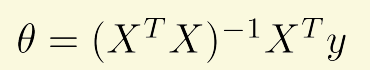















 1930
1930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









