



在深度学习的世界里,卷积神经网络(CNN)是图像识别任务的 “主力军”。但随着网络层数不断加深,“梯度消失”“信息丢失” 等问题也随之而来。而残差网络(ResNet)的出现,像是为深度学习打开了一扇新的窗户,今天我们就来聊聊残差网络里那些关键的设计 “巧思”。
一、残差结构:跨越层级的信息桥梁
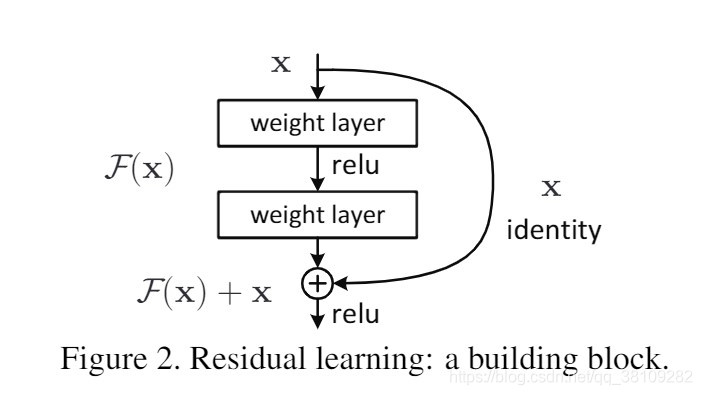
残差结构是 ResNet 的核心创新点。传统的卷积网络,每一层的信息传递是 “串行” 的,前面层的信息经过多次卷积后,很容易出现损耗甚至扭曲。而残差结构引入了跨层连接,就像在网络中搭建了一条 “信息高速通道”。
(一)1×1 卷积的妙用
在残差结构里,1×1 的卷积核可太重要了。一方面,它能调整特征图的维度。比如当我们需要让不同层的特征图维度匹配,以便进行跨层相加时,1×1 卷积可以轻松做到维度的 “升降”。另一方面,1×1 卷积还能起到类似 “调整亮度” 的效果,对特征进行加权,总体上提高或降低某些特征的权重,让有用的特征更突出。
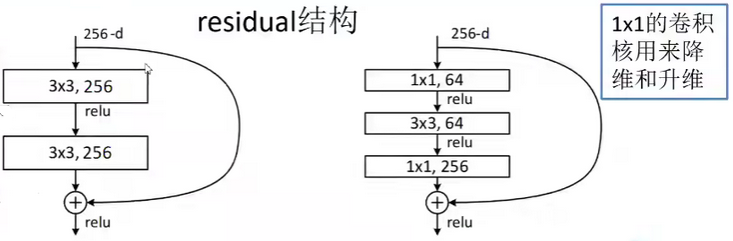
(二)跨层连接:留住原始的 “正确”
跨层连接的设计堪称神来之笔。它能永远保留原始的正确信息,让网络在学习复杂变换的同时,不会丢失底层的关键特征。打个比方,就像我们在解一道复杂的数学题,即使中间步骤做了很多变换,也能随时回看最初的已知条件,确保大方向不会错。这种设计大大缓解了深层网络的梯度消失问题,让网络能 “更深” 也能 “更稳”。
二、全局平均池化:化繁为简的特征提取
在传统的 CNN 中,往往需要用flatten或者view操作将特征图展开成一维向量,再送入全连接层。但 ResNet 采用了全局平均池化。
全局平均池化的特点是,每张特征图经过它之后,只会得到一个特征结果。这样做的好处是,不需要再进行繁琐的展开操作,同时还能对特征进行全局的整合,提取出最具代表性的信息。它就像一个 “提炼器”,把每张特征图中最核心的特征浓缩成一个点,为后续的分类等任务提供简洁又有效的特征表示。
三、标准化:让数据 “平等” 竞争
标准化(如 Batch Normalization)在 ResNet 中也发挥着重要作用。它的主要目的是防止过拟合,同时让所有的数据都 “同等重要”。
在训练过程中,不同样本的数据分布可能存在差异。标准化可以将数据调整到相同的分布范围,避免某些 “强势” 的数据在训练中占据主导地位,让模型能更公平地学习到所有数据的特征。这就像在一场比赛中,给所有选手设定相同的 “起跑线”,保证比赛的公平性,从而提升模型的泛化能力。
四、网络层数:因 “任务” 制宜
ResNet 有不同的版本,从 18 层到 152 层不等。这并不是层数越多就一定越好,而是要根据具体的任务来选择。
- 如果是识别 20 种水果这类相对简单的任务,用小网络(比如 18 层或 34 层)就足够了,152 层的网络对于这种任务来说 “太吓人”,不仅计算资源消耗大,还容易出现过拟合。
- 而如果是识别 2000 种物体这样复杂的任务,就需要 152 层的深层网络。因为任务越复杂,需要学习的特征就越精细、越丰富,深层网络能提取到更抽象、更具判别力的特征,从而提升识别准确率。
五、MNIST 识别实战:分步代码解析
(一)数据加载与预处理
首先,我们需要加载 MNIST 数据集并进行预处理,代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
import torch.optim as optim
# 加载MNIST训练集
training_data = datasets.MNIST(
root='data',
train=True,
download=True,
transform=ToTensor(),
)
# 加载MNIST测试集
test_data = datasets.MNIST(
root='data',
train=False,
download=True,
transform=ToTensor(),
)
# 创建数据加载器,批量加载数据
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=False)
# 打印数据形状,了解输入输出结构
for X, y in test_dataloader:
print(f'Shape of X [N,C,H,W]: {X.shape}')
print(f'Shape of y [N]: {y.shape}, {y.dtype}')
break
这段代码使用torchvision的datasets.MNIST加载数据集,ToTensor将图像转为张量,DataLoader实现数据的批量加载,最后打印数据形状,方便我们了解输入数据的结构。
(二)设备选择
为了充分利用硬件加速训练,我们需要选择合适的设备,代码如下:
# 选择设备,优先使用GPU(cuda),其次是MPS,最后是CPU
device = 'cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
print(f'Using {device} device')
这里会自动检测环境,优先使用cuda(GPU),其次是mps,最后是cpu,确保训练能利用硬件加速。
(三)残差块定义
残差块是 ResNet 的核心,代码如下:
# 定义残差块,体现残差结构核心
class ResBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResBlock, self).__init__()
# 第一个卷积,用于调整通道数和特征
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels) # 标准化,防止过拟合
# 第二个卷积
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels) # 标准化
# shortcut连接,当输入输出通道或尺寸不一致时,用1×1卷积调整
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
residual = x # 跨层连接,保留原始信息
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(residual) # 残差连接,原始信息与新特征相加
out = F.relu(out)
return out
残差块包含两个卷积层、标准化层和跨层连接(shortcut)。shortcut会在输入输出通道或尺寸不一致时,用 1×1 卷积调整,保证残差连接的可行性,解决了深层网络的信息传递问题。
(四)ResNet 模型定义
结合各关键设计,定义完整的 ResNet 模型,代码如下:
# 定义完整的ResNet模型
class ResNet(nn.Module):
def __init__(self, num_classes=10):
super(ResNet, self).__init__()
# 第一层,7×7卷积,捕捉大尺度特征
self.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64) # 标准化
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # maxpool下采样
# 残差层,可根据需要调整层数
self.layer1 = self._make_layer(64, 64, 2, stride=1)
self.layer2 = self._make_layer(64, 128, 2, stride=2)
self.layer3 = self._make_layer(128, 256, 2, stride=2)
self.layer4 = self._make_layer(256, 512, 2, stride=2)
# 全局平均池化,替代flatten
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# 全连接层,用于分类
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, in_channels, out_channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(ResBlock(in_channels, out_channels, stride))
in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.maxpool(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out) # 全局平均池化
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
# 创建模型并移至设备
model = ResNet().to(device)
print(model)
模型初始的 7×7 卷积和maxpool完成特征初步提取与下采样;多个残差层(layer1-layer4)逐步提取更抽象的特征;全局平均池化(AdaptiveAvgPool2d)替代传统flatten,简洁提取特征;最后的全连接层(fc)用于手写数字的 10 分类。
(五)训练与测试函数
定义训练和测试函数,实现模型的训练与评估,代码如下:
# 训练函数
def train(dataloader, model, loss_fn, optimizer):
model.train()
batch_size_num = 1
for X, y in dataloader:
X, y = X.to(device), y.to(device)
# 前向传播
pred = model(X)
loss = loss_fn(pred, y)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 打印训练信息,跟踪训练进度
if batch_size_num % 100 == 0:
print(f"loss: {loss.item():>7f} [batch: {batch_size_num}]")
batch_size_num += 1
# 测试函数
def test(dataloader, model, loss_fn):
model.eval()
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
with torch.no_grad(): # 测试时不计算梯度
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100 * correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
train函数实现模型的训练过程,包括前向传播、损失计算、反向传播和优化;test函数用于评估模型在测试集上的性能,计算准确率和平均损失。
(六)训练循环
设置损失函数、优化器和训练轮数,进行模型训练,代码如下:
# 定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练循环
epochs = 5
for t in range(epochs):
print(f'Epoch {t + 1}\n-------------------------------')
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
print('Done')
这里使用交叉熵损失函数和 Adam 优化器,训练 5 个轮次,每轮训练后测试模型性能。
通过上述分步解析,我们从残差网络的核心原理出发,逐步实现了基于 ResNet 的 MNIST 手写数字识别,充分展现了残差结构、全局平均池化、标准化等技术在深度学习中的优势。

















 354
354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









