






“ 算力准备是大模型私有化部署的必要前提,那什么是算力?大模型算力芯片的种类有哪些?”
无论是大模型训练阶段还是推理阶段都需要强大的算力支撑,什么是“算力”?大模型所需要的算力有何特点?

什么是算力
算力,从字面意思上讲就是计算能力(Computing Power),具体而言,是“对信息数据进行计算,实现目标结果的能力”。小至手机、个人电脑(PC),大到超级计算机,没有算力就没有各种软硬件的正常应用。以个人电脑而言,搭载的CPU、显卡、内存配置越高,一般来说算力就越高。
当然,人类大脑就具有“算力”,我们人类每时每刻都在进行着计算。人类大脑就是一个强大的算力引擎,通过感官系统(视觉、听觉、触觉等)收集信息,进行信息处理(思考、记忆、判断),最后根据信息执行动作(表情、语言、行动等)。对于简单问题,我们会通过口算、心算进行无工具计算。在遇到复杂情况时,我们会利用算力工具进行深度计算。
到了20世纪40年代,我们迎来了算力革命:1946年,我们人类发明了计算机,美国数学家冯·诺依曼制造出了世界第一台现代电子数字计算机ENIAC。可以说,正是算力的发展促成了人工智能技术的一步步突破,人工智能的发展也反向推动了算力的不断提升。
从历史发展角度上讲,算力可以分为传统算力和现代算力。
1. 传统算力:信息计算力
传统算力指计算机中央处理器(Central Processing Unit,CPU)的信息计算力。
CPU计算机的多任务执行有两种执行方式,并发和并行:
并发是指:对于单核CPU处理多任务,同一个CPU在一段时间内交替去执行任务。
并行是指:对于多核CPU处理多任务,操作系统会给CPU的每个内核安排一个执行的软件,多个内核是真正的一起执行软件。
基于CPU的计算能力本质上说是串行计算,多核CPU设计虽然能够并行处理多任务,但是并行能力有限,计算效率低。例如,普通服务器在处理大模型训练时需数月时间,而智能算力服务器仅需数小时。
随着计算机应用的不断发展,传统算力经历了大型机时代(1940-1980)、PC时代(1980-)。在这个阶段,CPU算力基本能够满足人们对计算力的需求,但这是基于CPU算力的不断提高的基础上的。传统计算力越来越无法满足人们对算力的需求,比如著名的安迪-比尔定律,CPU硬件能提供多少算力,计算机应用很快就能消耗多少算力。
注:安迪定律的原话是“安迪提供什么,比尔拿走什么”。其中,“安迪”指的是英特尔原CEO安迪·格鲁夫,而“比尔”则是微软的比尔·盖茨。
传统算力(CPU计算机)主要还是单点计算(一台大型机或一台PC,独立完成全部的计算任务),主要用于基础通用任务,如办公自动化、数据统计、科学计算等,对高复杂度任务(如AI训练和推理)支持不足。
2. 现代算力:计算+存储+网络三要素协同
人们苦于单点式计算的算力不足,便开始尝试网格计算:把许多计算机通过网络连接组织成为一个大型计算系统,并把一个巨大的计算任务,分解为很多的小型计算任务,交给不同的计算机完成。这种把大任务分解成小任务给不同计算机的计算方式又称为分布式计算架构。
云计算,就是分布式计算的一种典型应用。它的本质是将大量的零散独立型算力(算力小、不可靠)资源进行打包、汇聚,实现更高可靠性、更高性能、更低成本的平台型算力(算力大、高可靠)。
具体来说,在云计算中,中央处理器(CPU)、内存、硬盘、显卡(GPU)等计算资源被集合起来,通过软件和网络,组成一个虚拟的可无限扩展的“算力资源池”,“算力资源池”可以动态地进行算力资源的分配。
算力云化之后,数据中心成为了算力的主要载体。人类的算力规模,开始新的飞跃。
此时的算力,是信息计算力、数据存储力、网络运载力等综合体现。
现代算力也经过了云计算时代(2000-2020)和人工智能时代(2020至今)的发展阶段。
为了满足不同应用的算力需求,现代数据中心又可以分为三种不同的类型:通算中心,超算中心,智算中心,也就是人们常说的通算、超算和智算。

通算、超算和智算
1. 通算(CPU为主)
通用型计算,计算机系统执行日常通用任务的基础算力,是计算机系统中最基础的计算能力,用于执行各种常见的计算任务。它不依赖于特定的技术或平台,是计算机系统进行各种计算任务的基础。
硬件架构: 以CPU为主(如英特尔酷睿、AMD Ryzen),支持串行计算与通用任务。
计算精度: 单精度浮点运算(FP32)为主,兼顾通用性。
** 能效比:** 较低(1-2 TFLOPS/W),适合轻量级任务。
因为通用型计算支撑的上层应用繁杂,导致其生态复杂,需要众多的软件厂商与其适配,具有很高的技术壁垒。比如主流的CPU提供商只有两家,英特尔和AMD。即使其他厂商研发出同样性能的CPU芯片,也很难培养生态和市场。
2. 超算(CPU+GPU为主)
超级计算,又称为高性能计算(High Performance Computing,HPC),主要解决大规模科学计算问题的高端算力,以高精度数值计算为核心。主要用于基因分析、新材料、新能源、新药设计、航空航天飞行器设计等领域的研究。超算的核心计算能力由高性能 CPU 或协处理器提供,注重双精度通用计算能力,追求精确的数值计算。
早期是CPU为主,现在主要是CPU+GPU为主。为什么加上GPU呢?GPU(Graphics Processing Unit,图形处理单元)俗称显卡,早期用于大型游戏的图形显示加速处理的,后来发现GPU特别适合数据密集型的向量的计算,所以在超算、智算领域流行并大规模部署。
硬件架构: 采用高性能CPU(AMD EPYC、英特尔至强)、协处理器及大规模并行集群。
计算精度: 双精度浮点运算(FP64)为核心,确保科学计算的精确性。
*能效比:* 能耗极高,需液冷等散热技术支撑。
HPC计算,又可以细分为三类:
科学计算类 : 物理化学、气象环保、生命科学、石油勘探、天文探测等。
工程计算类: 计算机辅助工程、计算机辅助制造、电子设计自动化、电磁仿真等。
智能计算类: 即人工智能计算,包括:机器学习、深度学习、数据分析等。
科学计算和工程计算这些专业科研领域的数据产生量很大,对算力的要求极高。以油气勘探为例:油气勘探,简单来说就是给地表做CT,一个项目原始数据往往超过100TB,甚至可能超过1个PB,如此巨大的数据量,需要海量的算力进行支撑。
3. 智算(GPU为主)
随着人工智能技术的飞速发展,对智能计算需求急剧攀升,因此发展出了智能计算型的新型数据中心,也就是专门进行智能计算的数据中心。这几年,因为人工智能计算的需求旺盛,专门建设了很多智算中心。
智能计算,主要是面向人工智能任务的专用算力,人工智能的核心是神经网络的计算,而神经网络主要是向量矩阵的计算,因此智算中心侧重数据驱动的并行计算与模型训练和推理。主要以GPU算力为主。
硬件架构: 基于GPU(英伟达A100/H100)、TPU、FPGA等专用AI芯片,优化并行计算与矩阵运算,主要有三种类型:
- GPU(图形处理器):并行架构强,可同时处理多任务,如英伟达A100、H100,适用于深度学习训练和推理。
- ASIC(专用集成电路):为特定应用定制,效率高、能耗低,如谷歌TPU,专为机器学习设计,适合大规模数据中心和云计算。
- FPGA(现场可编程逻辑门阵列):可编程、灵活配置,如赛灵思Alveo系列,适合需定制化计算的AI场景,如金融分析、图像处理。
计算精度: 低精度为主(FP16/INT8),适配AI模型训练与推理的高吞吐需
求。
*能效比:*较高(10-30 TFLOPS/W),优化AI任务能耗。
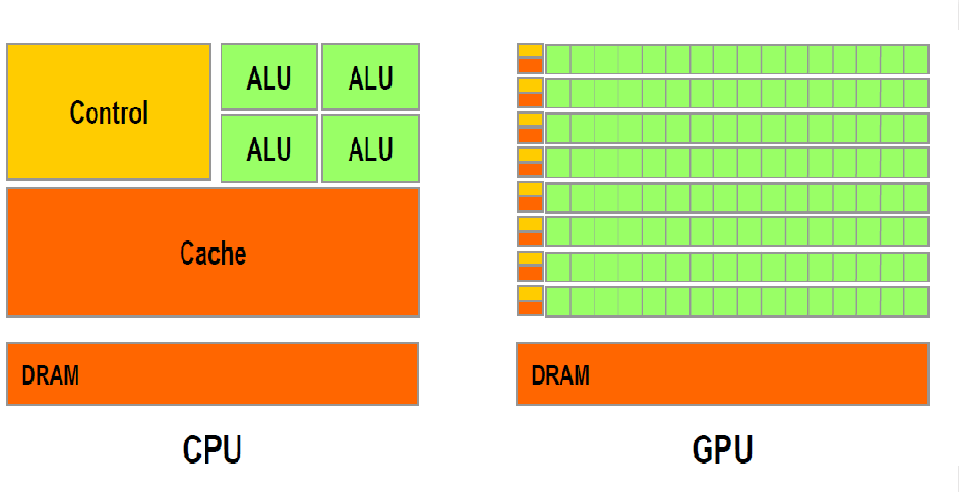
总结CPU与GPU的区别如下:
| CPU | GPU | |
|---|---|---|
| 任务处理 | 一个博士生,擅长处理复杂逻辑与分支任务。 | 一群小学生,适合并行处理简单重复任务。 |
| 指令执行 | 按人类直觉顺序执行,遇分支可跳转。 | 无法执行跳转指令,采用全计算后赋值策略。 |
| 适算类型 | 提升对分支语句处理效率,核心数少,寄存器多,因而更适合处理大型复杂任务,而不适合大量重复简单计算。 | 不断堆叠计算核心数量,适用于图形渲染。由 RT core、CUDA 核心、Tensor 核心组成,功能拓展到科学计算与 AI 领域。 |
不同于通算的CPU,智算GPU的发展时间短,支撑的上层应用相对单一,无需复杂的生态适配,适配难度小很多,因此做起来相对容易。国内做人工智能芯片的公司发展不错,例如华为、曙光、沐曦、寒武纪、壁仞等。
智算芯片的演进
1.GPU
从名称上我们就知道,GPU(Graphics Processing Units,图形处理器)起初不是专为智能型计算而设计,是为大型网络游戏画面渲染显示而设计的。图形处理原理是通过大量计算单元同时计算图形中每一个线条中点的坐标。而人工智能计算最基本的计算类型是矩阵运算,恰好与图形运算是类似的,因而被用于智算领域。
2.GPGPU
基于GPU,厂商为了满足智算需求,在GPU的基础上进一步增加了矩阵运算单元,进一步增强了智算的计算能力。
例如,在英伟达的GPU中,有个叫Tensor核心的东西(又叫张量核心),就是专门为矩阵运算设计的。
这种不仅可以进行图形渲染,还可以进行非图形领域的通用计算任务的GPU有了一个新的名称GPGPU。
GPGPU(General Purpose computuing on GPU)即通用计算型图形处理器,是指利用GPU原本为图形渲染设计的高并行计算能力,执行非图形领域的通用计算任务。其核心在于将GPU的并行架构(如英伟达的CUDA核心、AMD流处理器)应用于科学计算,人工智能等高并行计算场景。
国产处理器如海光DCU系列产品以GPGPU架构为基础,以AMD RX4000系列为基础进行改进的流处理器,兼容通用的“类CUDA”环境以及国际主流商业计算软件、人工智能软件,可广泛应用于大数据处理、人工智能、商业计算等领域。
3.NPU
人工智能计算需求如此旺盛,那为什么不抛开GPU,直接设计一款专用于人工智能领域的芯片呢?因此我们有了NPU。
NPU(Neural Processing Units,神经网络处理器)是一种专门为人工智能(AI)计算设计的处理器,主要用于高效执行神经网络相关的运算(如矩阵乘法、卷积、激活函数等)。相较于传统CPU/GPU,NPU在能效比和计算速度上更具优势,尤其适合移动设备、边缘计算和嵌入式AI场景。
国产芯片如华为昇腾910系列就是华为自主研发的高性能NPU,其综合性能在国产AI芯片中处于领先地位,并在多个行业应用中展现出显著优势。
随着人工智能计算的需求越来越多,专用计算芯片的比例正在逐步增加,这几年逐渐开始流行起来的TPU、DPU等,都是智算领域的专用芯片。
4.TPU
TPU(Tensor Processing Unit,张量处理器)是谷歌于2016年推出的张量处理单元,主要用于低精度运算。这款专为机器学习设计的专用芯片(ASIC),通过硬件与算法的深度协同优化,在性能、能效比和扩展性上实现了突破,成为驱动AI技术进化的重要引擎。
5.DPU
DPU(Data Processing Unit,数据处理器) 是一种专为数据中心设计的处理器,旨在解决传统CPU在处理网络、存储、安全等基础设施任务时的效率瓶颈。作为继CPU、GPU之后的“第三颗主力芯片”,DPU通过硬件加速和任务卸载,释放CPU算力以支持核心业务应用。在人工智能计算领域的主要作用有:
- AI推理加速:DPU支持轻量级模型推理,例如在智能摄像头中实现实时目标检测。
- 科学计算:通过RDMA技术优化跨节点数据传输,提升分布式计算效率。
除了基础通用算力、智能算力、超算算力之外,科学界还出现了前沿算力的概念,主要包括量子计算、光子计算等,同样值得关注。
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!
你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!

















 3974
3974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









