









1、人脸识别
人脸验证(Face Verification):输入图片和模板图片是否为同一人,一对一问题。
人脸识别(Face Recognition):输入图片,检测是否为多个模板图片中的一个,一对多问题。
一般来说,人脸验证由于范围较小难度较小,而人脸识别需要进行一对多的比对难度较大准确率也较低。
One-Shot Learning: 由于人脸数据库的容量 K 并不固定,如果使用以前的分类方法,在全连接层后面进行softmax分类的话,一旦容量 K 变动,那么需要重新修改和训练模型,代价太大。因此需要一种方法通过卷积模型定义一个编码方式之后可以只进行一次训练,即可以获取输入图片的输入结果,对输入结果进行比较得出识别结果。
现在一般使用 相似函数(similarity function) 来比较两个图片的编码结果:其差异 d 小于某个阀值时认为相同,否则认为不同。
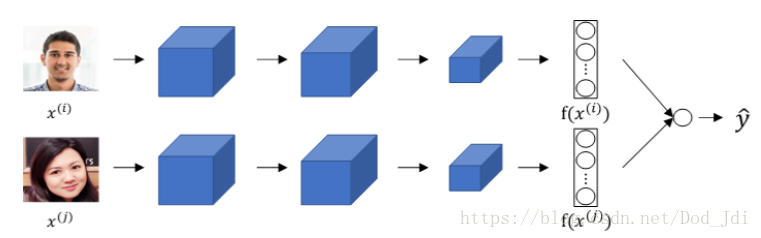
Siamese Network: 确定比较方法之后,可以对编码结果进行直接比较。我们知道卷积过程实际上是提取图片特征的过程,全连接层可以看做图片特征的某种编码结果,因此直接使用 全连接的神经元参数 计算,而再不进行softmax等分类。网络结果如下。

得到图片 x(1)和x(2) x ( 1 ) 和 x ( 2 ) 的 编码(卷积)结果 f(x(1))和f(x(1)) f ( x ( 1 ) ) 和 f ( x ( 1 ) ) 后,其相似函数可以表述为编码结果差值的范数:
显示为同一个人时 d 值应该很小,不同是 d 应该较大。
Triplet Loss(三重损失函数): 如果任选一张和其他图片进行比较,显然不相同的比例很大,此时模型错误认为不相同的代价太小,不利于模型的训练。因此一次训练引入三张图片:靶(Anchor)、正例图片(Positive)和反例图片(Negative)。

因为人脸相同时相似函数 差值d 小,不同时 差值d 大,因此:
然而上式当两个都为0时总成立,这不是我们希望看到的,引入边界(Margin)量:, α α ,有:
也就是说当人脸不相同时 上式 >=0 , 可以将其作为惩罚因子,Triplet (有三个对象)损失函数为(max函数表示取其中最大值):
扩展得到 m 个样本的代价函数(cost function):
然后即可以通过梯度下降训练神经网络。另外为了提高准确性需要给模型增加难度,例如不随机选取A,P,N三张图片,选择(A,P)相差较远(如换发型),而(A,N)相差较近的图片。
人脸验证(Verification)可以作为二分类问题处理, 将两张图片输入同一个模型得到全连接层,然后对两个子全连接层进行计算得到二分类结果:相同或是不同。
2、神经风格迁移
神经风格迁移(Neural style transfer)的过程很好的体现了卷积网络的工作原理。在卷积得到的第一层特征图(Feature Map)中遍历找到使激活函数值最大(特征最明显?)的9x9块图像区域如下, 其主要提取了一些形状和颜色特征:

下面是有浅层到深层的变化:

放大第五层可以发现,越深的层其检测出的特征越全代表性越强:

神经风格迁移生成的图片其内容分别来自内容图和风格图:

使用类似人脸识别Triplet Loss的思想,将内容代价函数(Content cost function)和风格代价函数(Style cost function)两个组合作为训练的依据, α,β α , β 是调整权重的超参数:
由前面的卷积过程解释可以看出, 每一层的输出 al a l 都是原始数据的特征编码,同人脸识别一样,比较两个图片的编码 al a l 可以得到其差异。并且由于随着 l l 的加深 al a l 越能更全面具体的反映原图,因此,为了能够减少加入风格迁移引起的差异,一般使用中间层数的 l l , 内容代价函数为:
卷积神经网络的一个重要特征是参数共享,也就是说一次卷积时按一次特定的规则对整个图片提取特征,不同的通道是不同方式提取特征的结果,如果一个特征在多个通道中出现且值较大,其所代表的风格(形状(扭曲)和颜色等)也就越明显。反过来,风格明显的区域卷积之后不同通道 al a l 中的对应的激活值都比较大,因此可以是以乘积来表示两个通道间的特征相关性,获取图片的风格矩阵:
风格代价函数计算风格图(S)和生成图(G)的风格矩阵间的差异:
可能是由于不同通道间提取到的特征的相似度较低,可以使用多层的风格矩阵相加如下, λ λ 是权重超参:
3、多维卷积
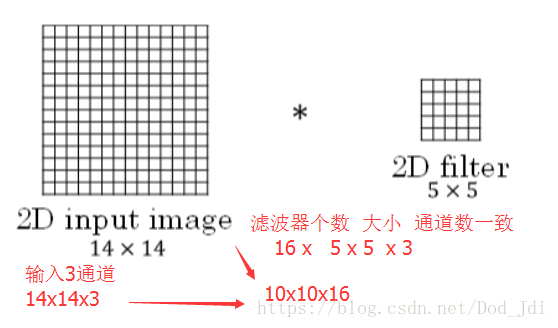
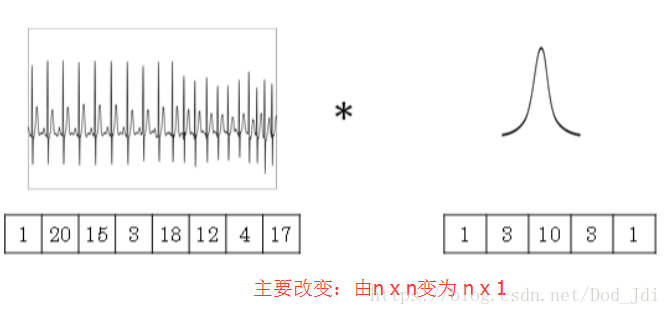
主要在于大小(维度)的变化, 输入时什么维度,滤波器也是什么维度,通道数保持一致,滤波器个数随意。
二维:
一维:
三维:















 568
568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









