






仅供个人学习记录
1、过拟合解决方法
dropout、bn、数据增强、更多的数据集、早停、正则化
2、bn层
防止梯度消失和梯度爆炸,将数据调整为均值为0,方差为1的分布。
其跟在卷积层后,激活层前,也是因为卷积后的数据有很多是小于0的,在直接进行relu后,会造成神经元死亡。
存在两个γ、β,偏移和缩放因子。
3、梯度消失和梯度爆炸
权重初始化过大或过小
sigmoid函数的特性,中间变化明显,两边变化较小,且梯度趋近于0
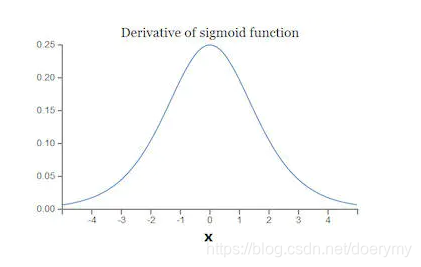
4、relu函数的优缺点
让一些神经元输出置0,减少计算,减少参数之间的相互依赖,解决了梯度消失爆炸问题。
但也会导致一些神经元坏死。通常前一层要做bn操作。
5、SGD
随机选取1个样本、更多为batch个样本进行梯度下降,加入动量的SGD为指数平均
vt=β * vt−1+(1−β)θt
β通常为0.9
6、Adam
Adam定义了一阶动量mt和二阶动量vt,分别为当前次迭代时梯度的一次函数与二次函数,超参数,设置为0.9与0.999。
m = beta1*m + (1-beta1)*dx
v = beta2*v + (1-beta2)*(dx**2)
x += - learning_rate * m / (np.sqrt(v) + eps)7、卷积核与padding后的图片尺寸公式
假设输入大小为(H,W),滤波器大小为(FH,FW),输出大小为(OH,OW),填充为P,步幅为S。
此时,输出大小公式:
h = (H + 2P - FH)/S +1
8、FLOPs
floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
CNN : 2*k*k * Cin *Cout * H * W考虑bias ,(2 * Cin * K*K-1) * Cout*H*W
k为卷积核大小,C为通道数,HW为输出层宽高
FC :(2*I -1)*O不考虑bias
I输入神经元数,O输出神经元数
9、L1和L2正则化
在最后损失函数上,加上对权重w的惩罚
loss = y - (wx+b) + |w|/w**2
L1就是绝对值,L2是平方
L1正则化可以获得稀疏的矩阵,L2可以改善过拟合。
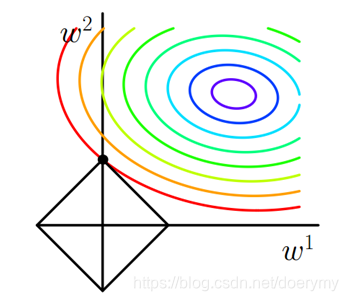
L1loss : J = J0 + a*|w|
二维情况下,J0是曲线,L1是菱形,其相交点是最优解,由于L1是多边形,顶点在坐标轴上,所以相交点也多为0,所以导致L1正则化可以产生稀疏矩阵。
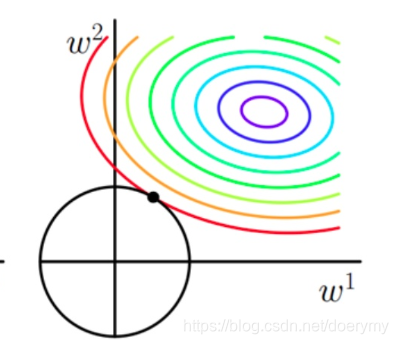
L2loss:J = J0 + a*W**2
二维情况下,L2是圆形,可以让解更靠近0,而不直接等于0,减少复杂性
正则化之所以能够降低过拟合的原因在于,正则化是结构风险最小化的一种策略实现。
给loss function加上正则化项,能使得新得到的优化目标函数h = f+normal,需要在f和normal中做一个权衡(trade-off),如果还像原来只优化f的情况下,那可能得到一组解比较复杂,使得正则项normal比较大,那么h就不是最优的,因此可以看出加正则项能让解更加简单,符合奥卡姆剃刀理论,同时也比较符合在偏差和方差(方差表示模型的复杂度)分析中,通过降低模型复杂度,得到更小的泛化误差,降低过拟合程度。
L1正则化和L2正则化:
L1正则化就是在loss function后边所加正则项为L1范数,加上L1范数容易得到稀疏解(0比较多)。L2正则化就是loss function后边所加正则项为L2范数的平方,加上L2正则相比于L1正则来说,得到的解比较平滑(不是稀疏),但是同样能够保证解中接近于0(但不是等于0,所以相对平滑)的维度比较多,降低模型的复杂度。
10、triplet loss
三元组损失,分别获取anchor、positive、negative三个样本,
loss = max(d(a,p)-d(a,n) + margin) , 0)
根据d不同,划分为easy , hard ,semi-hard
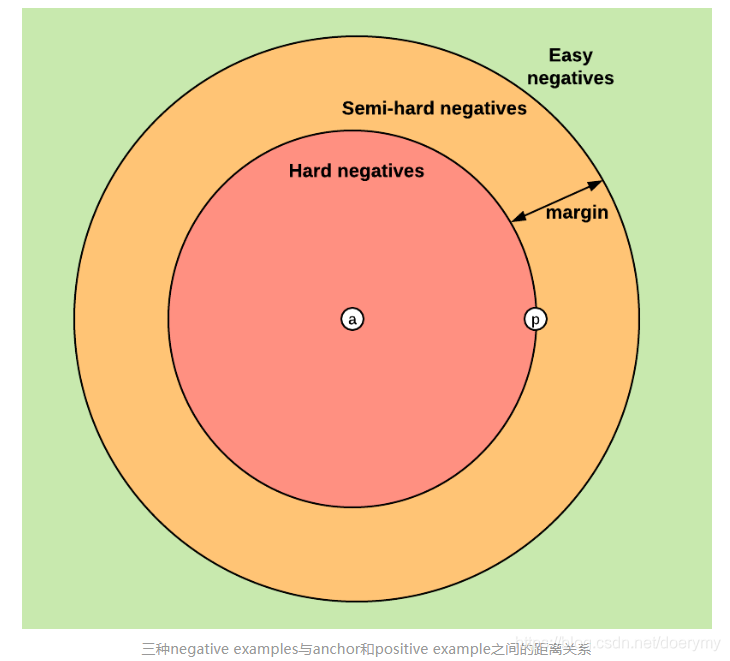
ap距离小于 an距离 ,损失为0
ap距离大于an距离+margin,有损失
11、为什么MSE不能作为分类损失函数
MSE衡量的是两个数据之间的欧式距离,在回归问题中可以使用。但在分类问题中,标签的0-1本身不是一个距离的含义,在欧式空间无意义。
MSE关注每一个类别上的概率,无论对错。CE更关注正确样本。
MSE(y,a(w*x+b))是非凸函数,存在很多局部极小值,不容易优化。

存在梯度消失的问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









