






很容易搜到下面类似的关于 MPTCP 吞吐困局的 issue:
https://github.com/multipath-tcp/mptcp_net-next/issues/437
https://github.com/multipath-tcp/mptcp/issues/150
…
我的吐槽在本文最后。
MPTCP 的 subflow 只要差异足够大,现有 Linux MPTCP 实现中,坏的 subflow 一定会拖后腿,导致 MPTCP 吞吐还不如单路径: a < a + b 2 < b a < \dfrac{a+b}{2}<b a<2a+b<b .
而这个问题看起来非常容易通过调度策略解决,以下列 T a r r i v e T_{\mathrm{arrive}} Tarrive 为 key 冒泡调度 subflow 的 MPTCP 看起来无懈可击:
T a r r i v e = T w a i t + R T T 2 = S u b f l o w Q u e u e L e n D e l i v e r y R a t e + R T T 2 T_{\mathrm{arrive}}=T_{\mathrm{wait}}+\dfrac{\mathrm{RTT}}{2}=\dfrac{\mathrm{SubflowQueueLen}}{\mathrm{DeliveryRate}}+\dfrac{\mathrm{RTT}}{2} Tarrive=Twait+2RTT=DeliveryRateSubflowQueueLen+2RTT
但现实是另一回事。
RTT 和 DeliveryRate 绝非静止在那里等着你去运算,它们总在改变。任何消除噪声的企图都只是掩耳盗铃,最后引入更多噪声。
不可消除的抖动是吞吐困局的根源,但这并不意味着问题的解决必须从处理抖动入手。
抖动的滞后感知带来决策干扰,不同 subflow 便耦合在一起,不通 subflow 的载荷几乎不可能严格顺序到达,到达时间与序列号反序交错,时间被乱序重组夺走,必然损耗吞吐。换句话说,跟的太紧,抖动引入误判,代价是时间。詹氏钩无法用于高铁也是这道理,它虽普适,但列车跑不快,而高铁车厢之间严格同步车速,消除了抖动。
前文提过 “逆序发” 和 “固定间隔发” 的调度策略,它们比以上这种启发式算法强多了。我的这些策略的不同点在于用足够远的距离做缓冲吸收抖动带来的多路径 HoL 等待,转化为明确的慢的等快的,而不是相反,本质上这就是空间换时间。通俗讲,HoL 根源在 subflow 之间抢 skb 而打架,将它们分开足够远就打不起来了。
实现又是一回事。
不单独谈锁,但下面说到固定间隔发送策略时自然就得到一种拆锁的方法。先看 MPTCP0.9x(v1 版本逻辑类似,但框架变了) 的关键实现函数 mptcp_write_xmit,以下是我保留和修改的逻辑,来自 MPTCP v0.96:
bool mptcp_write_xmit(struct sock *meta_sk, unsigned int mss_now, int nonagle,
int push_one, gfp_t gfp)
{
tcp_mstamp_refresh(meta_tp);
while ((skb = mpcb->sched_ops->next_segment(meta_sk, &reinject, &subsk,
&sublimit))) {
// 加入 sysctl_mptcp_nolimit 参数规避入 subflow senq 的没必要的检查
if (!sysctl_mptcp_nolimit && unlikely(!tcp_snd_wnd_test(meta_tp, skb, mss_now))) {
if (mpcb->sched_ops->break_call)
mpcb->sched_ops->break_call(subsk);
break;
}
// 以下类似的省略,具体参见源码但凡有 break、continue 的地方我都觉得太严格了,
// 因为只是塞入 subflow 而不是发出去,这种严格约束并不合适,
// 宽松的,全局检查是合适的,比如全局 rwnd 是否溢出等等。
// 但这里要加入自己的 subflow 准入判定逻辑(主要用于我自己的调度策略)
// 比如要确保 meta queue 始终有多个 skb 可调度,就不能让 skb 快速向 subflow 漏
if (subflow_small_queue_check(subsk, skb)) {
if (mpcb->sched_ops->break_call)
mpcb->sched_ops->break_call(subsk);
break;
}
if (!mptcp_skb_entail(subsk, skb, reinject)) {
// 如果真要 break、continue,则必须 callback scheduler 做清理
if (mpcb->sched_ops->break_call)
mpcb->sched_ops->break_call(subsk);
break;
}
// push 甚至都可以不 break
}
// 以下才是将 skb 真正推入网络,严格窗口检查在 subflow 完成更合理
mptcp_for_each_sub(mpcb, mptcp) {
__tcp_push_pending_frames(subsk, mss_now, TCP_NAGLE_PUSH);
}
return !meta_tp->packets_out && tcp_send_head(meta_sk);
}
这些部分来自思考,多数来自教训,在任何可能的且合理的场景下,meta_sk 和 subflow 之间会出现 “糊涂窗口综合症”:
- subflow-n 收到 ack 腾出 2 个 inflight,从 meta_sk 被调度的 skb 未必进入 subflow-n,造成饥饿;
- 仅在正确的调度策略(比如 v1 默认策略,见 mptcp_subflow_get_send)下,才 “发得越快的 subflow 越容易从 mata_sk 的 sk_write_queue 获得更多 skb”。
我不想让 mptcp 依赖调度策略的正确性,因此我解除了调度器和框架之间的耦合。
原始 default 策略中约束即将进入 subflow 的 subtp->snd_cwnd - inflight - unsent_inQ 精确配额限制是有问题的。要学 BBR,必须形成队列才能获得 BltBW,否则就可能陷入 SWS,subflow 退化到低吞吐。
这在 Wi-Fi 等携带 ack 聚合机制的网络中极易复现。本来 ack 就突发到达,调度策略却又倾向于保守给量,一推一避,就细水长流了。
是否将 subflow 的 cwnd 判定加入 next_segment 后 mptcp_skb_entail 前的 sub_write_queue 准入决策,毕竟调度策略允许了,cwnd 不满足,却也是百搭。我觉得不必,因为 cwnd 本身就在调度策略考量之内,回忆一下 RFC6356 的原则 3。
除此之外,net.ipv4.tcp_notsent_lowat 亦需斟酌。它的本意是通过控制 write_queue 的数据量来减少时延,但对 mptcp 而言,存在两层控制,于 meta_sk,其 write_queue 流逝速度并不直接取决于网络而取决于 subflow 的调度,于 sub_sk,其 write_queue 流逝又与应用程序无关,在 mptcp_write_xmit 时,应用程序就以为数据已经发出了。到底控制谁?
我并没有设计一个非常细致的分别针对 meta_sk 和 subsk 的 tcp_notsent_lowat 控制算法,我直接取消了对 subsk 的控制,然后仅对 meta_sk 保留 tcp_notsent_lowat 控制,理由是很简单,跟上面关于 SWS 的讨论相反,调度策略给出了决策,subsk 看 tcp_notsent_lowat 后不能否决,因为这次无关全局拥塞控制,同属本机控制,打架不好看。
说了这么多,其实意思是想说,需要换一种视角理解 mptcp xmit 的过程逻辑,我简述如下:
- 若保留现有 mptcp_write_xmit 中的限制,会导致调度策略和框架之间的决策冲突,这一点倾向于让我取消限制;
- 若不加任何限制,待发送 skb 会全部进入并挤压在 subflow,meta_sk 中没有足够的 skb 就不好施展调度,这一点倾向于增加新的限制:
- ns 级 CPU 依照调度策略取 skb 的速度比 ms 级的网络传输快几个数量级,若在将 meta_sk 的 skb 通过调度器 xmit 到 subflow 时不加限制,数据将几乎全部 “漏” 到 subflow,导致 meta sk 的 write queue len 经常仅为 1,这便无法通过 “折腾 buffer” 来完成调度,类似 BBR 也需要利用 buffer 动力学完成收敛;
- 我的调度算法有什么与众不同之处,以至于需要同时 concern 两层 write queue 的关系:
- 传统调度策略仅取 meta_sk sk_write_queue 头的 skb,抉择把它放到哪个 subflow,而我的调度策略除此之外更关注从 sk_write_queue 的哪个位置取 skb,且送进哪个subflow,多了一个维度,必有大用。既然多了一个 “位置选择” 维度,就要 meta_sk 的 sk_write_queue 中有足够的位置可选。
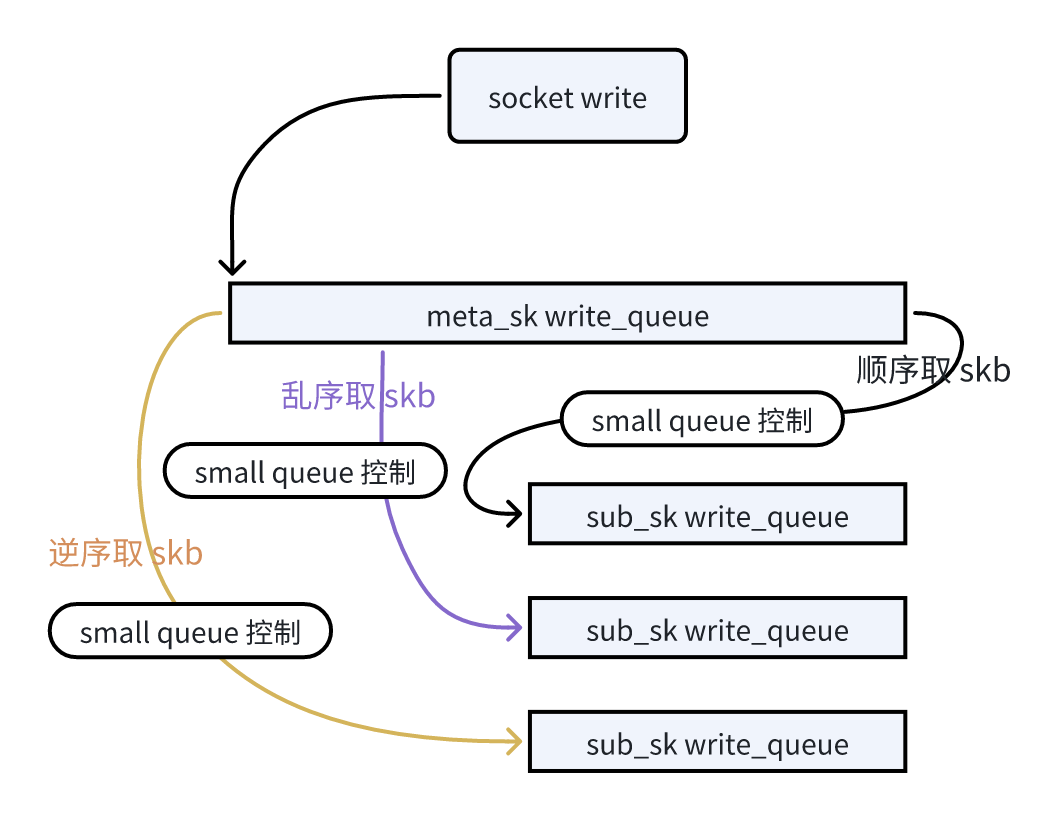
接下来看前面提到的任意两个 subflow 间解耦合的调度策略,先看固定间隔发送:
// anch 即为固定间隔,根据观察而配置,比如 30 个报文
if (T_arrive 较小) // T_arrive 见文初
skb = tcp_send_head(meta_sk);
else {
skb_queue_walk_safe(&meta_sk->sk_write_queue, skb1, tmp) {
tcb = TCP_SKB_CB(skb1);
len += skb1->len;
if (len >= anch * mss) {
skb = skb1;
break;
}
}
}
取出 skb 后,接下来在 next_segment 中依次用 skb_queue_next(&meta_sk->sk_write_queue, skb) 从该 skb 往后取 K 个,K 可以是 10,也可以是 1000,也可以是更精巧的 BDP。一旦 next_segment 的 while 循环中发生 break or continue,即要立即停止此轮取 skb 的过程,这就是我上面 mptcp_write_xmit 中那个 break_call 回调的意义。
同理,倒着逆序发的策略更简单:
if (!reverse) {
skb = tcp_send_head(meta_sk);
} else {
skb = skb_peek_tail(&meta_sk->sk_write_queue);
}
然后一路 skb_queue_prev(&meta_sk->sk_write_queue, skb) 取 skb 即可。
我起初将事情想得异常复杂,但感谢 Linux 对 sk 和 skb 的管理极其灵活简便,让我用简单几行代码就验证了想法:
- tcp_sock 维护着 meta tcp 的元数据信息,比如 snd_nxt,snd_una 等;
- sk_buff 中的 tcp_skb_cb 保存着绝对 seq 信息,与其在 write_queue 位置无关;
- sk_buff 中的 rb_node,list_head 作为 union,rb_insert 到 rtx_queue 前从 write_queue 中 unlink 即可;
以上这一切都在 mptcp_save_dss_data_seq,tcp_event_new_data_sent 等函数中自动完成,什么都不需要改。
整个图景如下:
现在看并行的问题,这仍然是个锁的问题。
前文提到过 mptcp “几乎” 无法做到 subflow 并行,即便是 v1 版本也只能尽量优化,这在本质上是因为 TCP 就是串行流。带宽越大,subflow 越多,lock 热点越大。
说到底 mptcp 是不可扩展的,路径越多,带宽越大,主机核数越多,吞吐越难以叠加。那么就用空间换时间就是最佳优化方案。
开辟一片固定大内存做 send buffer,meta_sk 的 sk_write_queue 部署其中,内存地址按固定 block 大小分为 N 块,subflow 按照其内存地址 mod N 即可获得自己要发送的 block,如此一来,所有 subflow 之间的互斥就转为了每个 subflow 和 meta_sk 的互斥。热点与 subflow 数量无关,从而获得了扩展性。
人总是有种执念,以为通过努力事情的发展总朝向自己预期,对随机却是无情地鄙视。希望各个 block 尽可能顺序到达,当然这是最好的,但又回到了启发式,subflow 按照从差到好的顺序从尾部往前部取 block 发送即可,话虽简单,但如何定义 subflow 的 “好” 和 “差” 便体现了启发的本意,即使不必太精确,也大概率会弄巧成拙,虽数学论证好看,却还是不如直接 hash 来得更极简主义般美观。问题在于 RTT 多大程度上是可信赖的,当它的可信度低于一定底线,与其在混乱中挣扎,不如交给随机。
推荐一个学习资料:Measuring and extending multipath TCP
最后,表达一些想法。关于 TCP 优化,TCP 加速,传输协议优化,传输协议优化等各种优化,加速的概念,职位,大会 topic 在最近十多年经久不衰,在 MPTCP 之前,经理们往往从魔改 TCP 拥塞控制算法入手,歪曲拥塞控制的含义,使之走向邪恶的反面。
事情如此大概率只是因为 Linux 将拥塞控制模块化并暴露出来接口,实现这些接口回调函数函数是一件非常简单毫无门槛的事,而经理们所做的事也往往就是 cwnd += …,cwnd *= … 这种可以让直连拓扑 iperf 吞吐立竿见影的事。
另一方面,经理们大概也只懂 Linux 内核模块,换到 Windows 平台,几乎没听说过用拥塞控制算法做协议加速的事,我这么资深的协议加速工人有幸前段时间试图在 Windows 做加速,没有成功。看准了吧,Windows 人家有自己的圈子,人家在看雪论坛也是论资排辈的。
当 cwnd,pacing_rate,魔改 BBR 再也挤不出性能,再也折腾不动的时候,经理们找几个博士校企合作水论文就成了另一个方向,总之都是无法部署的实验室效果,实战中还得是 cubic。
有了 MPTCP 之后,一条 TCP 连接实现 N 倍吞吐是多么吸引人,这种 NX(N 倍速,牛逼~) 效果对 cwnd +±- 绝对是降维打击,和经理们拿拥塞控制做加速一样,RFC6356 无人问津。我们假设,仅仅只是假设,MPTCP 的 subflow 吞吐真的可以任意线性叠加,互联网会堵成什么样子,站在拥塞控制的立场,MPTCP 的吞吐困局反而是一件好事,Linux MPTCP 的性能缺陷反而不自觉地自动实现了 RFC6356 原则 2,保留了原则 1 和原则 3 做 bugfix TODO:
o Goal 1 (Improve Throughput) A multipath flow should perform at least as well as a single path flow would on the best of the paths available to it.
o Goal 2 (Do no harm) A multipath flow should not take up more capacity from any of the resources shared by its different paths than if it were a single flow using only one of these paths. This guarantees it will not unduly harm other flows.
o Goal 3 (Balance congestion) A multipath flow should move as much traffic as possible off its most congested paths, subject to meeting the first two goals.
这就非常有趣了。
浙江温州皮鞋湿,下雨进水不会胖。

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









