






一、torch.numel() 函数
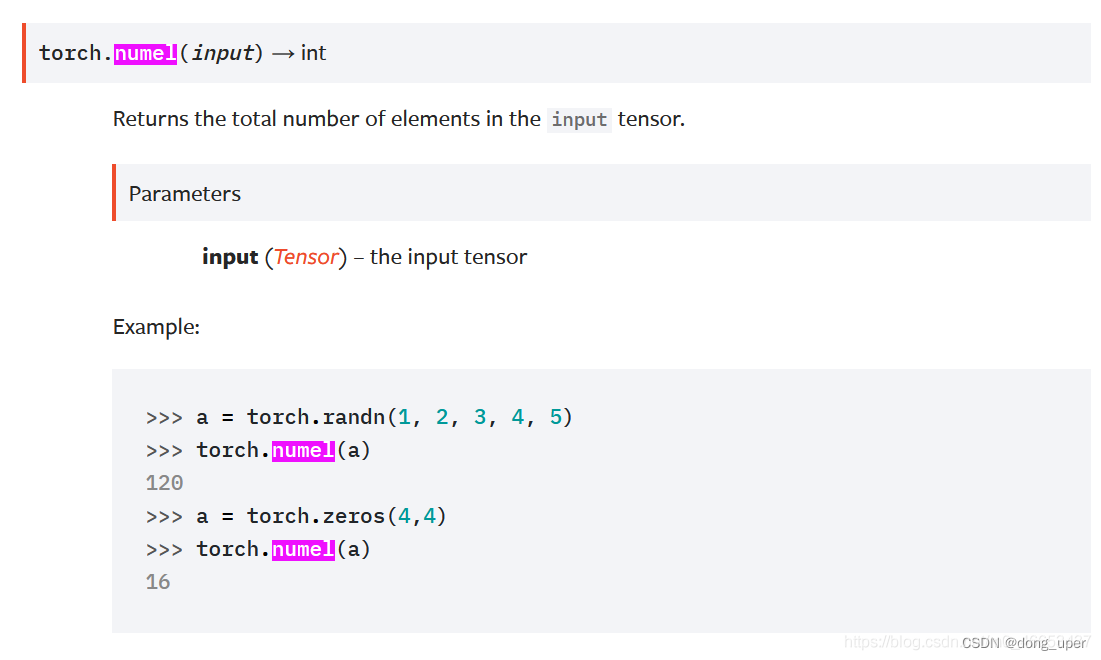
计算给出输入张量input的元素总数
二、实用程序类Accumulator使用
class Accumulator:
#在n个变量上累加
def init(self, n):
*self.data = [0.0] * n
def add(self, args):
for a, b in zip(self.data, args):
self.data = [a + float(b) for a,b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def getitem(self, idx):
return self.data[idx]
__init__ 初始化函数根据输入的参数n,来创建n个变量,且初始化数据类型为float,数值大小为0 。
add 函数,*args代表这里可以传入任意个参数,但是因为要和初始化的个数相同不然要报错。for a,b in zip(self.data,args)是把原来类中对应位置的data和新传入的args做 a + float(b)加法操作然后重新赋给该位置的data。从而达到累加器的累加效果。
reset 函数,数据data的初始化。
__getitem__ 实现类似数组的取操作。
参考链接:https://blog.csdn.net/weixin_44556141/article/details/120116161
三、backward()方法自动求梯度的使用
1、区分源张量和结果张量
x = torch.arange(-8.0, 8.0, 0.1, requires_grad= True)
y = x.relu()
x为源张量,基于源张量x得到的张量y为结果张量。
2、如何使用backward()方法自动求梯度
一个标量调用它的backward()方法后,会根据链式法则自动计算出源张量的梯度值。
2.1、结果张量是一维张量
基于以上例子,就是将一维张量y变成标量后,然后通过调用backward()方法,就能自动计算出x的梯度值。
那么,如何将一维张量y变成标量呢?
一般通过对一维张量y进行求和来实现,即y.sum()。
一个一维张量就是一个向量,对一维张量求和等同于这个向量点乘一个等维的单位向量,使用求和得到的标量y.sum()对源张量x求导与y的每个元素对x的每个元素求导结果是一样的,最终对源张量x的梯度求解没有影响。
因此,代码如下:
y.sum().backward()
x.grad
2.2、结果张量是二维张量或更高维张量
撇开上面例子,结果变量y可能是二维张量或者更高维的张量,这时可以理解为一般点乘一个等维的单位张量(点乘,是向量中的概念,这样描述只是方便理解),代码如下:
y.backward(torch.ones_like(y))#grad_tensors=torch.ones_like(y)
x.grad
参考链接:https://blog.csdn.net/Mr____Cheng/article/details/118420367
四、enumerate() 函数使用
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
实例
以下展示了使用 enumerate() 方法的实例:

更改默认下标为1

普通的 for 循环

for 循环使用 enumerate

参考链接:https://blog.csdn.net/qq_29893385/article/details/84640581
五.print语句中f和r的作用
1.python输出函数加上r的作用:即print(r" ")
主要的原因是为防止转义,保证r后面的内容全文输出。
r就是保持字符串原始值的意思,在我们输入路径的时候,总会出现斜杠“\”,这个符号在python语言中具有转义的作用,加上r就是避免转义,直接原文输出。
2.python输出函数加上f的作用:即print(f" ")
主要作用就是格式化字符串,加上f以后,{“变量/表达式”},花括号里的变量和表达式就可以使用了。
举个例子,体会一下:
for i in range(9):
print(f"本次循环输出值的平方为:{i*i}")
参考链接:https://blog.csdn.net/sy20173081277/article/details/107935670
六.zip函数的使用
1.1 描述
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。
我们可以使用list()转换来输出列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
1.2 语法
zip([iterable, …])
参数说明:
iterable – 一个或多个迭代器;
1.3 返回值
返回一个对象。
1.4 例子
a = [1, 2, 3]
b = [4, 5, 6]
c = [7, 8, 9, 10, 11, 12]
zip_object = zip(a, b)
zip_object
<zip object at 0x0000019643D74D40> # 可以看到,zip的返回值是一个对象
解包的两种方式
方法1
list(zip_object)
[(1, 4), (2, 5), (3, 6)]
list(zip(a, c))
[(1, 7), (2, 8), (3, 9)]
方法2
print(*a)
1 2 3
print(*zip_object)
一般用法
for i, j in zip(a, b):
… print(f"i: {i}, j: {j}")
…
i: 1, j: 4
i: 2, j: 5
i: 3, j: 6
一般zip()函数用于我们想同时处理两个列表里的数据。
a = [1, 2, 3]
b = [4, 5, 6]
c = [7, 8, 9, 10, 11, 12]
for i, j in zip(a, b):
print(f"i: {i}, j: {j}")
“”"
i: 1, j: 4
i: 2, j: 5
i: 3, j: 6
“”"
for x,y,z in zip(a, b, c):
print(f"x: {x}, y: {y}, z: {z}")
“”"
x: 1, y: 4, z: 7
x: 2, y: 5, z: 8
x: 3, y: 6, z: 9
“”"
参考链接:https://blog.csdn.net/qq_42958831/article/details/127920475
七.hasattr()函数
Python hasattr() 函数
描述
hasattr() 函数用于判断对象是否包含对应的属性。
语法
hasattr 语法:
hasattr(object, name)
参数
object --对象
name–字符串,属性名
返回值
如果对象有该属性,返回 True, 否则返回 False。
实例
class Coordinate:
x = 10
y = -5
z = 0
point1 = Coordinate()
print(hasattr(point1, ‘x’))
print(hasattr(point1, ‘y’))
print(hasattr(point1, ‘z’))
print(hasattr(point1, ‘no’)) # 没有该属性
输出结果:
True
True
True
False















 1132
1132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









