







Information comes from Standford machine learning course by Andrew Ng
1. Multi-variate Bernoulli event model
这个模型首先判断出先验概率p(y),再计算p(xi=1|y),最后是后验概率。以下是详细步骤:
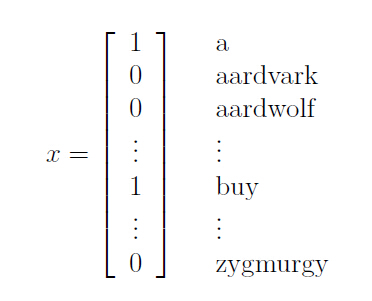
(1)We represent a document via a feature vector whose length is equal to
the number of words in the dictionary. feature向量中给的是dictionary中的词是否出现,出现即为1,不出现为0. feature的size是dictionary的大小。
(2)Naive Bayes (NB) assumption,即To model p(x|y), the xi’s are conditionally independent given y.
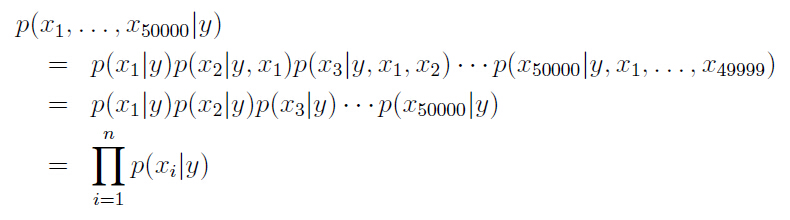
(3)当我们需要预测一个new example with features x 的label时,需要用
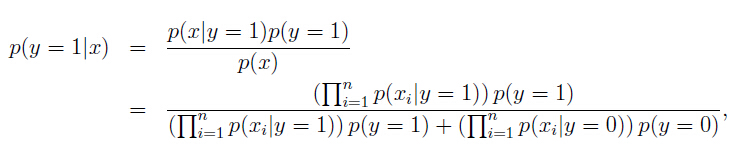
哪个label得到的后验概率最大就判定其为哪一类。
那么就需要计算其中的参数。如下:

(4)由于参数估计中有许多零值,导致最大似然估计不能用。可采用Laplace smoothing
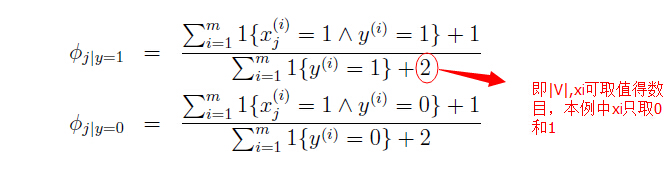
2. Multinomial event model
该模型和上面的和类似,但在构建feature的时候有差别。document被表示成 document中words组成的 vector (x1,x2, ..., xn),xi表示an integer taking values in {1, ..., |V|},即在dictionary中的位置, 现在|V|是dictionary size.那么feature的大小n对每个docuemnt是变动的。
其直观解释是:writer of the document先给出先验概率p(y),然后再决定先写哪个词x1,再写哪个词x2,以此类推。每个词虽然独立,但是来自同一个multinomial distribution.最终得到和上一个model一样的计算结果,但是 xi|y 是一个multinomial,而不是Bernoulli distribution.
(1)参数估计

(2) Laplace smoothing
















 1112
1112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









