









问题:
使用tf.distribute.MirroredStrategy时,在windows系统多卡下出现No OpKernel was registered to support Op 'NcclAllReduce'问题(Linux下正常),具体报错信息如下:
tensorflow.python.framework.errors_impl.InvalidArgumentError: No OpKernel was registered to support Op 'NcclAllReduce' used by {{node training/Adam/NcclAllReduce}}with these attrs: [reduction="sum", T=DT_FLOAT, num_devices=2, shared_name="c0"]
Registered devices: [CPU, GPU]
Registered kernels:
<no registered kernels>
[[training/Adam/NcclAllReduce]] [Op:__inference_keras_scratch_graph_2200]原因:
tf.distribute.MirroredStrategy默认使用NCCL进行多卡并行,但官方NCCL不支持windows,可以找非官方的windows NCCL或弃用NCCL。
解决:
对于tf1:
nccl is only useful if there are GPU to GPU connections available in your setup. Is that the case? If yes, you could try finding a nccl binary for Windows.
If not, then it would be better to try some of the non nccl options. To get those, try the following:
Option 1:
Try using hierarchical copy.
cross_tower_ops = tf.contrib.distribute.AllReduceCrossTowerOps(
'hierarchical_copy', num_packs=num_gpus))
strategy = tf.contrib.distribute.MirroredStrategy(cross_tower_ops=cross_tower_ops)
Option 2:
Reduce to first GPU:
cross_tower_ops = tf.contrib.distribute. ReductionToOneDeviceCrossTowerOps()
strategy = tf.contrib.distribute.MirroredStrategy(cross_tower_ops=cross_tower_ops)
Option 3:
Reduce to CPU:
cross_tower_ops = tf.contrib.distribute. ReductionToOneDeviceCrossTowerOps(
reduce_to_device="/device:CPU:0")
strategy = tf.contrib.distribute.MirroredStrategy(cross_tower_ops=cross_tower_ops)
You will have to try out the 2 approaches and see which one works and gives the best performance for your use case.
@yuefengz - for use cases like this, perhaps we should detect if nccl is not available, give a warning, and default to something else that will work for sure?
参考:NCCL is not supported on Windows · Issue #21470 · tensorflow/tensorflow (github.com)
对于tf2:
tf2中cross_tower_ops 升级为 cross_device_ops,参考链接
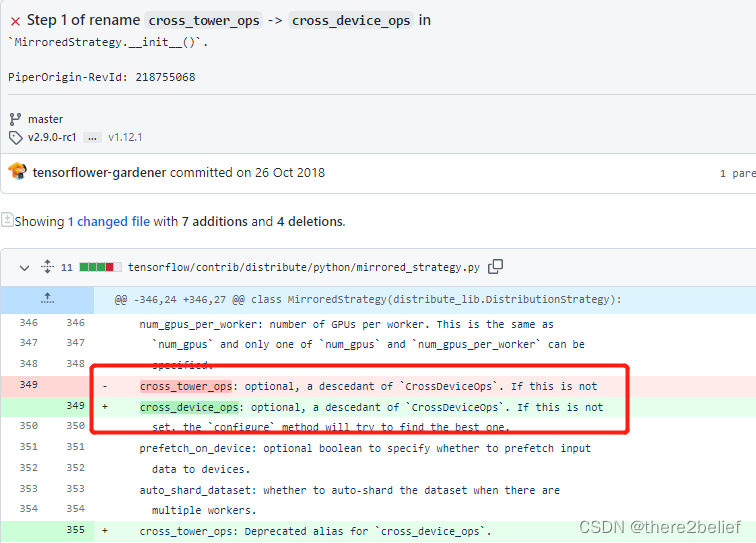
此时上述解决方案的选项1,在tf2中使用会遇到模块找不到的问题,需要更新为:
cross_tower_ops = tf.distribute.HierarchicalCopyAllReduce()
strategy = tf.distribute.MirroredStrategy(cross_device_ops=cross_tower_ops)















 263
263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









