










 MiniGPT-4是由阿卜杜拉国王科技大学的博士开发的开源项目,它模仿GPT-4的多模态功能,通过结合冻结的视觉编码器和Vicuna大模型实现。该模型能进行图像描述生成、问题解答和创新任务,如根据食物照片教做饭。文章介绍了模型结构、微调过程、环境搭建步骤以及模型检查点的下载和配置,适合技术爱好者尝鲜。
MiniGPT-4是由阿卜杜拉国王科技大学的博士开发的开源项目,它模仿GPT-4的多模态功能,通过结合冻结的视觉编码器和Vicuna大模型实现。该模型能进行图像描述生成、问题解答和创新任务,如根据食物照片教做饭。文章介绍了模型结构、微调过程、环境搭建步骤以及模型检查点的下载和配置,适合技术爱好者尝鲜。
一、MiniGPT-4尝鲜
还在苦苦等待GPT-4开放?开源项目MiniGPT-4就能提前体验类似GPT-4的多模态对话功能。
2023年4月17日,多模态问答模型MiniGPT-4发布,实现了GPT-4里的宣传效果
《MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models》
阿卜杜拉国王科技大学的几位博士(看名字都是中国人)开发,他们认为GPT-4 先进的多模态生成能力,主要原因在于利用了更先进的大型语言模型。
为了验证这一想法,团队成员将一个冻结的视觉编码器(Q-Former&ViT)与一个冻结的 文本生成大模型(Vicuna,江湖人称:小羊驼) 进行对齐,造出了 MiniGPT-4。
- MiniGPT-4 具有许多类似于 GPT-4 的能力, 图像描述生成、从手写草稿创建网站等
- MiniGPT-4 还能根据图像创作故事和诗歌,为图像中显示的问题提供解决方案,教用户如何根据食物照片做饭等。
二、模型介绍
2.1 模型结构介绍
- 投影层(Projection Layer)是神经网络中常见层类型,将输入数据从一个空间映射到另一个空间。
- NLP中,投影层通常用于将高维词向量映射到低维空间,以减少模型参数数量和计算量。
- CV中,投影层可以将高维图像特征向量映射到低维空间,以便于后续处理和分析。
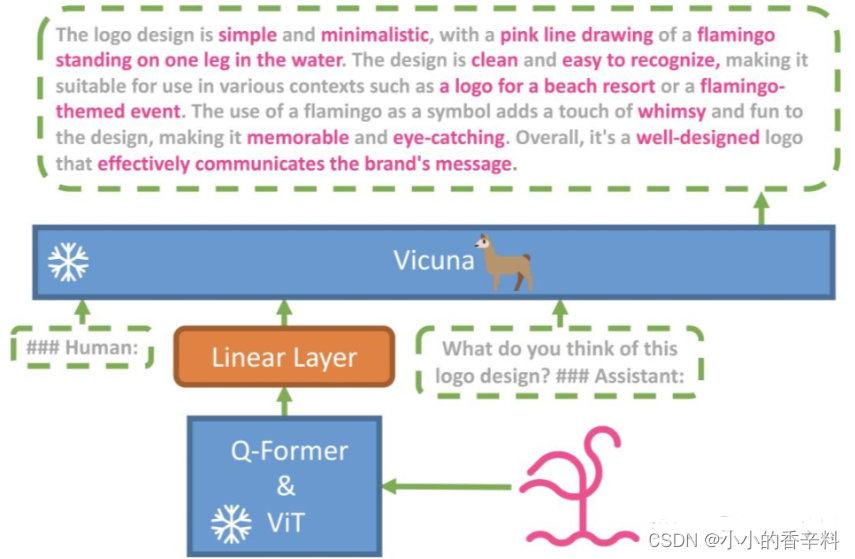
2.2 fine tune介绍
- 先是在 4 个 A100 上用 500 万图文对训练
- 然后再用一个小的高质量数据集训练,单卡 A100 训练只需要 7 分钟。
2.3 模型效果介绍
在零样本 VQAv2 上,BLIP-2 相较于 80 亿参数的 Flamingo 模型,使用的可训练参数数量少了 54 倍,性能提升了 8.7 %。
三、环境搭建
3.1 克隆仓库
git clone https://github.com/Vision-CAIR/MiniGPT-4.git3.2 构建环境
cd MiniGPT-4
conda env create -f environment.yml
conda activate minigpt4四、MiniGPT-4模型下载
4.1 Vicuna Weight的working weight构建
参考:【LLMs系列】90%chatgpt性能的小羊驼Vicuna模型学习与实战_小小的香辛料的博客-CSDN博客
4.2 配置模型路径
修改minigpt4/configs/models/minigpt4.yaml第16行代码,改成vicuna的权重。
例:
model:
arch: mini_gpt4
# vit encoder
image_size: 224
drop_path_rate: 0
use_grad_checkpoint: False
vit_precision: "fp16"
freeze_vit: True
freeze_qformer: True
# Q-Former
num_query_token: 32
# Vicuna
llama_model: "chat/vicuna/weight" # 将 "/path/to/vicuna/weights/" 修改为本地 weight 地址
...
五、准备MiniGPT-4 checkpoint
5.1下载MiniGPT-4 checkpoint
1.下载 MiniGPT-4 checkpoint
- 方法一:从 google drive 下载
- Checkpoint Aligned with Vicuna 13B: https://drive.google.com/file/d/1a4zLvaiDBr-36pasffmgpvH5P7CKmpze/view?usp=share_link
- Checkpoint Aligned with Vicuna 7B: https://drive.google.com/file/d/1RY9jV0dyqLX-o38LrumkKRh6Jtaop58R/view?usp=sharing
- 方法二:huggingface 平台下载
- prerained_minigpt4_7b.pth:wangrongsheng/MiniGPT4-7B at main
- pretrained_minigpt4.pth:wangrongsheng/MiniGPT4 at main
2.在 eval_configs/minigpt4_eval.yaml 的 第11行 设置 MiniGPT-4 checkpoint 路径
model:
arch: mini_gpt4
model_type: pretrain_vicuna
freeze_vit: True
freeze_qformer: True
max_txt_len: 160
end_sym: "###"
low_resource: True
prompt_path: "prompts/alignment.txt"
prompt_template: '###Human: {} ###Assistant: '
ckpt: '/path/to/pretrained/ckpt/' # 修改为 MiniGPT-4 checkpoint 路径
...5.2 在本地启动MiniGPT-4
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0注:为了节省GPU内存,Vicuna默认加载为8位,波束搜索宽度为1。这种配置对于Vicuna 13B需要大约23G GPU内存,对于Vicuna7B需要大约11.5G GPU内存。对于更强大的GPU,您可以通过在配置文件minigpt4_eval.yaml中将low_resource设置为False以16位运行模型,并使用更大的波束搜索宽度。
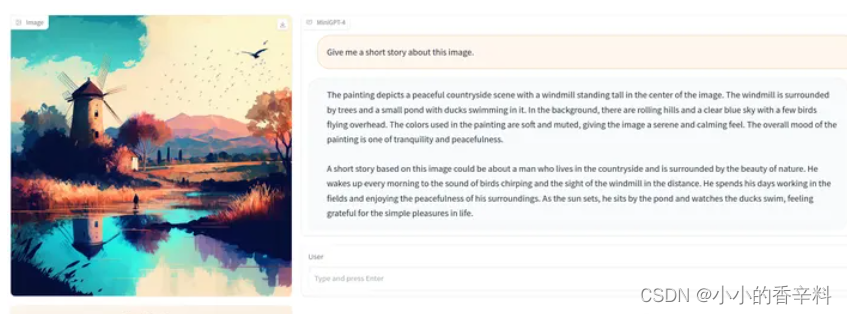
本节就先到这!


















 2594
2594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











