








寒假在家真是无聊透顶,天气又冷,整天只能躺在床上睡觉、玩游戏。出于好玩,偶然间看到一篇有趣的博客“python实现自动定时给女朋友发手机短信,每天一个笑话!”
https://blog.csdn.net/qq_41841569/article/details/83111712
哈哈哈,有趣!
(建议先看这篇博客)。博主是个幽默风趣的大学生,受到他的感染,我打算自己动过手实现一下并完善一些内容,让大家了解的更加透彻,使代码能够直接用(这不,情人节到了,造福大家)。整个内容分为两个部分:爬取笑话、发送信息。

爬取笑话
这里主要是爬取“ZOL笑话大全”网页上的最新笑话
(http://xiaohua.zol.com.cn/new/),如下图:
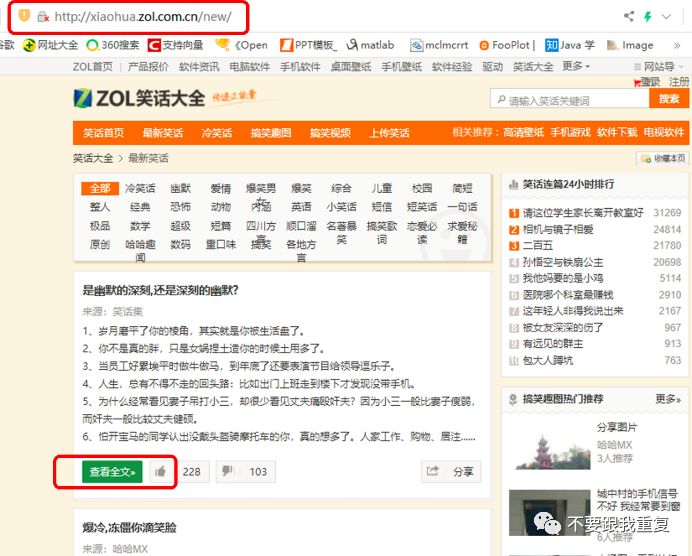
该页面中分块显示了最近更新的笑话,通过点击“查看全文”即可查看完整的笑话。在开始爬取之前,最好仔细看看各链接URL的特征,这能很大程度简化爬取过程。像这个页面中,“查看全文”的链接分别如下:
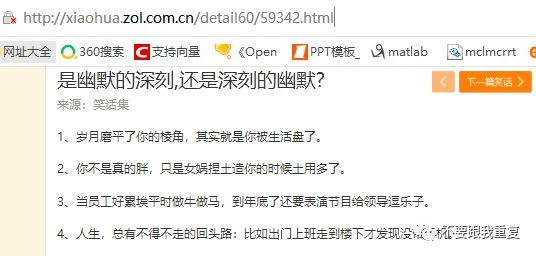
http://xiaohua.zol.com.cn/detail60/59342.html
http://xiaohua.zol.com.cn/detail60/59341.html
http://xiaohua.zol.com.cn/detail60/59340.html
http://xiaohua.zol.com.cn/detail60/59339.html
···················
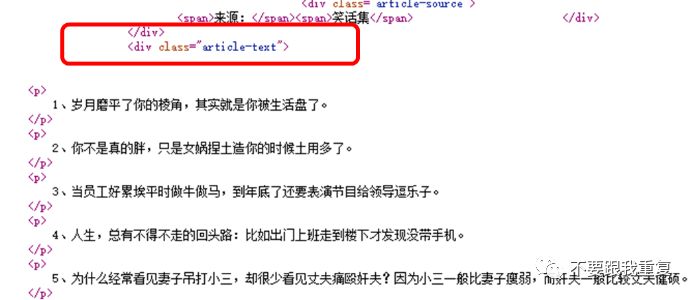
可以看到每个URL前面都是http://xiaohua.zol.com.cn/detail60/,后面接着序列号(如59342,依次递减)。所以我们爬取笑话是可以直接定位到这样的网页上来,极大地省去了很多繁琐的步骤(URL提取、筛选等)。找到对应目标页面后,还需进一步提取信息得到仅含笑话的文本文档。以http://xiaohua.zol.com.cn/detail60/59342.html这个网页为例,通过查看网页源代码,发现所有的笑话都在<div class=”article-text”>这个区块里,每个笑话之间用</p><p>分割,见下图:
值得注意的是,这个网站具有反爬虫机制,不能直接爬取(运行几次代码后就会报错),需要模拟成“人为的浏览网页”。对于无反爬虫机制的网页可以直接用html = urlopen(url)打开(url为网页链接),而爬取“ZOL笑话大全”这个网页时需要换一种方式(加上平台、浏览器等信息)如下:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0;WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75Safari/537.36'}
req = Request(url=url, headers=headers)
html = urlopen(req)小技巧:对于有反爬虫机制的网页来说,建议把要分析的网页保存在本地,爬取保存本地的网页。先把代码里面的爬取逻辑搞懂,代码弄通,然后再爬取浏览器上的网页。(像我这样的小白,写代码时会时不时运行调试,但这网页运行太频繁就会报错,自己还不知道原因,搞得焦头烂额。。。)
from urllib.request import urlopen,Request
from urllib.error
import HTTPError
from bs4 import BeautifulSoupdef
GetLink(url):
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'}
req = Request(url=url, headers=headers)
html = urlopen(req)
except HTTPError as e:
return None
try:
bsObj = BeautifulSoup(html.read(),"html.parser",from_encoding="GBK")
title = bsObj.find("div",class_="article-commentbar articleCommentbar clearfix")
return title['data-id']
except AttributeError as e:
return None
def GetDownloadLink(url):
list1 = []
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'}
req = Request(url=url, headers=headers)
html = urlopen(req)
except HTTPError as e:
return None
try:
bsObj = BeautifulSoup(html.read(),"html.parser",from_encoding="GBK")
title = bsObj.find("div",class_="article-text").find_all('p')
for i in range(len(title)):
title[i] = title[i].get_text().strip()
if len(title[i]) > 0:
list1.append(str(title[i]))
return list1
except AttributeError as e:
return None
return None
if __name__ == '__main__':
LinkNum = GetLink("http://xiaohua.zol.com.cn/new/")
print(LinkNum)
if LinkNum == None:
print("Link could not be found!")
else:
Link = 'http://xiaohua.zol.com.cn/detail60/'+LinkNum+'.html'
result = GetDownloadLink(Link)
print(result)爬取结果:

发送信息
我是运用Python调用第三方 SMTP 服务发送电子邮件(模仿那篇博客),这里我是调用163邮箱的SMTP服务(也可以用qq)。在写代码之前要做一些准备,要不然接二连三的bug会把你搞疯。(我是差点要摔电脑了 (灬ꈍ ꈍ灬))
① 开启SMTP服务
这可以参考这个,讲的很清楚:
(https://jingyan.baidu.com/article/7f41ecec3e8d35593d095c93.html)
值得注意的是,开启服务时,你会得到(设置)一个授权码,这个很重要,这就是Python调用163邮箱SMTP服务的密码!!!(记住!)
② 查看“网络和共享中心网络连接详细信息”中的“连接特定的 DNS 后缀”,确保为“HOST”
这可以参考下面这篇博客中的“常见错误汇总”,里面还讲了其他常见问题,很仔细!
“python发送邮件详解”
(https://blog.csdn.net/qq_32890891/article/details/80071512)
整个代码逻辑不难,但一疏忽就会出很多问题。 (我很想哭o(╥﹏╥)o)
# **************是自己要填的参数 import smtplib from email.mime.text import MIMEText mail_host = "smtp.163.com" # SMTP服务器 mail_user = "**************" # 用户名 mail_pass = "**************" # 密码,是那个授权码!!! sender = "**************" # 发件人邮箱(最好写全, 不然会失败) receivers = ["**************"] # 接收邮箱,可以写多个content = "**************"#邮件内容 title = "**************" # 邮件主题 message = MIMEText(content, 'plain', 'utf-8') # 内容, 格式, 编码 message['From'] = "{}".format(sender) message['To'] = ",".join(receivers)#将多个地址链接message['Subject'] = titletry: smtpObj = smtplib.SMTP_SSL(mail_host, 465) # 启用SSL发信 smtpObj.login(mail_user, mail_pass) # 登录验证 smtpObj.sendmail(sender, receivers, message.as_string()) # 发送 print("mail has been send successfully.") except smtplib.SMTPException as e: print(e)
在测试代码时,不要发内容重复的邮件,要不然代码可能会出错。这不是代码的问题,而是由于你频繁发送,第三方服务会判定你的邮件为垃圾邮件,从而拒绝你的发送申请,使邮件发不出去。最后测试结果如下:

接着就是定时发送了,这个呢,我们可以用电脑自带的定时任务,每天定时执行Python脚本,这样更加简单点,而且不用一直运行脚本。可以参考这篇博客:
“怎样在windows上定时执行python脚本”
https://www.cnblogs.com/zz0eyu/p/9584000.html
到现在,各部分的代码都搞定了,剩下的就是整合代码了。本想一口气把剩下的都弄出来的,但一想,我又没有女朋友!!! 搞出来不是刺激自己吗?(⊙o⊙)…剩下的其实很简单了,只需要稍微改一下代码就行。最后祝大家情人节玩的开心(*^▽^*)!!!
PS:(文章是自己早期写的,还蛮有趣的,哈哈哈,现在搬到CSDN上,乐一乐)















 517
517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









