










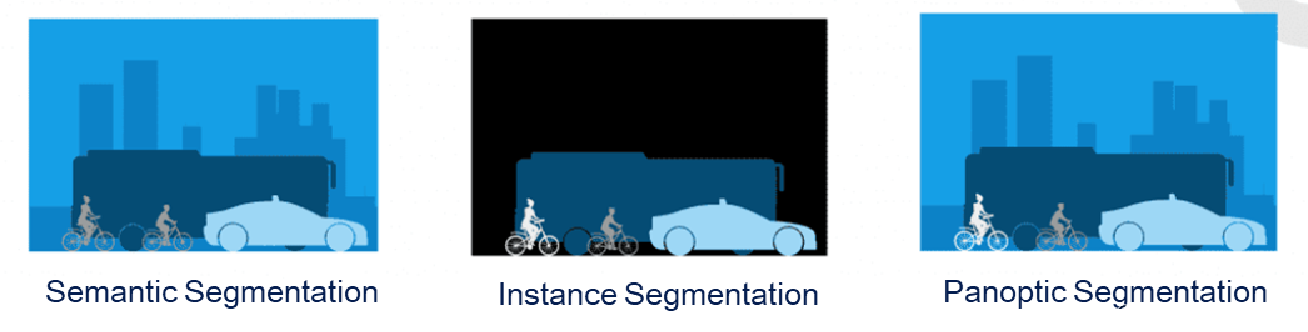
语义分割(Semantic Segmentation)、实例分割(Instance Segmentation)和全景分割(Panoptic Segmentation)是图像分割领域中的三个重要任务,它们有着不同的目标和应用。下面是它们之间的区别:
-
语义分割:
- 目标:将图像中的每个像素分类到预定义的语义类别中,例如道路、汽车、行人等。在语义分割中,重点是对整个图像进行像素级别的分类。
- 输出:生成一个与输入图像具有相同分辨率的分割结果图,其中每个像素被标记为对应的类别。
-
实例分割:
- 目标:将图像中的每个个体对象分割出来,并为每个对象赋予唯一的标识。实例分割不仅需要识别每个对象的类别,还需要区分不同对象之间的实例。
- 输出:生成一个与输入图像具有相同分辨率的分割结果图,其中每个像素被标记为对应的对象实例,并且每个实例具有不同的标识。
-
全景分割:
- 目标:结合了语义分割和实例分割的概念,旨在同时提供像素级别的语义信息和对象级别的实例信息。全景分割要求对图像进行像素级别的分类,并为每个对象实例分配唯一的标识。
- 输出:生成一个与输入图像具有相同分辨率的分割结果图,其中每个像素被标记为对应的类别,并且每个对象实例具有不同的标识。
语义分割关注的是对图像进行像素级别的分类,实例分割不仅分类,还要区分不同对象之间的实例,而全景分割既提供像素级别的语义信息,又提供对象级别的实例信息。这些技术在计算机视觉领域有广泛的应用,如自动驾驶、图像理解、医学图像分析等。
这三种图像分割技术在计算机视觉和图像处理领域具有重叠的应用。它们共同提供了许多实际应用,帮助人类增加认知的维度。
一些语义分割和实例分割的实际应用包括:
1、自动驾驶车辆:3D语义分割使车辆能够通过识别道路上的不同物体更好地理解环境。同时,实例分割可以识别每个物体实例,提供更深入的计算速度和距离所需的信息。
2、医学扫描分析:这两种技术可以在MRI、CT和X光扫描中识别肿瘤和其他异常。
3、卫星或航空图像:这两种技术提供了一种从太空或高空绘制地图的方法。它们可以描绘出河流、海洋、道路、农田、建筑物等世界上的物体。这类似于它们在场景理解中的应用。
全景分割将自动驾驶车辆的视觉感知提升到了一个新的水平。它产生了像素级准确性的细粒度掩膜,使自动驾驶汽车能够做出更准确的驾驶决策。此外,全景分割在医学图像分析、数据注释、数据增强、无人机遥感、视频监控和人群计数等领域也越来越多地应用。在所有领域中,全景分割在预测掩膜和边界框时提供了更深入和准确的信息。


















 1247
1247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











