







一、实验目的
- 掌握word2vec模型的构建及训练;
- 掌握LSTM和GRU模型的构建及文件生成;
- 使用Python语言对数据集进行预处理、封装、训练及预测,最后达到社会网络舆情分析的目的;
二、实验内容
1. 准备数据:根据斯坦福大学发布的情感分析数据集,进行预处理,向量化表示,最后模型训练及预测情感分类;
原始数据处理.py
import pandas as pd
import numpy as np
import random
import json
from tqdm.notebook import tqdm
random.seed(2022)
# 数据分组
def split_list(split_list, rates=[]):
split_target = split_list.copy()
assert np.array(rates).sum() == 1
split_len = [int(r * len(split_list)) for r in rates]
split_result = list()
for index, length in enumerate(split_len):
if index >= len(split_len) -1:
split_result.append(split_target)
continue
split_ = random.sample(split_target, length)
split_result.append(split_)
split_target = [data for data in split_target if data not in split_]
return split_result
def prepare_sst_data():
sst_datasets = list()
data_sentence_name = r'./datasetSentences.txt'
data_sentence = pd.read_csv(data_sentence_name, delimiter = '\t', header=0)
dictionary_name = r'./dictionary.txt'
dic = pd.read_csv(dictionary_name, delimiter='|', header=None)
dic_maps = {k: v for k, v in zip(dic[0], dic[1])}
label_file = r'./sentiment_labels.txt'
label_info = pd.read_csv(label_file, delimiter='|', header=0)
label_map = {k: v for k, v in zip(label_info['phrase ids'], label_info['sentiment values'])}
for sentence in tqdm(data_sentence['sentence']):
if sentence not in dic_maps:
continue
label = label_map[dic_maps[sentence]]
label = 0 if float(label) < 0.5 else 1
sst_datasets.append({'sentence': sentence,"label": label})
[train, test] = split_list(sst_datasets, [0.8, 0.2])
return sst_datasets, train, test
sst_datasets, train_data, test_data = prepare_sst_data()
dataset_radio = lambda dataset: round(np.array([label['label'] for label in dataset]).sum() / len(dataset), 4)
print(f'postive in sst_datasets = {dataset_radio(sst_datasets)}, total={len(sst_datasets)}')
print(f'postive in train = {dataset_radio(train_data)}, total={len(train_data)}')
print(f'postive in test = {dataset_radio(test_data)}, total={len(test_data)}')
print(f'train_data[0]={train_data[0]}')wprd2vec.py
from gensim.models.word2vec import Word2Vec
import pandas as pd
import time
from 原始数据处理 import prepare_sst_data
sst_datasets, train_data, test_data = prepare_sst_data()
# 分词并去停用词
def split_words(sentences: str):
stop_words = ['', 'the', ',', 'a', 'of', 'an', 'at', 'is', 'it', 'in', 'as', "'s", '.', '(', ')', "'", '...', '--', '``', "''", "''"]
words = sentences.split(' ')
return [word.lower() for word in words if word.lower() not in stop_words]
all_sentences = [split_words(data['sentence']) for data in sst_datasets]
print(f'all_sentences[0:2]={all_sentences[0:2]}')
#训统word2vector词嵌入模型
print(f'{time.ctime()}: 开始训练word2vector模型')
word2vector = Word2Vec(all_sentences, vector_size=100, min_count=5, epochs=200, sg=0)
print(f'{time.ctime()}: word2vector模型训练结束')
# 保存词向量模型
W2V_TXT_FILE = 'word2vector_23.txt'
word2vector.wv.save_word2vec_format(W2V_TXT_FILE)
#根据word2vector模型查看和movie相近的词
print(f'和movie相近的词如下: ')
for i in word2vector.wv.most_similar("movies"):
print('--->', i[0], i[1])dataset.py
# from torchtext import data
# from torchtext import data
from torchtext.legacy import data
from torchtext.vocab import Vectors
from torch.nn import init
from tqdm import tqdm
import pandas as pd
from Word2Vector import split_words,W2V_TXT_FILE
from 原始数据处理 import prepare_sst_data
sst_datasets, train_data, test_data = prepare_sst_data()
def get_dataset(sst_data, text_field, label_field):
fields = [("sentence", text_field), ("label", label_field)]
sentences = [d['sentence'] for d in sst_data]
labels = [d['label'] for d in sst_data]
examples = [data.Example.fromlist([text, label], fields) for text, label in zip(sentences, labels)]
return examples, fields
#定义构建Dataset所需的数据和标签的field
TEXT = data.Field(sequential=True, tokenize=split_words, lower=True, batch_first=True)
LABEL = data.Field(sequential=False, use_vocab=False)
#提取训练、验证、测试数据
train_examples, train_fields = get_dataset(train_data, TEXT, LABEL)
test_examples, test_fields = get_dataset(test_data, TEXT, LABEL)
# 构建Dataset数据集
train_dataset = data.Dataset(train_examples, train_fields)
test_dataset = data.Dataset(test_examples, test_fields)
print(f'train_dataset[0]:\nsentence={train_dataset[0].sentence}, label={train_dataset[0].label}')
#加载word2vector横型
vectors = Vectors(name=W2V_TXT_FILE)
#使用训练数据集构建词汇表
TEXT.build_vocab(train_dataset, vectors=vectors)
print(f'TEXT.vocab.vectors.shape={TEXT.vocab.vectors.shape}')dataloader.py
# -*- coding: utf-8 -*-
from torchtext.legacy.data import Iterator, BucketIterator
import warnings
from dataset import test_dataset,train_dataset
def get_dataloader(train_dataset, test_dataset, batch_size=128, device='cpu'):
train_iter, test_iter = Iterator.splits(
(train_dataset, test_dataset), # 构建数据集所需的数据集
batch_sizes=(batch_size, batch_size),
device=device,
shuffle=True,
repeat=False)
return train_iter, test_iter
#基于训练、验证、测试数据集生成dataloader
train_dataloader, test_dataloader = get_dataloader(train_dataset=train_dataset, test_dataset=test_dataset, batch_size=128, device='cpu')
print(f'len of train_dataloader={len(train_dataloader)}, len of testloader={len(test_dataloader)}')
for t in train_dataloader:
print(f'sentence={t.sentence}, sentence.shape={t.sentence.shape}')
print(f'label={t.label}, label.shape={t.label.shape}')
break
model.py
# -*- coding: utf-8 -*-
from torch import nn
import torch.nn.functional as F
import torch.optim as optim
from tqdm.notebook import tqdm
import torch
from dataset import TEXT
# word2vector预训练词向量
weight_matrix = TEXT.vocab.vectors
class LSTM(nn.Module):
def __init__(self, vocab_len=len(TEXT.vocab), embedding_size=100, hidden_size=128, output_dim=2, weight_matrix=weight_matrix):
super(LSTM, self).__init__()
self.word_embeddings = nn.Embedding(vocab_len, embedding_size)
#若使用预训练的词向量,需在此处指定预训练的权重
if weight_matrix is not None:
self.word_embeddings.weight.data.copy_(weight_matrix)
for p in self.word_embeddings.parameters():
p.requires_grad = False # 锁定embedding层参数,模型训练过程中不更新该层参数
self.lstm = nn.LSTM(input_size=embedding_size, hidden_size=hidden_size, num_layers=1, batch_first=True)
self.fc = nn.Linear(hidden_size, output_dim)
def forward(self, sentence):
embeds = self.word_embeddings(sentence) # shape = [batch_size, sentence_len, embedding_len] [128, 32, 50]
lstm_out = self.lstm(embeds)[0] # shape = [batch_size, sentence_len, hidden_size] [128, 32, 128]
final = lstm_out[:, -1, :] # 取最后一个时间步,shape = [batch_size, hidden_size]
y = self.fc(final) # 取最后一个时间步,shape = [batch_size, output_dim]
return y
# debuq codey
device = 'cpu' # or 'cpu'
lstm_model = LSTM().to(device)
print(lstm_model)
sentence = torch.ones(128, 32, device=device)
print(f'model input shape = {sentence.shape}')
label = lstm_model(sentence.long())
print(f'model output shape = {label.shape}')
torch.save(lstm_model.state_dict(), 'lstm_sst2.pt')
class GRUNet(nn.Module):
def __init__(self, vocab_size=len(TEXT.vocab), embedding_dim=100, hidden_dim=256, layer_dim=1, output_dim=2, weight_matrix=TEXT.vocab.vectors):
"""
vocab_size: 词典长度
embedding_dim: 词向量的维度
hidden_dim: GRU神经元个数
layer_dim: GRU的层数
output_dim: 隐藏层输出的维度(分类的数量)
weight_matrix: 编码参数矩阵
"""
super(GRUNet, self).__init__()
self.word_embeddings = nn.Embedding(vocab_size, embedding_dim)
if weight_matrix is not None:
self.word_embeddings.weight.data.copy_(weight_matrix) # 加预训练好的word2vector模型
for p in self.word_embeddings.parameters():
p.requires_grad = False
self.gru = nn.GRU(embedding_dim, hidden_dim, layer_dim, batch_first=True)
self.fc = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim * 5),
torch.nn.Dropout(0.5),
torch.nn.ReLU(),
nn.Linear(hidden_dim * 5, output_dim)
)
def forward(self, x):
embeds = self.word_embeddings(x)
r_out = self.gru(embeds, None)[0] # None表示初始的hidden state为0
# 选取最后一个时间点的out输出
out = self.fc(r_out[:, -1, :])
return out
# debuq codey
device = 'cpu' # or 'cpu'
gru_model = GRUNet().to(device)
print(gru_model)
sentence = torch.ones(128, 32, device=device)
print(f'model input shape = {sentence.shape}')
label = gru_model(sentence.long())
print(f'model output shape = {label.shape}')
torch.save(gru_model.state_dict(), 'gru_sst2.pt')train.py
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import torch
from IPython import display
from torch import optim, nn
from tqdm import tqdm
import predict
import model as md
from dataset import test_dataset,train_dataset
from dataloader import get_dataloader
class PrintLossAcc(object):
def __init__(self):
self.loss, self.acc, self.x_list = list(), list(), list()
def draw(self, epoch, loss, acc):
self.x_list.append(epoch)
self.loss.append(loss)
self.acc.append(acc)
display.clear_output(wait=True)
plt.plot(self.x_list, self.loss, label='loss')
plt.plot(self.x_list, self.acc, label='acc')
plt.xlabel('epoch')
plt.ylabel('%')
plt.grid(True)
plt.legend(loc='upper left')
plt.show()
#训练模型
def train_model(model, dataloader, device='cpu', epoches=10):
model.to(device)
# 使用Adam优化器只针对除embedding层之外的其他层进行参数调优
optimizer = optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=0.001)
loss_funtion = nn.CrossEntropyLoss() # 使用交叉熵损失函数
draw_pic = PrintLossAcc()
for epoch in range(epoches):
model.train()
epoch_loss, epoch_acc = 0, 0
for data in tqdm(dataloader, desc=f'train {epoch + 1}'):
optimizer.zero_grad()
predicted = model(data.sentence)
loss = loss_funtion(predicted, data.label)
predicted = torch.max(predicted, dim=1)
acc = (predicted.indices == data.label.long()).sum()
loss.backward()
optimizer.step()
epoch_loss += float(loss)
epoch_acc += float(acc / len(data.label.long()))
epoch_loss = round(epoch_loss / len(dataloader), 4)
epoch_acc = round(epoch_acc / len(dataloader), 4)
draw_pic.draw(int(epoch + 1), epoch_loss, epoch_acc)
print(f'epoch {epoch + 1} train_loss={epoch_loss}, train_acc={epoch_acc}')
device = 'cpu' # 设备类型或‘cuda’
epoches = 20 # 训练轮数
batch_size = 128
lstm_model = md.LSTM() # 参数使用默认参数
# # 加载数据集
train_dataloader, test_dataloader = get_dataloader(train_dataset=train_dataset, test_dataset=test_dataset, batch_size=batch_size, device=device)
# # 启动模型训练
# train_model(lstm_model, train_dataloader, epoches=epoches, device=device)
# # 保存横型
# torch.save(lstm_model.state_dict(), 'lstm_sst2.pt') # 保存模型,保存类型:“.pt”、“.pth”、“.pkl”
#训练GRU模型
gru_model = md.GRUNet()
# 加载数据集
#train_dataloader, test_dataloader = get_dataloader(train_dataset=train_dataset, test_dataset=test_dataset, batch_size=batch_size, device=device)
# 启动模型训练
train_model(gru_model, train_dataloader, epoches=epoches, device=device)
# 保存模型
torch.save(gru_model.state_dict(), 'gru_sst2.pt')结果图
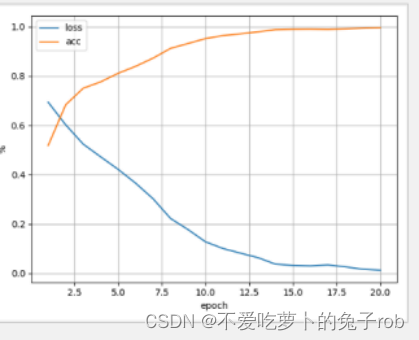
predict.py
# -*- coding: utf-8 -*-
import torch
import model as md
from Word2Vector import split_words
from dataset import TEXT
def predict_sentiment(net, vocab, sentence):
'''
@params:
net: 训练好的模型
vocab: 在该数据集上创建的词典,用于将给定的单词序转换为单词下标的序列,从而输入模型
sentence: 需要分析情感的文本
@return: 预测的结果,positive为正面情绪文本,negative为负面情绪文本
'''
sentence = split_words(sentence)
device = list(net.parameters())[0].device # 读取模型所在的环境
sentence = torch.tensor([vocab.stoi[word] for word in sentence], device=device)
label = torch.argmax(net(sentence.view((1,-1))), dim=1) # 这里输入之后,进入embedding,进入lstm, 进入全连接层, 输出结果
return 'positive' if label.item() == 1 else 'negative'
lstm_model = md.LSTM()
lstm_model.load_state_dict(torch.load('lstm_sst2.pt'))
gru_model = md.GRUNet()
gru_model.load_state_dict(torch.load('gru_sst2.pt'))
sentence = 'One of the greatest family-oriented , fantasy-adventure movies ever .'
print(f'LSTM模型预测结果: {predict_sentiment(lstm_model, TEXT.vocab, sentence)}')
print(f'GRU模型预测结果: {predict_sentiment(gru_model, TEXT.vocab, sentence)}')
数据集和训练好的模型文件















 8225
8225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









