







作者 | 夕颜
出品 | AI科技大本营(ID:rgznai100)
【导读】在刚刚结束的上海2019世界人工智能大会上,微软宣布了其在人工智能领域的最新研究突破——由微软亚洲研究院研发的麻将 AI 系统 Suphx 在国际知名的专业麻将平台“天凤”上荣升十段,创造了目前 AI 系统在麻将领域取得的最好成绩,实力媲美顶级人类选手。为进一步了解 Suphx,AI 科技大本营对微软亚洲研究院副院长刘铁岩和天凤平台开发公司 C-EGG CEO 角田真吾进行了采访。
微软AI研究新突破:麻将AI 系统实力媲美顶级人类选手
由微软亚洲研究院开发的麻将 AI 系统 Suphx(超级凤凰)成为首个在国际知名的专业麻将平台“天凤”上荣升十段的 AI 系统。
这个“十段”究竟是什么水平呢?
我们先来了解一下什么是天凤麻将。

天凤麻将是由日本游戏公司 C-EGG(シー·エッグ)开发的网络对战日本麻将游戏。该游戏属于竞技类游戏,游戏采用段级位制,用户在大厅内通过与他人的对战,可以提高或降低自己的游戏等级,当用户达到一定级别之后就可以到更高级别的阶段与他人对战。同时,用户也可以创建自己的个室或大会室,与认识的同好一起进行游戏。天凤麻将分为大厅、个室和大会室三个场所。
在大厅中,玩家可与其他玩家进行对战,在对战过程中获得或失去 pt 和 Rate 两种点数。大厅细分为一般、上级、特上、凤凰四个级别,必须满足该级别的条件才能在该级别内与其他玩家对战。
Suphx 在天凤的公开房间“特上房”与人类选手进行了超过 5000 场对战,获得“特上房”最高段位十段。
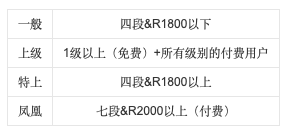
“天凤”平台因其完善的规则、专业的段位升级系统,吸引了全球近 33 万名麻将玩家,其中汇集了大量专业选手。Suphx 的风格自成一派,其稳定段位领先另外两个知名麻将 AI 系统 2 个段位以上,并且超越顶尖人类选手在该房间的平均水平 1 个段位以上。
为什么选择麻将游戏?
那么,在棋牌游戏 AI 盛行的今天,为什么微软会选择传统的麻将游戏作为研发重点呢?
对此,微软称,麻将起源于中国,而今这一蕴含东方哲学和智慧的古老博弈游戏正风靡全世界。与象棋、围棋等棋类相比,麻将在游戏对弈的过程中存在大量隐藏信息,具有高度的不确定性。与其他棋牌类游戏相比,刘铁岩将麻将形容为比其他棋牌类游戏更“AI”, 因为麻将本身并没有像其它类游戏那样通过控制键盘来决定出招快慢,它更多关注的是策略,把不必要的、人和机器的差别抹掉,体现的是智慧智能的作用。因此,麻将的复杂度远高于其他棋类,对 AI 技术存在着特殊挑战。
刘铁岩笑称,对于麻将,Suphx 的研发团队其实大部分人都不算麻将高手,最会打麻将的研究员都打不到一段。但就是这样一支团队,打造出了可以与人类专业选手相媲美的麻将 AI 系统。他们是怎么做到的?
背后的关键技术
加上今年 3 月份入驻“天凤”到 6 月拿下“十段”,微软在 Suphx 项目上的投入时间将近一年半。这段时间内,Suphx 在微软的系统训练下段位不断提升,背后依赖几项关键技术,如自适应决策、先知教练、全盘预测等都是对深度强化学习进行加强的新型人工智能技术,这些技术可以有效处理麻将的高度不确定性,在游戏中表现出类人的直觉、预测、推理、模糊决策能力,和大局观意识。
Suphx 的关键技术包括一项被称为先知教练的技术,它可以使用完美信息加速训练的过程,但是实际操作环境更多的还是非完美环境,这其中的 gap 如何过渡?
对此,刘铁岩给出了他的解释:“用完全信息指导训练是一个用来抵抗大量未知信息的手段,但是中间确实存在 gap,训练时我们可以有这样的先知教练,但在真正对打时是没有这样的信息的。这个先知教练起到了什么作用呢?当有大量隐藏状态存在时,深度强化学习非常不稳定,训练过程会受到干扰的影响,而且有多条不同的通路可以往前走,一些噪声就会出现漂移。我们经常讲强化学习的方差很大,这导致可能有时会做出一些失控的操作。先知教练的存在是规范麻将 AI 在学习过程中的路径,我们虽然不能保证控制住这个 gap,比如它能够看到不该看到的东西,事实上它是永远看不到的,这个信息的 gap 我们无法跨越,但是先知教练可以引导麻将 AI 不走偏走远,并沿着预想的大方向走,保证训练过程的平稳性,这对深度强化学习非常重要。”
但是关于 Suphx 训练系统、模型和算法等具体的细节,刘铁岩表示暂时不便透露,但总的来讲,他们仍然使用深度强化学习的大框架,在这个框架下与其他绝大部分的游戏 AI 走的是同一个技术路线,但是在大的技术路线中进行很多创新,以适应更难、更新的游戏,比如先知教练、自适应决策等手段都是弥补传统的技术框架和麻将 AI 等新游戏之间的技术鸿沟。
拓展到开放环境真的现实吗?
当然,和其他游戏 AI 一样,大家不免对 Suphx 也有一些拓展应用上的疑问,因为麻将毕竟是一个 4 人参与,牌数有限的游戏,它如何能拓展到金融交易、智慧交通等开放性的环境中呢?
对此,刘铁岩解释道,做基础研究时,研究人员在相对可控的环境里淬炼技术;当掌握技术之后,落地一定会有最后一公里的创新。虽然微软现在从 Suphx 中学到的技术还没有全部使用到实际应用中,但是有一部份应用已经在现实环境中进行了尝试,比如微软亚洲研究院在金融投资上,与华夏基金、太平资产等进行了大胆的实盘投资实验,取得了非常好的效果,在此过程中就使用了很多自适应决策技术。因为经济走势、成分和国家监管等均有所不同,离线训练的 AI 模式、在历史交易数据中训练的 AI 模型真正应用到市场上是不一样的,所以需要动态地适应场景并做出改变,这与 Suphx 里的自适应决策一脉相承。
Suphx或引入“凤凰房”,并与其他AI对打
目前为止,Suphx 在“天凤”中只是在与人类选手对打,角田真吾在交流会上表示,未来会考虑将 Suphx 引入更高阶的“凤凰房”中。但是出于“凤凰房”中对战的人数有限,引入 AI 将产生的影响还不确定,因此会慎重考虑这一做法会带来的影响,比如引入有大量 AI 进入,“凤凰房”可能就不是原来的“凤凰房”了。
至于是否会安排 Suphx 与其他 AI 对打,角田真吾表示他们其实已经有这样的想法,AI 科技大本营将继续对此保持关注。
未来改进方向
为了让 Suphx 更加成熟,微软将从哪些维度进一步推进呢?刘铁岩表示,麻将 AI 还有很多值得继续研究的方向,比如由于麻将游戏有大量的隐藏信息,所以传统的树搜索的方式很难应用,微软现在是以预测为主而不是搜索为主,这是 Suphx 团队的一个方向性认识。
从更大的维度来看,搜索算法和预测算法结合也是一个值得研究的技术焦点,这对解决很多实际问题都有帮助。
另外一个维度是微软关心 的 AI 的可解释性,Suphx 现在打比赛有着自己独特的风格,但究竟是什么样的风格微软自身并不清楚,刘铁岩表示这一方面是因为麻将 AI项目的研究员的麻将“修为”比较浅,无法像专业选手一样可以看懂Suphx的风格,另一方面也是因为这个技术路线本身含有大量参数,需要通过很复杂的训练产生,如何让 Suphx 的模型有自解释的能力,是微软下一步的重点。
最后,刘铁岩还提到 Suphx 最主要的训练收益是通过线下(将近 2000 万场)的自我博弈,数量远远超出线上数量(5000 场)。其中,线下自我博弈学到的信号数量很多,但是学到更多的是如何自我提升,但是 5000 场线上对弈中,系统可以学到别人的打法、风格和实战中解决问题的能力。这两类信号的作用各有千秋,而微软正在考虑如何将二者结合。这也是最近一段时间人工智能领域的新的研究热点,即从人类或有经验的玩家的行为中进行抽象与海量的自我博弈结合。
正如微软全球资深副总裁、微软亚太研发集团主席兼微软亚洲研究院院长洪小文所说:“游戏一直是人工智能研究的最佳试验田,训练游戏 AI 的过程可以不断提升人工智能的算法和人工智能处理复杂问题的能力。麻将 AI 系统 Suphx 的技术突破,对于探索及扩展人工智能算法的边界是非常有益的尝试。同时,麻将这类游戏中的推理、决策过程与人类真实且复杂的生活更贴近,我们希望通过对麻将 AI 系统的研究,提升人工智能在现实环境中解决复杂问题的能力,推动人工智能技术的发展。”
(*本文为AI科技大本营原创文章,转载请联系微信 1092722531)
◆
福利时刻
◆
入群参与每周抽奖~
扫码添加小助手,回复:大会,加入福利群,参与抽奖送礼!

距离大会参与通道关闭还有 3 天,扫描下方二维码或点击阅读原文,马上参与!(学生票特享 598 元,团购票每人立减优惠,倒计时 3 天!)

推荐阅读
AI换脸软件ZAO刷屏,可我却不敢用了
只给测试集不给训练集,要怎么做自己的物体检测器?
还在抱怨pandas运行速度慢?这几个方法会颠覆你的看法
没有光芯片,何谈 5G 与 AI !
30 岁的程序员,我没有活成理想的模样,失败吗?
看懂“大数据”,这一篇就够了!
别让分析公司卖了你:一文读懂比特币的私密性及隐私保护

你点的每个“在看”,我都认真当成了喜欢














 7172
7172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









